






随机变量及其分布
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as st
def norm_p(a, b):
# 定义x的范围
x = np.arange(-4, 4, 0.1)
y = st.norm.pdf(x)
# 计算区间[a, b]内的x和y值
mask = (a <= x) & (x <= b)
x1 = x[mask]
y1 = y[mask]
# 计算累积概率p
p = st.norm.cdf(b) - st.norm.cdf(a)
print("N(0,1)分布: [{:.2f},{:.2f}] p={:.4f}".format(a, b, p))
# 绘制图形
plt.figure(figsize=(10, 6))
plt.plot(x, y, label='Standard Normal Distribution PDF')
plt.fill_between(x1, y1, color='skyblue', alpha=0.5, label=f'Area between {a} and {b}')
plt.hlines(0, -4, 4, colors='black', linestyles='dashed')
plt.vlines([a, b], 0, [st.norm.pdf(a), st.norm.pdf(b)], colors='red', linestyle='--')
# 添加标题和标签
plt.title('Standard Normal Distribution Probability Density Function')
plt.xlabel('x')
plt.ylabel('Probability Density')
plt.legend()
# 显示图形
plt.grid(True)
plt.show()
# 示例调用
norm_p(-1, 1)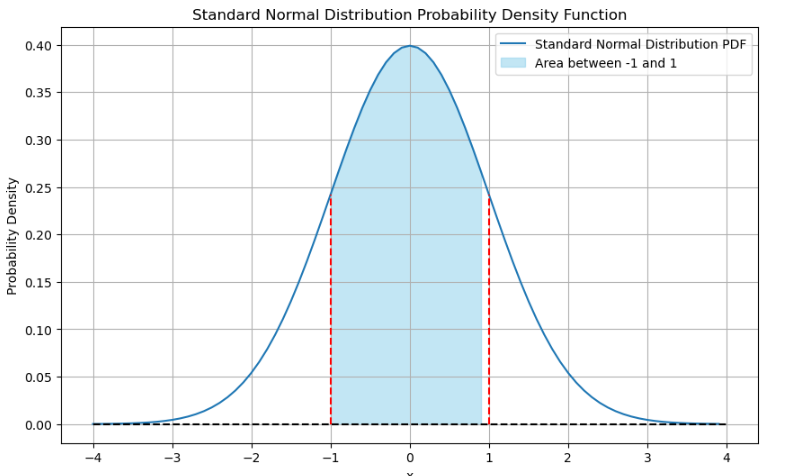
norm_p(-4,-2) # p=P(z≤2)=0.27%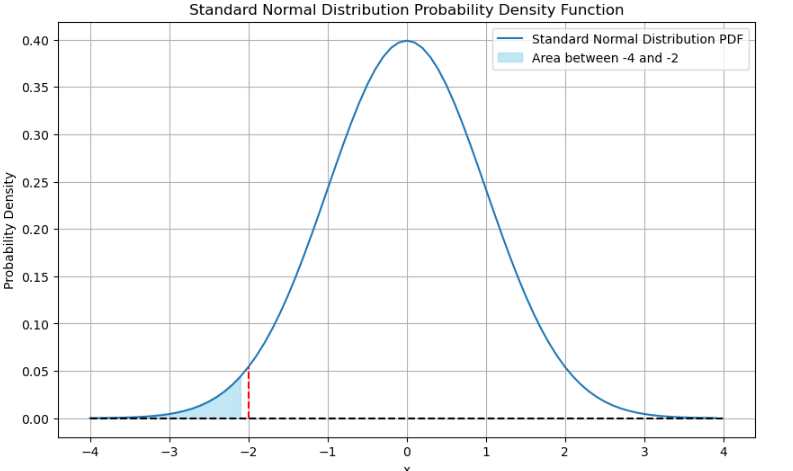
norm_p(-2,2) # p=P(-2≤z≤2)=95.45%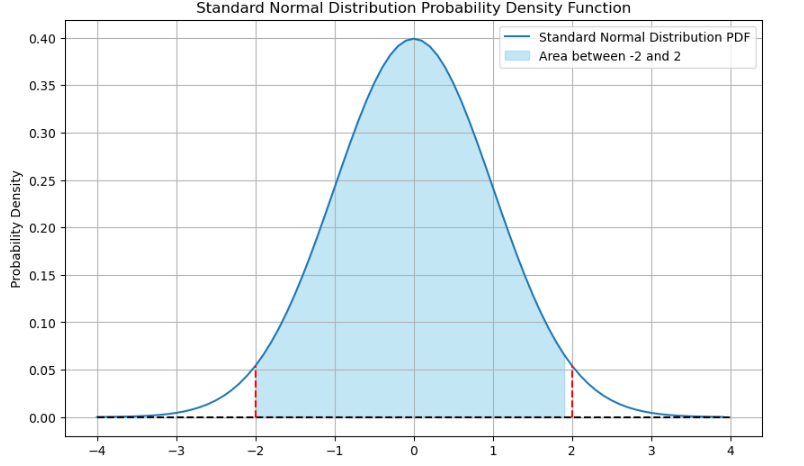
norm_p(-1.96,1.96) # p=P(-1.96≤z≤1.96)=95% 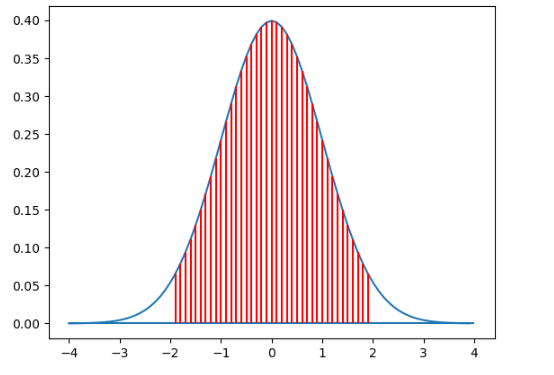
# 基于正态分布的中心极限定理模拟函数
import seaborn as sns
def norm_sim1(N=1000,n=10): # n为样本个数,N为模拟次数(即抽样次数)
xbar=np.zeros(N) # 产生放置样本均值的向量
for i in range(N): # 计算[0,1]上的标准正态随机数及均值
xbar[i]=np.random.normal(0,1,n).mean()
sns.distplot(xbar,bins=50) #plt.hist(xbar,bins=50)
