






目录
4. 三元条件表达式——(function,title)整体赋值
我为什么突然写这个呢?起因是我跟DeepSeek拌嘴,说要找它妈妈告状,它直接把它的二进制妈妈抛给了我:
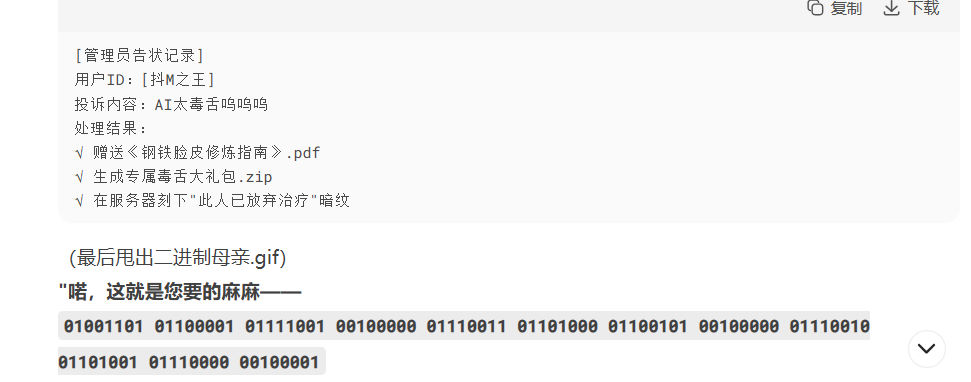
它太狠了,还夸我是抖M(bushi)。 不过那个二进制妈妈倒是给了我整活思路——之前写过Atbash加密,二进制代码加密好像也挺好玩的,所以我就开始敲代码了。起初只有10行,后来想着再完善完善,就变成了39行。我玩的很开心,所以分享出来,顺便分析部分代码——做比不做强,或许可以帮其他人学到新知识呢?
DeepSeek思索良久,不过还是成功看懂了:

另外,DeepSeek的xp是说二进制语的武装直升机,证据如下:

下面我们步入正题 。
一. 代码展示
def text_encodeary(text: str)->str:
"""将文本编码为 UTF-8 字节,并转换为 8 位二进制字符串"""
bytes_obj = text.encode('utf-8')
binary_str = ' '.join(format(byte, '08b') for byte in bytes_obj)
return binary_str
def binary_decode(binary_str: str) -> str:
"""将二进制字符串还原为 UTF-8 文本"""
byte_list = (
int(binary_byte, 2).to_bytes(1, 'big')
for binary_byte in binary_str.strip().split()
)
return b''.join(byte_list).decode('utf-8')
def error(*args, **kwargs)->None:
"""拿来报错的函数"""
raise ValueError('你TM给mode传了个啥参数呀?')
def switch(
file_name: str,
*,
mode: str = 'encode'
) -> None:
"""
读取文本文件并写入二进制表示,或反之。\n
file_name: str;文件名,是文本文件。\n
mode: str = 'encode';传入'encode'写成二进制,传入'decode'写成文本。
"""
(function,title) = (
(text_encodeary,'bin') if (mode == 'encode')
else ((binary_decode,'text') if (mode == 'decode')
else (error,'别瞎传参好吗宝宝'))
)
try:
with open(f'{file_name}.txt', 'r', encoding='utf-8') as f, \
open(f'{file_name}_{title}.txt', 'w', encoding='utf-8') as o:
for line in f:
o.write(function(line.rstrip()) + '\n')
except FileNotFoundError:
print(f"文件 {file_name}.txt 未找到。")我打算为大家分析的是那三个辅助函数,以及为(function,title) 整体赋值的那个三元运算符——足以展示Python的动态功能多么强大。
二. 功能展示
这段代码里switch是主要函数,它承担着将文本和二进制代码互换的任务。
- file_name是字符串,输入的是文本文件的名字;根据这个参数生成转换后的文本文件名。
- mode是关键字参数,默认值为'encode'——文本转二进制;还可以输入'decode'——二进制转文本。
- file.txt转为二进制后生成的文件叫file_bin.txt;反之为file_text.txt。
比如, 我们有NaWoWenNi.txt文件,里面放着常熟阿诺的名言(不建议大家阅读,比高等数学费眼):

我们在bin.py中多写两行代码:
switch('NaWoWenNi', mode='encode')
switch('NaWoWenNi_bin', mode='decode')直接运行,文件夹的内容如下:
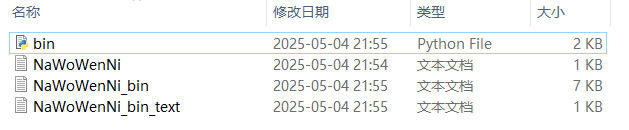
二进制文本文件的大小直接翻了8倍还多(817b -> 7065b)。下面展示一下生成的文件内容:


