






前言
如果你想要用 Python 进行数据分析,就需要在项目初期开始进行探索性的数据分析,这样方便你对数据有一定的了解。其中最直观的就是采用数据可视化技术,这样,数据不仅一目了然,而且更容易被解读。
常用的 10 种视图,这些视图包括:
散点图、折线图、直方图、条形图、箱线图、饼图、热力图、蜘蛛图、二元变量分布和成对关系。
折线图
折线图是以折线的上升或下降来表示统计数量的增减变化的统计图,可以显示随时间(根据常用比例设置)而变化的连续数据,因此非常适用于显示在相等时间间隔下数据的趋势。折线图也是最常用和最基础的可视化图形,足以满足我们日常 80% 的需求。
我们以2001-2019年劳动力与就业人员数据为例
折线图函数
| 参数 | 作用 |
| x | X轴数据,传入参数值时不要写参数名x |
| y | Y轴数据,传入参数值时不要写参数名y |
| color | 图形颜色,接收颜色英文名、颜色英文名首字母、十六进制颜色代码等 |
| linestyle | linestyle 线条样式,’-’是实线,’--’是虚线,… |
| marker | 点的样式,’*’是星号,’o’是圆点,… 点的样式,’*’是星号,’o’是圆点,… |
| format_string | 可以通过一串字符控制图形样式,如’r--o’表示红色、虚线、圆 |
折线图
plt.figure(figsize=(12,6),dpi=1080)
plt.xlabel('年份(年)')
plt.ylabel('劳动力人数(万人)')
plt.xticks(range(2001,2020,1),labels=values[:,0])
plt.title('2002-2019年劳动力人数折线图 ')