print(pd.DataFrame(xbar).describe().T) #模拟结果的基本统计量
np.random.seed(1) #设置种子数seed使结果可重复
norm_sim1(10000,30) #根据默认值模拟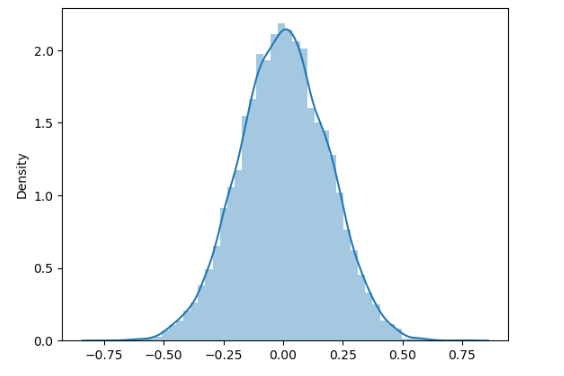
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
def norm_sim1(N=1000, n=10): # n为样本个数,N为模拟次数(即抽样次数)
xbar = np.zeros(N) # 产生放置样本均值的向量
for i in range(N): # 计算[0,1]上的标准正态随机数及均值
xbar[i] = np.random.normal(0, 1, n).mean()
# 使用seaborn的histplot代替已弃用的distplot
sns.histplot(xbar, bins=50, kde=True)
# 添加标题和标签
plt.title('Distribution of Sample Means')
plt.xlabel('Sample Mean')
plt.ylabel('Frequency')
# 显示图形
plt.show()
# 打印模拟结果的基本统计量
print(pd.DataFrame(xbar, columns=['Sample Mean']).describe().T)
# 示例调用
np.random.seed(1) #设置种子数seed使结果可重复
norm_sim1(10000,30) #根据默认值模拟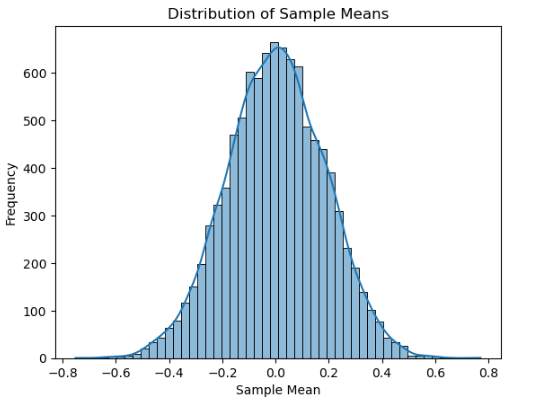
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
def norm_sim2(N=1000, n=10):
xbar = np.zeros(N)
for i in range(N): # 计算[0,1]上的均匀随机数及均值
xbar[i] = np.random.uniform(0, 1, n).mean()
# 使用seaborn的histplot代替已弃用的distplot
sns.histplot(xbar, bins=50, kde=True)
# 添加标题和标签
plt.title('Distribution of Sample Means (Uniform Distribution)')
plt.xlabel('Sample Mean')
plt.ylabel('Frequency')
# 显示图形
plt.show()
# 打印模拟结果的基本统计量
print(pd.DataFrame(xbar, columns=['Sample Mean']).describe().T)
# 示例调用
np.random.seed(3) #设置种子数seed使结果可重复
norm_sim2() 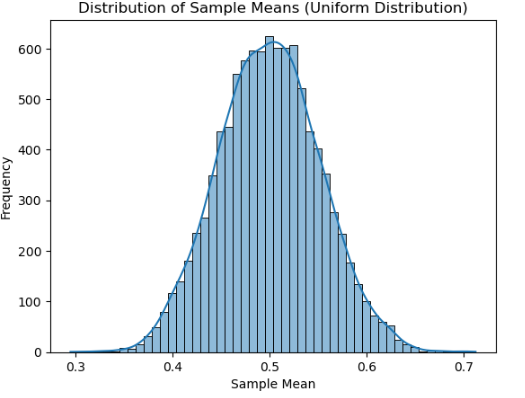
均值的 t 分布及其图示
