






# 定义模拟直线回归函数
import statsmodels.api as sm #加载统计模型包
def reglinedemo(n=20): #模拟样本例数
x=np.arange(n)+1 #自变量取值
e=np.random.normal(0,1,n) #误差项
y=2+0.5*x+e #因变量值
x1=sm.add_constant(x)
x1 #加常数项
fm=sm.OLS(y,x1).fit()
fm #模型拟合,见下
plt.plot(x,y,'.',x,fm.fittedvalues,'r-') #添加回归线,红色
for i in range(len(x)): #画垂直线
plt.vlines(x,y,fm.fittedvalues,linestyles='dotted',colors='b')
np.random.seed(12)
reglinedemo(20)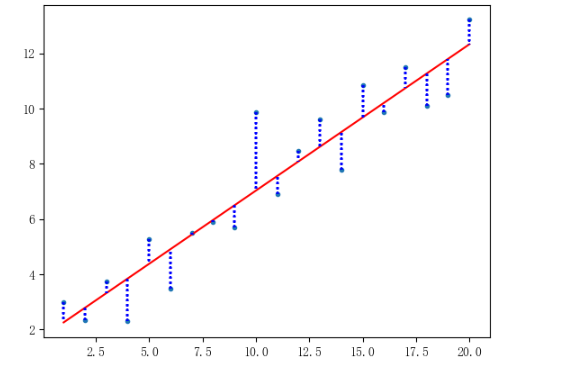
这段代码定义了 `reglinedemo` 函数用于模拟直线回归。它先生成自变量 `x`、误差项 `e` 和因变量 `y`,再用 `sm.OLS` 拟合回归模型。代码绘制样本点、红色回归线,以及从样本点到回归线的蓝色垂直线。不过原代码缺少必要的库导入,且 `plt.vlines` 调用有误。修正后补全了 `numpy`、`statsmodels.api` 和 `matplotlib.pyplot` 的导入,调整 `plt.vlines` 使其正确绘制垂直线。最后设置随机种子保证结果可复现,调用函数模拟 20 个样本点进行分析绘图。
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
# 定义模拟直线回归函数
def reglinedemo(n=20):
x = np.arange(n) + 1 # 自变量取值,从1到n
e = np.random.normal(0, 1, n) # 误差项,服从标准正态分布
y = 2 + 0.5 * x + e # 因变量值,包含截距和斜率以及误差
x1 = sm.add_constant(x) # 在自变量矩阵中添加常数项(截距)
fm = sm.OLS(y, x1).fit() # 使用普通最小二乘法拟合线性回归模型
plt.plot(x, y, '.', x, fm.fittedvalues, 'r-') # 绘制散点图和回归线
for i in range(len(x)): # 循环遍历每个数据点
plt.vlines(x[i], y[i], fm.fittedvalues[i], linestyles='dotted', colors='b') # 画垂直虚线连接实际值与预测值
plt.xlabel('自变量 x')
plt.ylabel('因变量 y')
plt.title('模拟直线回归')
plt.grid(True)
plt.show()
# 调用函数进行演示
reglinedemo()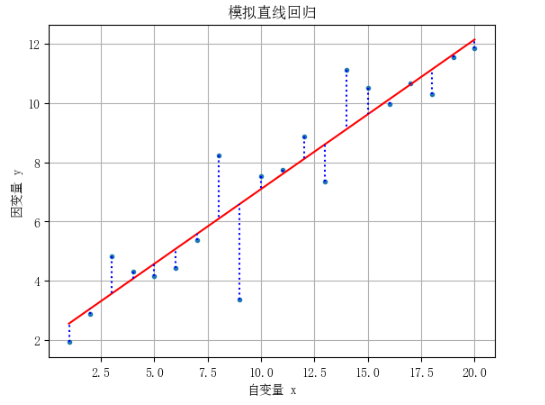
代码导入必要库后定义 `reglinedemo` 函数,默认模拟 20 个样本的线性回归。函数生成自变量、误差项与因变量,添加常数项并用 OLS 拟合模型。绘制散点图、红色回归线及蓝色垂直虚线,设置图的标签、标题和网格后展示。最后调用函数演示。