plt.plot(values[:,0],values[:,3],linestyle='-',c='m',alpha=0.8,marker='D')
plt.plot(values[:,0],values[:,4],linestyle='--',c='m',alpha=0.5,marker='D')
plt.legend(['城镇就业人口','乡村就业人口'])
plt.show()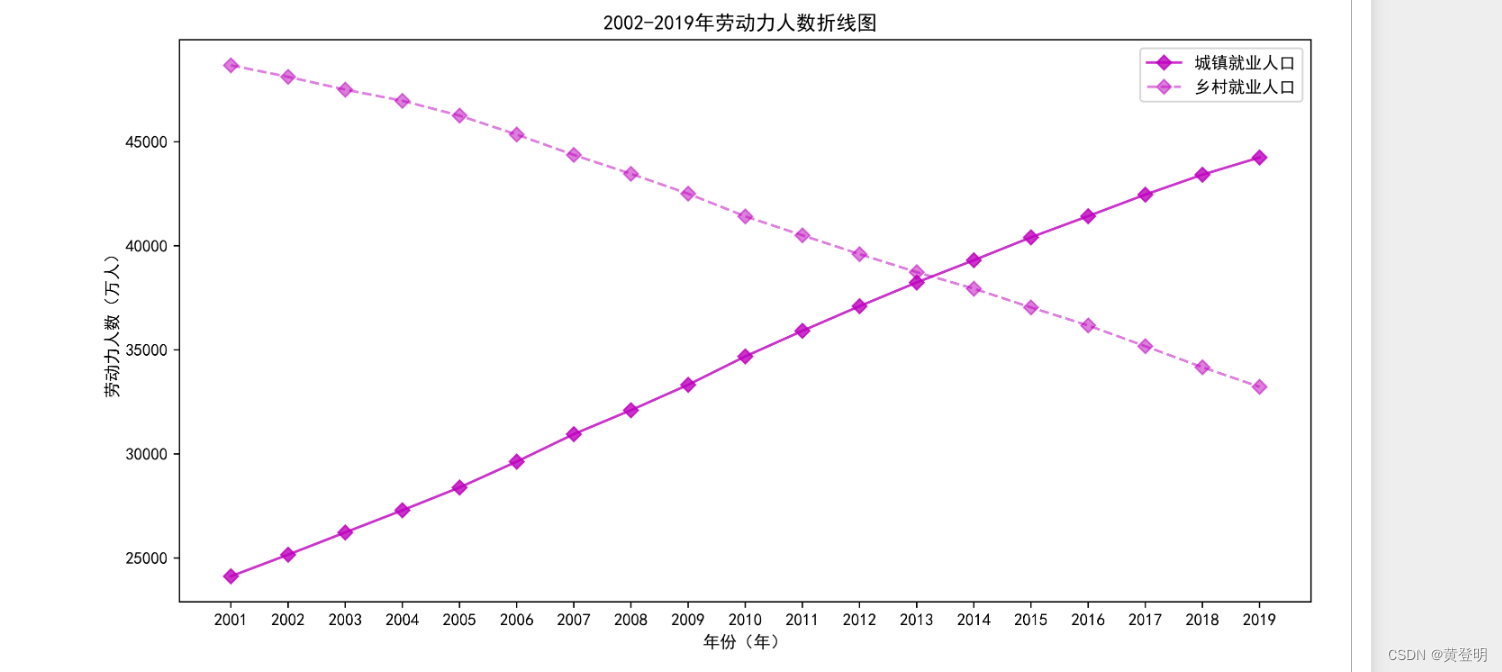
散点图
散点图是以直角坐标系中各点的密集程度和变化趋势来表示两种现象间的相关关系,常用于显示和比较数值。当要在不考虑时间的情况下比较大量数据点时,使用散点图比较数据方便直观。散点图将序列显示为一组点,其中每个散点值都由该点在图表中的坐标位置表示。对于不同类别的点,则由图表中不同形状或颜色的标记符表示。同时,也可以设置标记符的颜色或大小。
散点图的英文叫做 scatter plot,它将两个变量的值显示在二维坐标中,非常适合展示两个变量之间的关系。
散点图函数:
| 参数 | 作用 |
| X | X轴数据,传入一个列表序列类型数据 |
| Y | Y轴数据,传入一个列表序列类型数据 |
| S | 点标记的大小 |
| C | 点标记的颜色 |
| marker | 点的样式,’*’是星号,’o’是圆点,… |
获取数据标签
columns=data['arr_0']取出数据持会画图
values=data['arr_1']plt.figure(figsize=(12,6),dpi-1080)
plt.xlabel('年份(年)')
plt.ylabel('劳动力人数(人)')
plt.xticks(range(2001,2020,1),labels=values[:,0])