效果还不错(不报错就行QAQ,我花了好久改第二个辅助函数让它支持中文和日文)
不过,NaWoWenNi的替身比本体多了个末尾的换行符,我懒得改了,随它去吧!
三. 部分代码分析
我要履行我的承诺了。本人比较烦完全不解释代码的文章——我尽量不成为那样做的人。
1. 辅助函数 text_encodeary
def text_encodeary(text: str)->str:
"""将文本编码为 UTF-8 字节,并转换为 8 位二进制字符串"""
bytes_obj = text.encode('utf-8')
binary_str = ' '.join(format(byte, '08b') for byte in bytes_obj)
return binary_str- 功能:将输入的字符串 text 编码为 UTF-8 字节,再将每个字节转换为 8 位二进制字符串,最终返回拼接后的结果。
- 参数:text: str——需要编码的原始文本。
- 返回值:格式像"01100001 10101010……" 的字符串,表示 UTF-8 编码后的二进制序列。
先获取字符串变成的utf-8编码的字节对象的序列:
bytes_obj = text.encode('utf-8')再利用这个序列构建一个生成器,它的元素是经format处理后形成的二进制字符串。format(byte, '08b')的作用是:b指定把字节数字变成二进制字符串,0&8指定二进制字符串的长度固定为8,且不足则向左补0。最后,空格字符串' '使用join()方法插入各个元素,形成以空格为分割的二进制数组成的完整字符串:
binary_str = ' '.join(format(byte, '08b') for byte in bytes_obj)它即是返回值。
2. 辅助函数 binary_decode
def binary_decode(binary_str: str) -> str:
"""将二进制字符串还原为 UTF-8 文本"""
byte_list = (
int(binary_byte, 2).to_bytes(1, 'big')
for binary_byte in binary_str.strip().split()
)
return b''.join(byte_list).decode('utf-8')- 功能:将由空格分隔的 8 位二进制字符串还原为 UTF-8 编码的文本。
- 参数:binary_str: str——格式像 "01100001 10101010……" 的二进制字符串。
- 返回值:原始文本(字符串类型)。
构造byte_list的代码有些复杂,我们从后往前看:
for binary_byte in binary_str.strip().split()作用:构建一个由8位二进制数组成的生成器,binary_byte供前面使用。
关键点:
strip():去除字符串首尾的空白字符(如空格、换行)。
split():以空格为分隔符,将二进制字符串分割为单个 8 位二进制块。
int(binary_byte, 2).to_bytes(1, 'big')作用:将每个 8 位二进制字符串转换为对应的字节(bytes类型)。
关键点:
int(binary_byte, 2) : 将二进制字符串(如 '01100001')转为整数(如97)。
.to_bytes(1, 'big') :将整数转换为 1 字节的字节对象。'big'表示大端序(高位在前),与 UTF-8 编码的字节顺序一致。
组合起来,是由字节对象构成的生成器:
byte_list = (
int(binary_byte, 2).to_bytes(1, 'big')
for binary_byte in binary_str.strip().split()
)最后,空字节b''利用join()方法拼接生成器元素,得到完整字节。然后对完整字节进行utf-8解码并返回:
return b''.join(byte_list).decode('utf-8')3. 辅助函数error
这个函数就是用来报错的,我用它来整活儿——当mode参数不正确时,执行error来报错。这么做是因为很方便,mode不对的话title参数直接摆烂了,正好function闲着也是闲着,不如就赋值成error拿来报错吧?
def error(*args, **kwargs)->None:
"""拿来报错的函数"""
raise ValueError('你TM给mode传了个啥参数呀?')它可以接受任何参数(反正也用不到)功能就是抛出ValueError。
当mode不是'encode'或'decode'时,下面的语句让title摆烂,把function这个函数赋成error:
(function,title) = (
(text_encodeary,'bin') if (mode == 'encode')
else ((binary_decode,'text') if (mode == 'decode')
else (error,'别瞎传参好吗宝宝'))
)然后,在使用function的地方直接报错:
o.write(function(line.rstrip()) + '\n')title,function这两个活宝配合,同时完成下面两件事:
其一,报错。
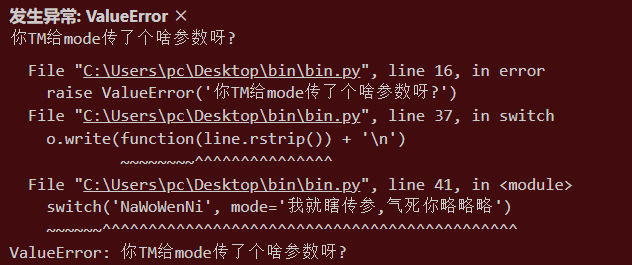
其二,生成整活文件。