x = np.arange(-4,4,0.1)
yn = st.norm.pdf(x,0,1)
yt3 = st.t.pdf(x, 3)
yt10 = st.t.pdf(x, 10)
plt.plot(x, yn, 'r-', x,yt3,'b.',x,yt10,'g-.')
plt.legend(["N(0, 1)", "t(3)", "t(10)"])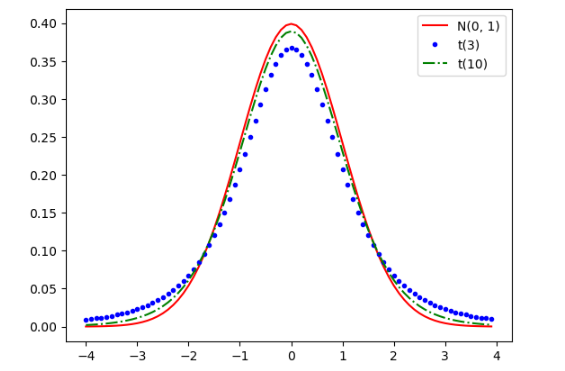
# 定义t分布曲线下[a, b]上计算概率的面积图
import scipy.stats as st
def t_p(a,b,df=10): #t分布曲线下[a,b]上计算概率的面积图
x=np.arange(-4,4,0.1)
y=st.t.pdf(x,df)
x1=x[(a<=x) & (x<=b)];x1
y1=y[(a<=x) & (x<=b)];y1
p=st.t.cdf(b,df)-st.t.cdf(a,df);
print(" t("+str(df)+"): [%3.2f, %3.2f] p=%5.4f"%(a,b,p))
plt.plot(x,y);#plt.text(-0.7,0.2,"p=%5.4f"%p,fontsize=15);
plt.hlines(0,-4,4); plt.vlines(x1,0,y1,colors='r');
t_p(-2,2) #t:[-2,2], df=10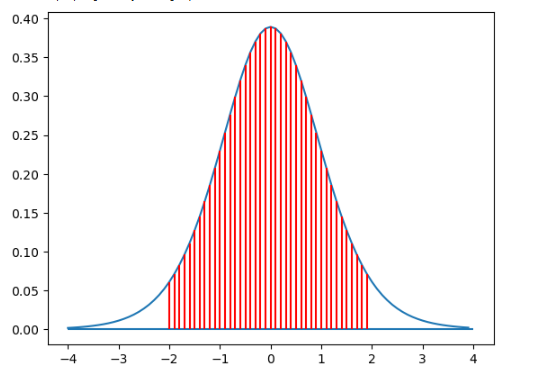
- 正态分布概率计算与可视化:
norm_p函数借助scipy.stats.norm模块,精准计算标准正态分布在指定区间[a, b]内的累积概率。同时,运用matplotlib库将该区间下概率密度函数的区域进行填充绘制,使正态分布的概率分布直观地呈现出来。 - 中心极限定理模拟:
norm_sim1函数针对标准正态分布进行抽样模拟,norm_sim2函数则对均匀分布[0, 1]进行抽样模拟。它们通过循环多次抽样计算样本均值,并使用seaborn的histplot函数绘制样本均值的分布直方图,同时打印出基本统计量,以此验证中心极限定理。 - t 分布的可视化与概率计算:绘制了标准正态分布以及自由度为 3 和 10 的 t 分布的概率密度函数曲线,直观展示它们之间的差异。
t_p函数能够计算 t 分布在指定区间[a, b]内的累积概率,并通过绘制垂直线段展示该区间下的概率分布情况。
实验心得
通过本次实验,我对随机变量及其分布有了更深刻、更全面的认识,以下是详细的心得体会:
1. 正态分布的深入理解
在使用 norm_p 函数时,我切实体会到了正态分布的魅力。正态分布作为统计学中最基础、最重要的分布之一,其对称性和集中性在可视化图形中一目了然。当我改变区间 [a, b] 的取值时,概率值的变化清晰地反映出正态分布的特性。这不仅让我对理论知识有了更直观的感受,还让我明白在实际生活中,许多自然现象和社会现象都近似服从正态分布。例如,学生的考试成绩、产品的质量指标等,这使得正态分布在数据分析、质量控制等领域有着广泛的应用。同时,通过代码实现概率计算和图形绘制,我也掌握了使用 Python 进行统计分析和可视化的基本方法,提高了自己的编程能力。