plt.title('2002-2019年劳动力人数散点图)
plt.scatter(values[:,0|,values[:,3],marker='o',c='m',alpha=0.5)
plt.scatter(values[:,0],values[:,4],marker='p',c='y',alpha=0.8)
plt.legend(['城镇就业人口’,"多村就业人口'])
plt.show()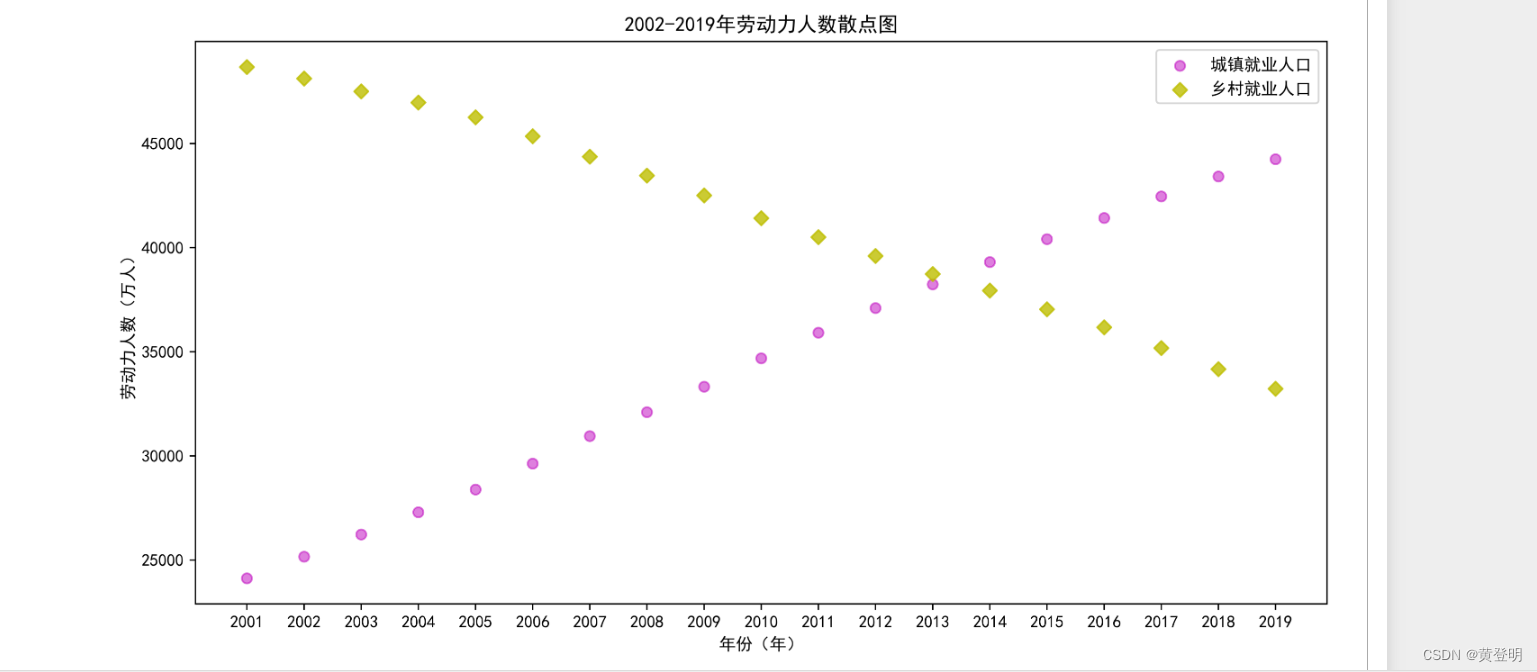
条形图
条形图,又称长条图、柱状统计图、条图、条状图、棒形图,是一种以长方形的长度为变量的统计图表。长条图用来比较两个或以上的价值(不同时间或者不同条件),只有一个变量,通常利用于较小的数据集分析。长条图亦可横向排列,或用多维方式表达。
labels = ['城镇就业人员','乡村就业人员']
plt.figure(figsize=(12,6),dpi=1080)
plt.xlabel('类别')
plt.ylabel('人数(万人)')
plt.xticks(range(2),labels)
plt.title('2019城乡就业人口柱状图')
bar1=plt.bar(range(2),values[-1,3:5],width=0.7,color=['r','b'],alpha=0.4) #bar竖着
plt.bar_label(bar1)
plt.show()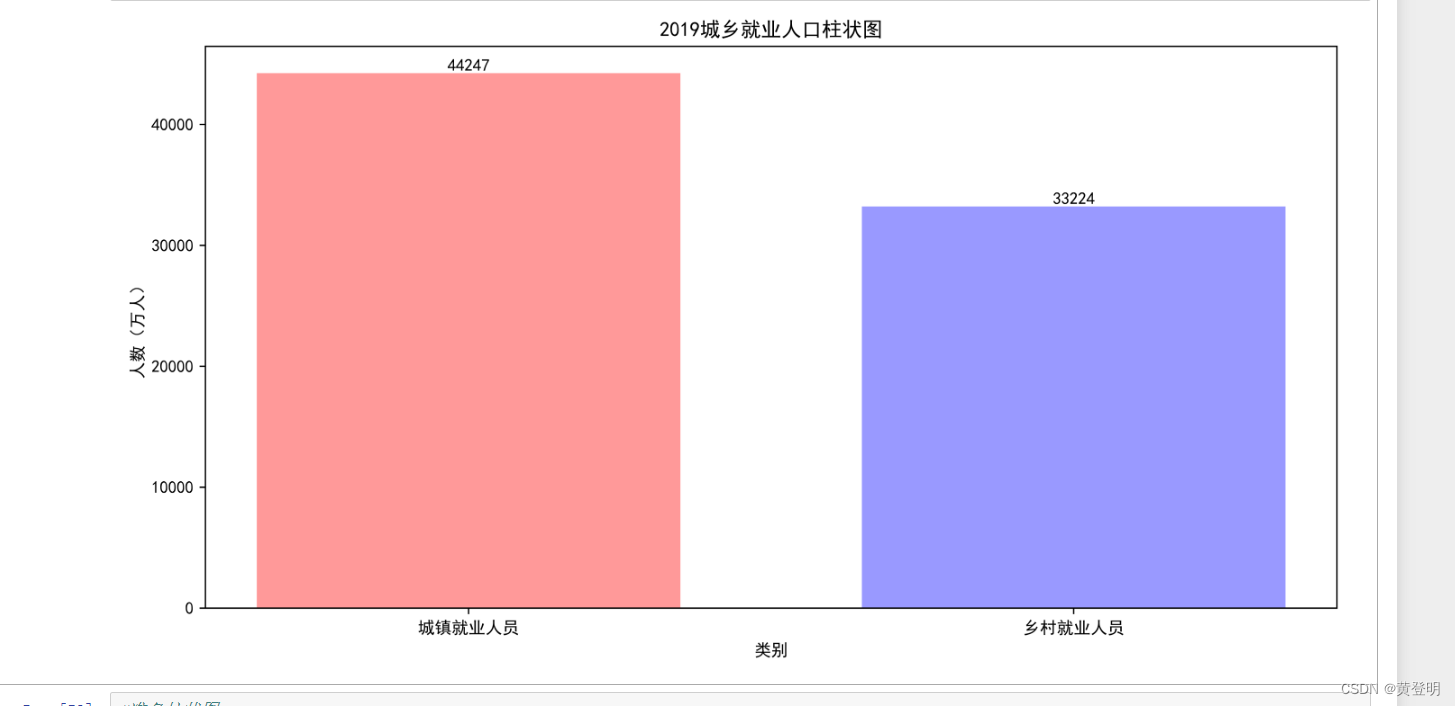
饼图
饼图是一种常见的统计图表,用来表示每个分类所占比例。它是一种分开圆形,再把它们分成不同大小和形状的片段,表示不同分类处于整体中所占的比例,可以直观地反映变量之间的关系。同时也有扇形图,也即用扇形的面积来模拟数据的大小。