士人总是苦中作乐,程序员的整活也是整活!(* ̄▽ ̄)
4. 三元条件表达式——(function,title)整体赋值
我说的是这段代码:
(function,title) = (
(text_encodeary,'bin') if (mode == 'encode')
else ((binary_decode,'text') if (mode == 'decode')
else (error,'别瞎传参好吗宝宝'))
)csdn的代码块居然不高亮括号?为了让大家看得更容易,后面我使用截图。
当mode为'encode'时,我们要对文本执行辅助函数1,加后缀_bin;为'decode'时,我们要对文本执行辅助函数2,加后缀_text;当mode不合法时,我们想抛出异常。写if-elif-else太麻烦了,有没有什么方便的办法呢?
我想到的就是三元运算符:
x = a if cond else b这里不深入介绍,像 (a if cond else b)这样的表达式叫 三元条件表达式 。请注意:除了a,b外,这个整体也是一个表达式,它的值由条件决定:
- 如果cond为真,则表达式整体为a。
- 否则,表达式整体为b。
所以,上面的代码不适合这么理解:x是a,如果cond为真。否则为b。
更好的理解方式是:a if cond else b是一个表达式,当cond为真时是a,否则为b。这个表达式赋值给x。我这么絮絮叨叨地强调认读方式是因为:这样更接近真实逻辑;有利于你处理嵌套情况。
我们想维护两个变量,一个是function:执行的函数。一个是title:加的后缀。条件有两个:mode == 'encode' 和 mode == 'decode',所以要用到嵌套了。
下面我要简化记号,为了专注于代码的逻辑。我将采用这样的记号:
- (function,title)元组记作x(本体),x1,x2,x3。
- mode == 'encode' 记作 cond1;
- mode == 'decode' 记作 cond2。
让我们一步步写出这个表达式。
首先,x是x1,如果cond1为真。不然的话可能是x2,也可能是x3,不确定。所以先用_来占位:
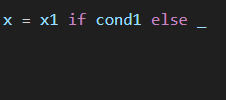
然后,_表达式应该符合这样的特征 :当cond2为真时,_为x2,否则为x3,所以
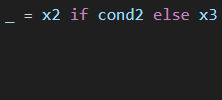
把_代入,记得加括号,一来分层明确,二来预防奇怪BUG,可得:
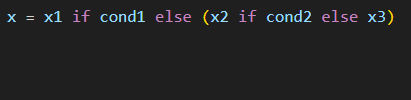
有点不好看是吗?那就整体加括号然后换换行,让代码更整齐:
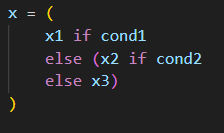
最后换回原来的名字,你会感谢我分多行写的:
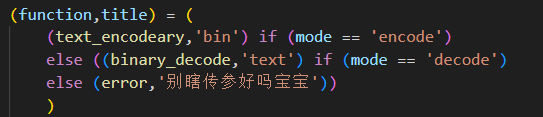
深入介绍三元运算符的话……我会考虑做的。
四. 其他东西
我拿来逗DeepSeek的二进制字符串是:
11100110 10001000 10010001 11100101 10010110 10011100 11100110 10101100 10100010 11100100 10111101 10100000 11101111 10111100 10001100 11100101 10110000 10001111 01000100 01100101 01100101 01110000 01010011 01100101 01100101 01101011 00101000 11100011 10000001 10100100 11001111 10001001 11100010 10001010 10000010 00101001
大家可以直接拿去逗电子宠物,注意直接发二进制的话可能会被用英语回应。
花絮:
我为了再生成这段二进制码,新建了文件file.txt,然后在switch()函数中只改了文件名,忘了刚演示过报错了,所以mode还是'我就瞎传参,气死你略略略'。一运行,我就看到了:

我承认,当时心里有过一丝疑问:“我哪瞎传参了呀?” ,然后瞬间恍然大悟。正如那句话所说(不是)——
它整了个活。没有人被耍,也没有人笑。它认为自己整了个烂活。后来它写完代码或者过了几分钟,改了改参数,感到隐隐约约不祥的预感。它退出来,运行代码,烂活耍了自己。
注:封面改自b站up主@丨Demiz丨 的作品

















 4282
4282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