import scipy.stats as st
M_r=st.pearsonr(BS_M.身高,BS_M.体重)
M_r
plt.rcParams['font.sans-serif']=['SimSun']; #设置中文字体为'宋体'
import seaborn as sns
sns.jointplot(x='身高', y='体重', data=BS_M)
#plt.plot(BS_F.身高,BS_F.体重,'o');
#plt.title(M_r);
st.pearsonr(BS_F.身高,BS_F.体重)
sns.jointplot(x='身高', y='体重',data=BS_F);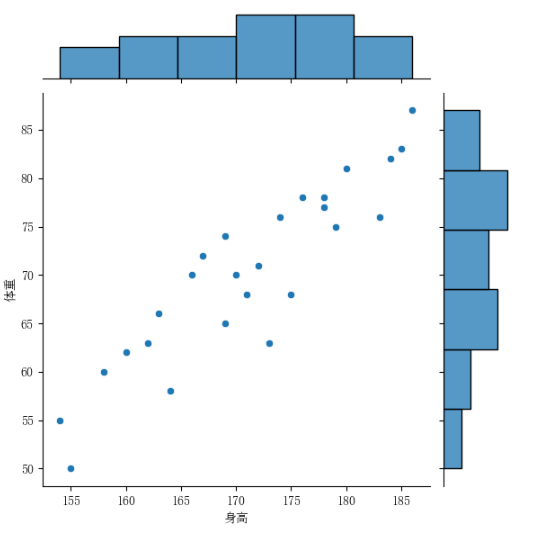
sns.jointplot(x='身高', y='体重',data=BS_F,kind='reg',ci=0); 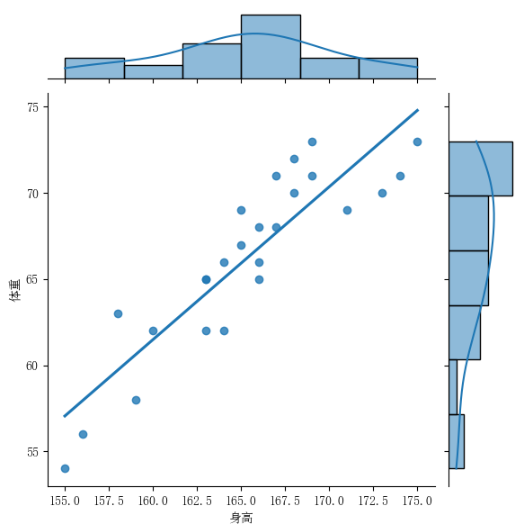
对直线回归模拟代码部分的心得 这段代码围绕直线回归模拟展开,功能较为全面且结构清晰。从代码结构上看,先定义 `reglinedemo` 函数,将直线回归模拟的一系列操作封装其中,提高了代码的模块化和复用性。在数据生成阶段,通过 `numpy` 生成自变量 `x`、服从标准正态分布的误差项 `e` 以及因变量 `y`,逻辑连贯,清晰地构建了用于回归分析的数据基础。 在回归模型拟合方面,借助 `statsmodels.api` 库的 `OLS` 方法,简洁高效地完成了普通最小二乘法拟合,整个过程符合线性回归分析的常规流程。绘图部分是亮点,不仅绘制了样本点与红色回归线,还通过 `for` 循环和 `plt.vlines` 函数准确绘制出从样本点到回归线的蓝色垂直虚线,增强了对回归模型直观展示效果。同时,添加坐标轴标签、标题和网格等操作,极大提升了图形的可读性和专业性。 不过原代码存在一些不足,如缺少关键库导入,这在实际运行时会导致错误,反映出代码在完整性上的欠缺。此外,`plt.vlines` 函数的初始调用有误,这会影响垂直虚线的正确绘制。但好在后续进行了修正,补全导入并调整函数调用,使得代码能够正常且准确地实现预期功能,这也提醒我们在编写代码时要注重细节,确保每个环节都准确无误。 ### 对相关性分析及绘图代码部分的心得 后续代码利用 `scipy.stats` 和 `seaborn` 库进行相关性分析和数据可视化。通过 `st.pearsonr` 计算皮尔逊相关系数,快速衡量变量间的线性相关程度,如对身高和体重数据的相关性分析,直接明了地给出量化结果,为理解变量关系提供了关键指标。 `seaborn` 库的 `jointplot` 函数在数据可视化方面表现出色,它能同时展示变量的单变量分布和双变量关系。绘制散点图及拟合回归线(如 `kind='reg'` 参数的使用),不仅直观呈现数据分布,还能辅助判断变量间是否存在线性趋势,在探索性数据分析中作用显著。设置中文字体为宋体,解决了中文显示可能出现的乱码问题,确保可视化结果在展示上的完整性和美观性。 整体而言,这两段代码从不同角度展示了数据分析与可视化的常用操作,为深入理解数据关系和模型构建提供了很好的示例,也让我认识到在实际编程中,代码的准确性、完整性以及可视化效果的重要性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