饼图函数:
| 参数 | 作用 |
| x | 接收列表,里面是各个数据的值 |
| labels | 接收列表,里面是各个数据的标签 |
| radius | 接收数字,表示饼图的半径,默认是1 |
| autopc t | 接收字符串’%%1.xf%’,表示饼图中显示百分比数并保留一位小数。 |
labels = ['城镇就业人员','乡村就业人员']
explode=[0.01,0.01]
plt.figure(figsize=(6,6),dpi=100)
plt.pie(values[-1,3:5],explode=explode,labels=labels,autopct='%1.1f%%',startangle=90,colors=['r','m'],shadow=True,radius=0.5)#startangle偏离角度,radius图大小
plt.title('2019年城乡就业人数分布饼图')
plt.savefig('C:/Users/admin/Desktop/234.jpg')
plt.show()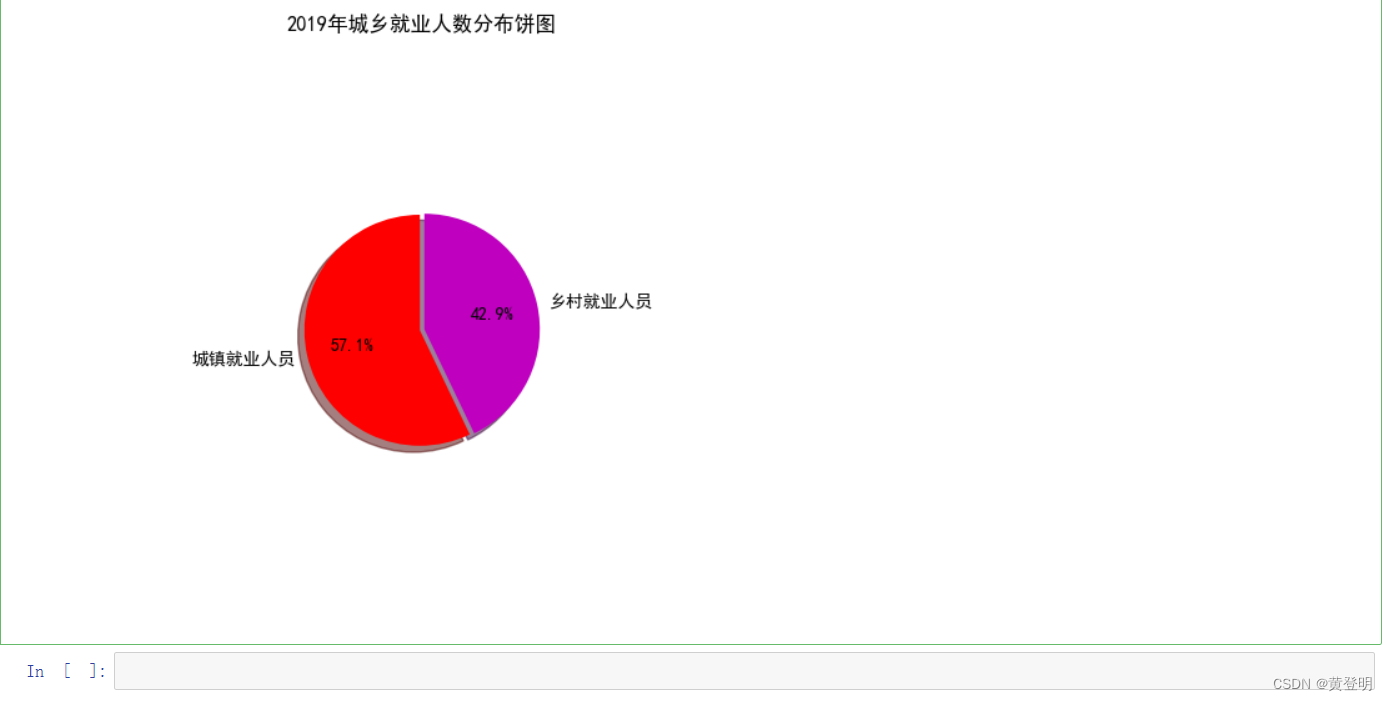
热力图
热力图(Heat Map)是一种基于色彩对数据集进行可视化的方法,可表现出数据空间内各点之间的相关性,从而揭示影响结果的因素的变化趋势。
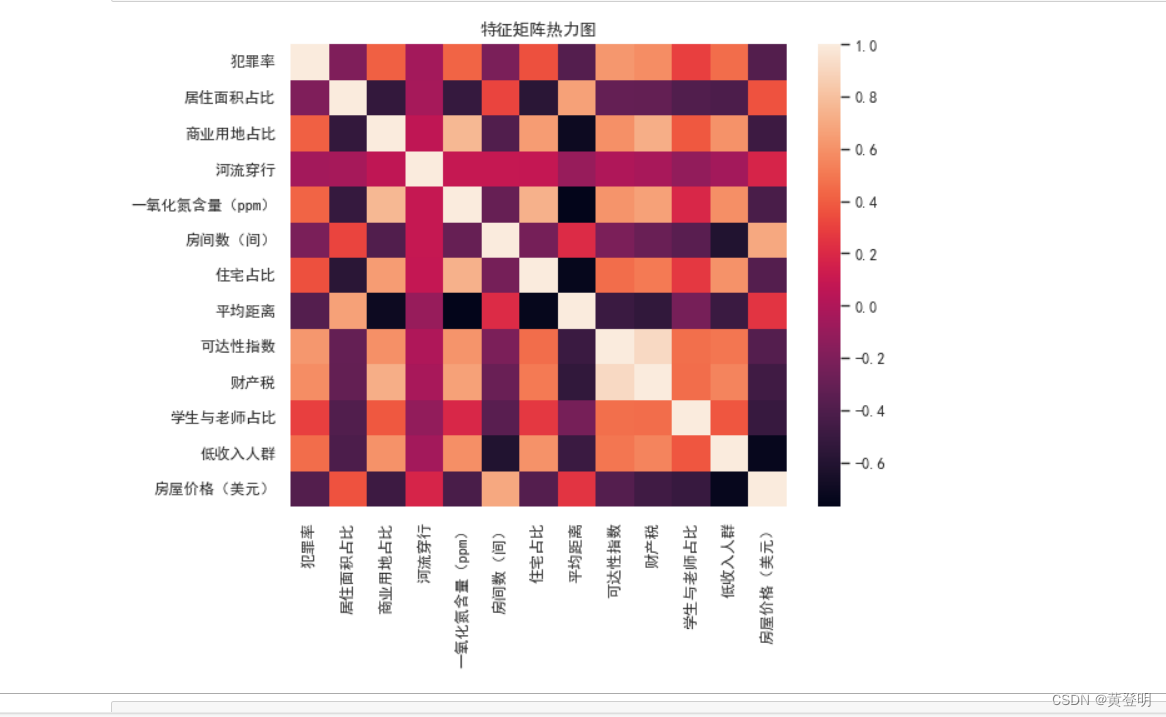
进阶
以hr.csv表为例

用matplotlib画
散点图,x是每个月平均工作市场(小时),y取满意度水平,颜色(显示薪资水平)
先设定,薪资水平用不同的颜色来显示(先取出薪资的取值情况,跟颜色对应,打包,然后转成字典)
