






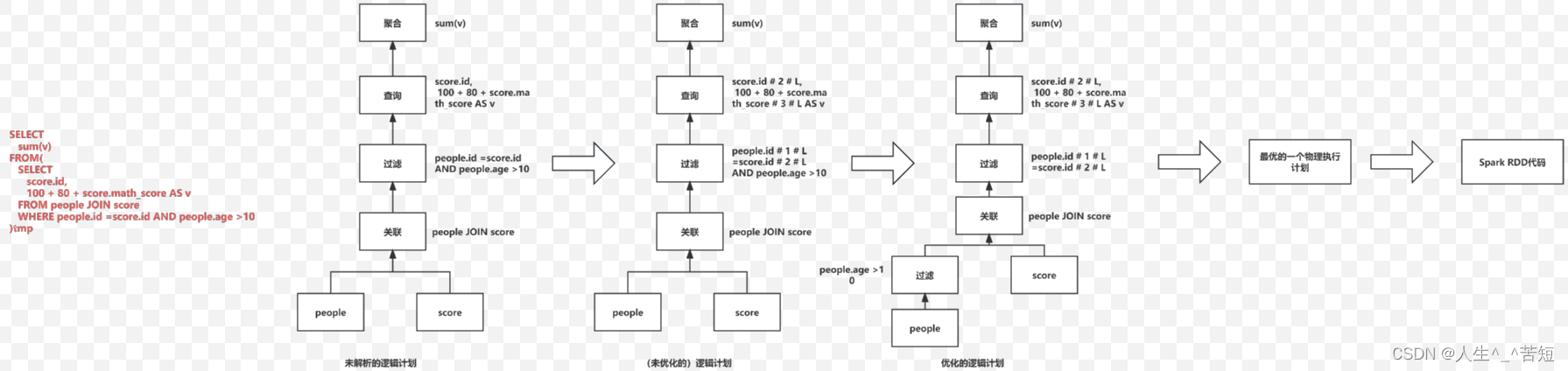
Spark Sql的运行机制,就是将Spark Sql在运行时,在底层翻译为Spark Rdd程序的过程,其中转换是基于Catalyst优化器实施的。
Catalyst内部具体执行流程
1.接收客户端提交过来的sql/DSL代码,然后校验SQL/DSL的语法是否正确。如果通过校验,会根据代码的执行顺序,生成未解析的逻辑计划(AST抽象语法树)
2.对于AST抽象语法树加入元数据信息,确定一共涉及到哪些字段以及数据类型是什么,加入元数据信息以后,就得到了(已经解析但是未优化的)逻辑计划
3.对(未优化的)逻辑计划执行优化操作,整个优化通过优化器来执行。在优化器匹配相对应的优化规则,实时具体的优化。SparkSQL底层提供了一两百中优化规则,得到优化的逻辑计划。例如: 谓词下推(断言下推)、列值裁剪
3.1- 谓词下推: 也叫做断言下推。将数据过滤操作提前到数据扫描的时候执行,减少后续处理数据量,提升效率。
3.2- 列值裁剪: 在表中只加载数据分析用到的字段,不相关的字段不加载进来。减少后续处理数据量,提升效率。
4- 由于优化规则很多,导致会得到多个优化的逻辑计划。在转换成物理执行计划的过程中,会根据 成本模型(对比每个计划运行的耗时、资源消耗等)得到最优的一个物理执行计划。
5- 将物理执行计划通过code generation(代码生成器),转变成Spark RDD的代码。
6- 最后就是将Spark RDD代码部署到集群上运行。
图解:















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