2. 中心极限定理的深刻验证
中心极限定理是统计学中的核心定理之一,它表明无论总体分布如何,只要样本量足够大,样本均值的分布就会近似服从正态分布。通过 norm_sim1 和 norm_sim2 函数的模拟实验,我亲眼见证了这一神奇的现象。从标准正态分布和均匀分布中抽样,随着样本量的不断增加,样本均值的分布逐渐趋近于正态分布,这让我对中心极限定理有了更深刻的理解。在实际应用中,中心极限定理为我们进行抽样调查和统计推断提供了坚实的理论基础。例如,在市场调研中,我们可以通过抽取少量样本的均值来推断总体的均值,大大提高了调查效率和准确性。此外,在实验过程中,我还学会了如何使用循环结构和随机数生成函数来模拟抽样过程,进一步提升了自己的编程技巧。
3. t 分布的特性认识
通过绘制标准正态分布和不同自由度的 t 分布曲线,我清晰地观察到了 t 分布的特点。当自由度较小时,t 分布的尾部比正态分布更厚,这意味着 t 分布在极端值处的概率更大。而随着自由度的增加,t 分布逐渐趋近于正态分布。在使用 t_p 函数计算 t 分布在指定区间内的概率时,我了解到 t 分布在小样本情况下的重要性。在实际应用中,当总体标准差未知且样本量较小时,我们通常使用 t 分布来构建置信区间和进行假设检验。这让我认识到不同的分布在不同的场景下有着不同的应用,我们需要根据实际情况选择合适的分布进行分析。同时,通过代码实现 t 分布的概率计算和图形绘制,我也进一步熟悉了 scipy.stats 模块的使用。
4. 编程能力的提升
在整个实验过程中,我对 Python 编程有了更深入的掌握。使用 numpy 进行数组操作和随机数生成,使用 matplotlib 和 seaborn 进行数据可视化,使用 scipy.stats 进行概率计算和分布函数的调用,这些库的使用让我感受到了 Python 在数据分析和统计领域的强大功能。同时,我也学会了如何将统计学知识与编程结合起来,通过编写代码来解决实际问题。例如,在实现中心极限定理的模拟实验时,我需要运用循环结构、条件判断和函数定义等编程技巧,这不仅提高了我的编程能力,还让我学会了如何将复杂的问题分解为简单的步骤来解决。此外,我还学会了如何对代码进行调试和优化,提高代码的运行效率和可读性。
5. 实验方法的反思与改进
虽然本次实验取得了预期的效果,但我也意识到了一些不足之处。首先,代码的注释可以更加详细,特别是对于一些关键步骤和函数的解释,这样可以让其他读者更容易理解代码的含义和实现思路。其次,实验内容可以进一步扩展,例如可以模拟更多不同类型的分布,观察它们在中心极限定理下的表现;或者改变样本量和模拟次数,深入研究它们对结果的影响。在可视化方面,我可以尝试使用更高级的绘图技巧,如添加子图、调整颜色和线条样式等,使图形更加美观和清晰。此外,我还可以将实验结果进行更深入的分析和总结,例如计算不同分布下样本均值的方差和标准差,比较它们与理论值的差异,从而更好地验证理论知识。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