color_map=dict(zip(data1['薪资'].unique(),['b','y','r']))
#写一个for循环,针对薪资水平分组的情况,分别画出散点图在图上
for species,group in data1.groupby('薪资'):
plt.scatter(group['每月平均工作小时数(小时)'],#x
group['满意度'], #y
color=color_map[species], #颜色所属的类别
alpha=0.4, #颜色透明度
edgecolors=None, #设置没有边框
label=species) #设置标签就是对应薪资组别
plt.legend(frameon=True,title='薪资') #设置图例,让图例有框,标题是薪资
plt.xlabel('每月平均工作小时数(小时)')
plt.ylabel('满意度')
plt.title('满意度水平与每个月平均工作市场的关系(按薪资水平分)')
plt.show()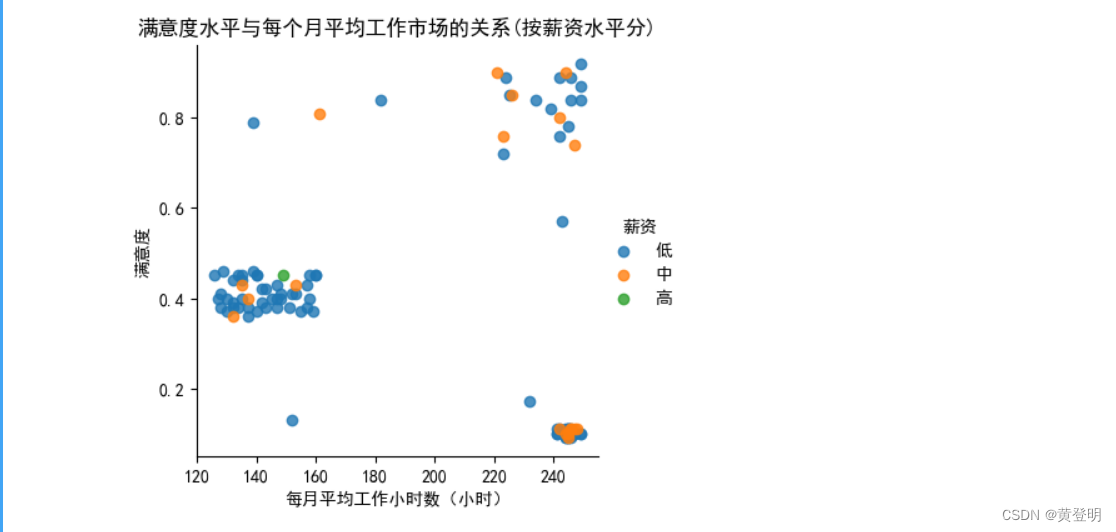
用seaborn库绘图
sns.set_style('darkgrid')
sns.set_context('paper')
sns.set_style({'font.sans-serif':['SimHei','Arial']})
sns.lmplot(data1,x='每月平均工作小时数(小时)',y='满意度',hue='薪资',fit_reg=False,height=4)
plt.xlabel('每月平均工作小时数(小时)')
plt.ylabel('满意度')
plt.title('满意度水平与每个月平均工作市场的关系(按薪资水平分)')
plt.show()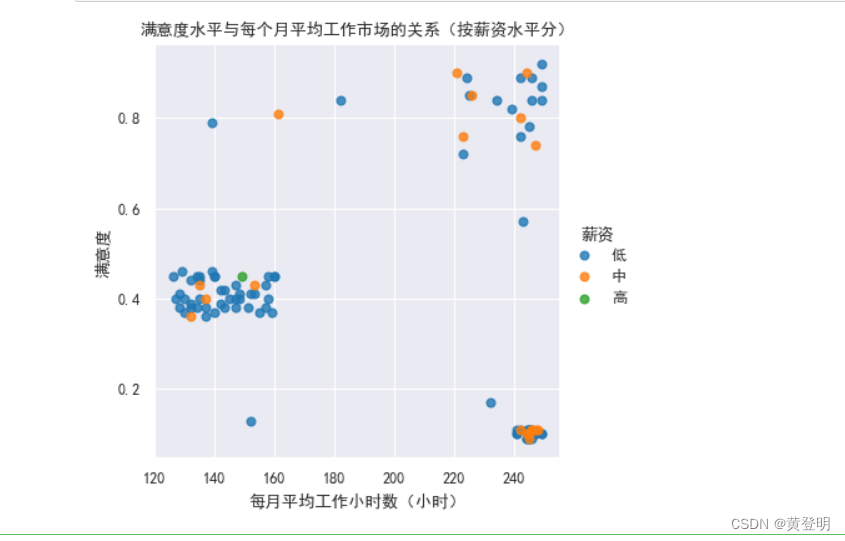
设置边框
sns.set_style('darkgrid')
sns.set_context('paper')
sns.despine(offset=10,left=False,bottom=False)
sns.set_style({'font.sans-serif':['SimHei','Arial']})
sns.lmplot(data1,x='每月平均工作小时数(小时)',y='满意度',hue='薪资',fit_reg=False,height=4)
plt.xlabel('每月平均工作小时数(小时)')
plt.ylabel('满意度')
plt.title('满意度水平与每个月平均工作市场的关系(按薪资水平分)')
plt.show()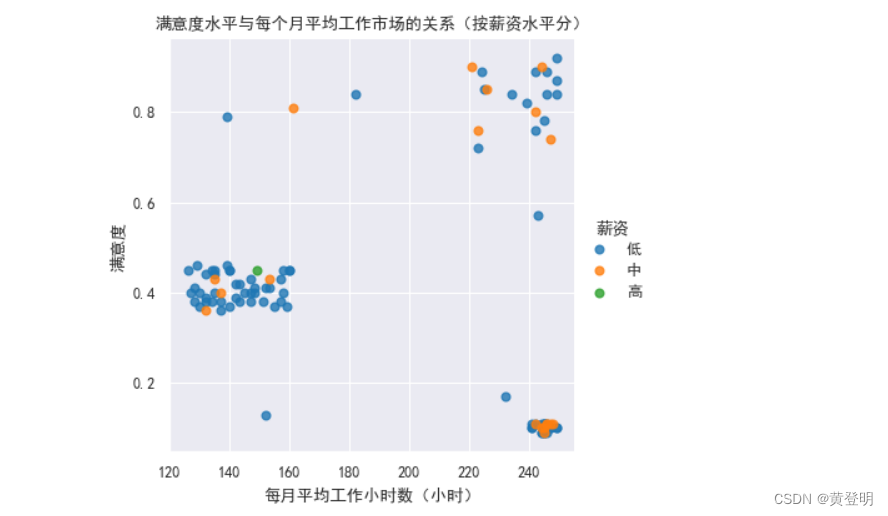
调色
sns.set_style('white')
sns.set_context('paper')
sns.set_palette('Set2')
sns.set_style({'font.sans-serif':['SimHei','Arial']})
sns.lmplot(data1,x='每月平均工作小时数(小时)',y='满意度',hue='薪资',fit_reg=False,height=4)
plt.xlabel('每月平均工作小时数(小时)')
plt.ylabel('满意度')
plt.title('满意度水平与每个月平均工作市场的关系(按薪资水平分)')
plt.show()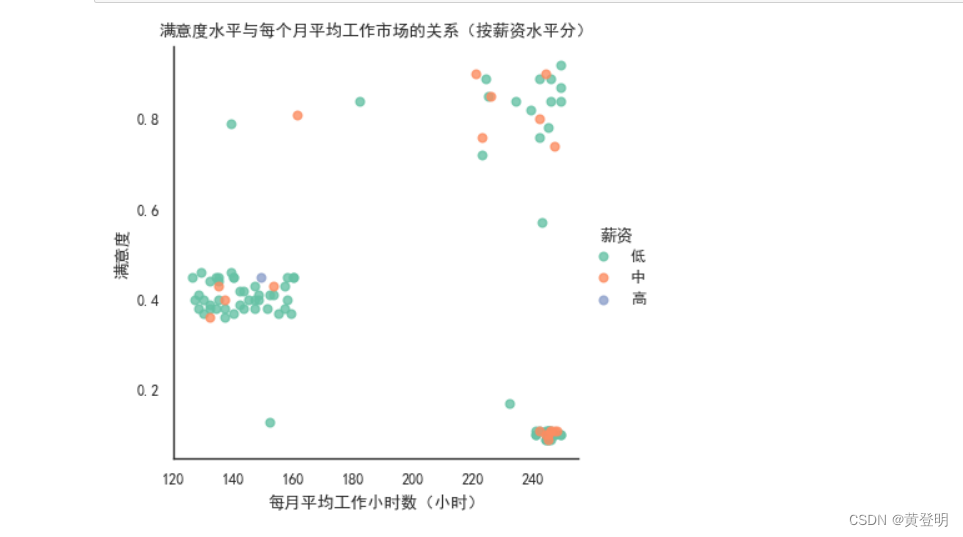
画简单的水平分类散点图
#准备数据画水平分类散点图
#部门是销售部,离职是1的数据
sale=data.loc[(data['部门']=='销售部')&(data['离职']==1),:]
sale['离职'].value_counts() #通过数据查询检查有没有筛选成功
sns.set_style('darkgrid')
sns.set_style({'font.sans-serif':['SimHei','Arial']})
sns.stripplot(x=sale['每月平均工作小时数(小时)'])
plt.title('简单的水平分类散点图')
plt.show()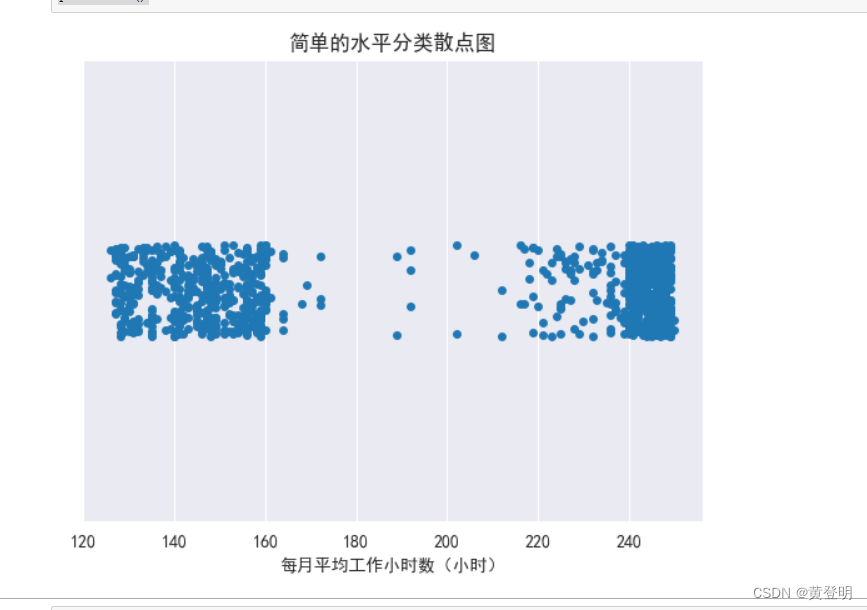
切片,筛选离职员工
data1=data.loc[data['离职']==1,:]
sns.set_style('darkgrid')
sns.set_style({'font.sans-serif':['SimHei','Arial']})
sns.stripplot(x=data1['部门'],y=data1['每月平均工作小时数(小时)'],s=2)
plt.title('简单的水平分类散点图')
plt.show()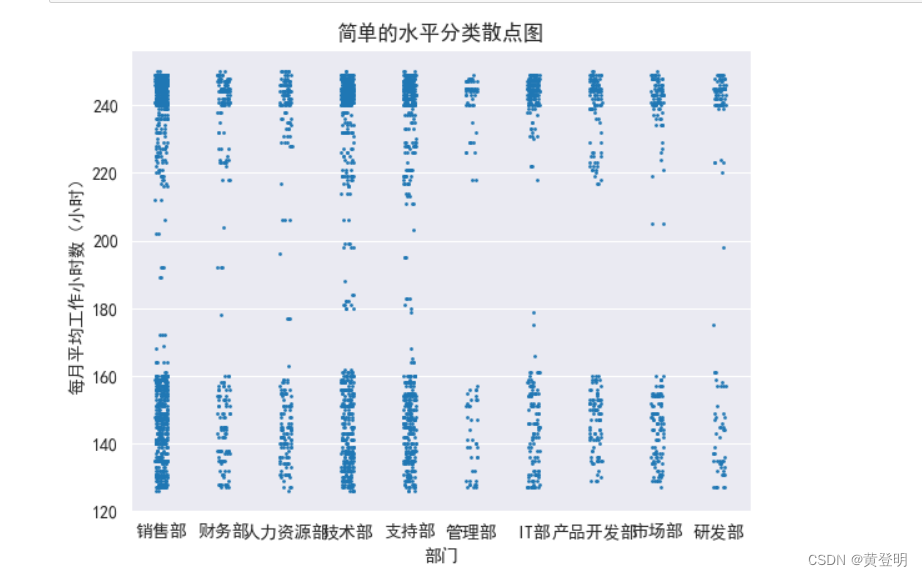
无噪音图
data1=data.loc[data['离职']==1,:]
sns.set_style('darkgrid')
sns.set_style({'font.sans-serif':['SimHei','Arial']})
sns.stripplot(x=data1['部门'],y=data1['每月平均工作小时数(小时)'],s=2,jitter=False)
plt.title('无噪音图')
plt.show()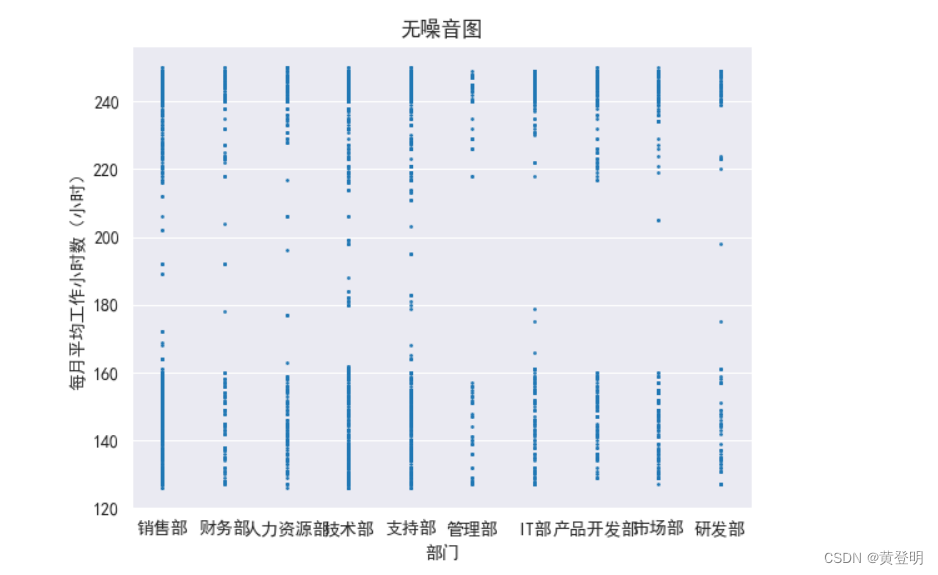
绘制不会有重叠的分类散点图
sns.set_style('darkgrid')
sns.set_style({'font.sans-serif':['SimHei','Arial']})
sns.swarmplot(x=data1['部门'],y=data1['每月平均工作小时数(小时)'],s=0.5,hue=data1['总项目数'])
plt.show()
回归拟合图
读取数据
boston=pd.read_csv('C:/Users/admin/Desktop/boston_house_prices.csv',encoding='gbk')
boston.head(2)画散点回归线
fig=plt.figure(figsize=(8,4),dpi=100)
ax1=fig.add_subplot(1,2,1)
sns.regplot(x=boston['房间数(间)'],y=boston['房屋价格(美元)'])
ax2=fig.add_subplot(1,2,2)
sns.regplot(x=boston['房间数(间)'],y=boston['房屋价格(美元)'],ci=50) #ci参数设置的是y轴的置信区间大小,默认是95,现在改为50
plt.show()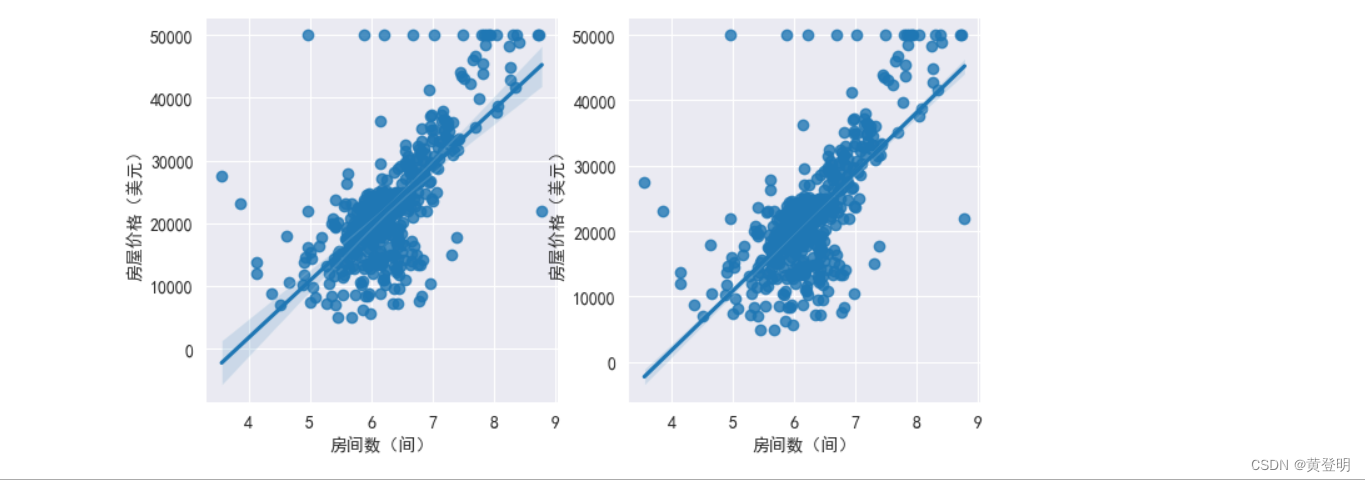















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









