



引言
与链表相比,栈和队列在操作和存储结构上都相对简单。栈最大的特点就是先进后出,队列是先进先出。栈和队列的引用场景很广泛,栈在表达式求值、函数调用栈等场景下会用到,而队列在操作系统进程调度、网络通信和广度优先搜索等场景下会用到
接下来,我们一起来看一下栈和队列的实现。
ps:与链表相比,我在第一次学习栈和队列时相对轻松(主要也是因为它们的操作实现本来就比链表简单)。所以第二次学习栈和队列的笔记中,在操作上的文字讲解会比较少,以图片讲解为主。
栈
我们先来看看栈的实现。
这里的栈我们采用顺序表的存储方式去实现。
头文件部分:
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
#define INIT_CAPACITY 4
typedef int dataType;
typedef struct stack {
dataType* a;
int top;//栈顶
int capacity;//最空间大容量
}st;
void initStack(st* ps);//初始化栈
void destroyStack(st* ps);//销毁栈
void pushStack(st* ps, dataType x);//入栈
void popStack(st* ps);//出栈
int stackSize(st* ps);//求栈中元素的数量
bool isEmpty(st* ps);//判断栈是否为空
dataType stackTop(st* ps);//获取栈顶元素
栈的数据结构
typedef int dataType;
typedef struct stack {
dataType* a;
int top;//栈顶
int capacity;//最空间大容量
}st;
栈的初始化
void initStack(st* ps)
{
assert(ps);
ps->a = (dataType*)malloc(sizeof(dataType) * INIT_CAPACITY);
if (!ps->a)
{
perror("malloc fail");
return;
}
ps->top = 0;//栈顶指待入栈元素的位置
ps->capacity = INIT_CAPACITY;
printf("The stack has been successfully initialized!\n");
}
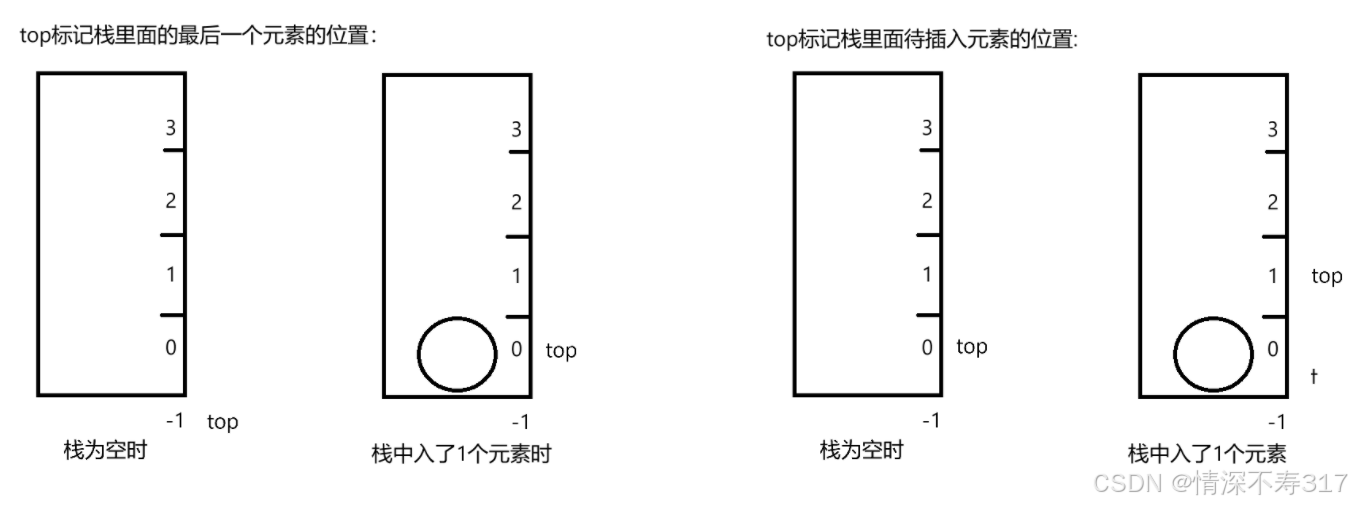
我们可以让top标记栈里面的最后一个元素的位置,也可以让top标记栈里面待插入元素的位置。
这里我们是让top标记的是待插入元素的位置,所以ps->top初始化为0。
如果想让top标记最后一个元素的位置,我们要将ps->top初始化为-1。
判断栈是否为空
bool isEmpty(st* ps)
{
assert(ps);
return ps->top == 0;
}
同样的,如果我们让top标记最后一个元素的位置,我们就要返回ps->top==-1
入栈
void pushStack(st* ps, dataType x)
{
assert(ps);
if (ps->top == ps->capacity) {
//栈满了,要扩容
st* tmp = (dataType*)realloc(ps->a, sizeof(dataType) * ps->capacity * 2);
if (!tmp) {
perror("realloc fail");
return;
}
ps->a = tmp;
ps->capacity *= 2;
}
ps->a[ps->top++] = x;
}
出栈
void popStack(st* ps)
{
assert(ps);
if (isEmpty(ps)) {
printf("The stack is empty!\n");
return;
}
--ps->top;
}
求栈中元素的数量
int stackSize(st* ps)
{
assert(ps);
return ps->top;
}
如果我们让top标记最后一个元素的位置,我们就要返回ps->top + 1
获取栈顶元素
dataType stackTop(st* ps)
{
assert(ps);
return ps->a[ps->top - 1];
}
如果我们让top标记最后一个元素的位置,我们就要返回ps->a[ps->top]
销毁栈
void destroyStack(st* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->capacity = 0;
ps->top = 0;
printf("The stack has been destroyed!\n");
}
测试案例
void test() {
st ps;
initStack(&ps);
//入栈
pushStack(&ps, 0);
printf("current top:%d current size:%d\n", stackTop(&ps),stackSize(&ps));
pushStack(&ps, 1);
printf("current top:%d current size:%d\n", stackTop(&ps), stackSize(&ps));
pushStack(&ps, 2);
printf("current top:%d current size:%d\n", stackTop(&ps), stackSize(&ps));
pushStack(&ps, 10);
printf("current top:%d current size:%d\n", stackTop(&ps), stackSize(&ps));
pushStack(&ps, 20);
printf("current top:%d current size:%d\n", stackTop(&ps), stackSize(&ps));
pushStack(&ps, 60);
printf("current top:%d current size:%d\n\n", stackTop(&ps), stackSize(&ps));
//出栈
popStack(&ps);
printf("current top:%d current size:%d\n", stackTop(&ps), stackSize(&ps));
popStack(&ps);
printf("current top:%d current size:%d\n", stackTop(&ps), stackSize(&ps));
popStack(&ps);
printf("current top:%d current size:%d\n", stackTop(&ps), stackSize(&ps));
popStack(&ps);
printf("current top:%d current size:%d\n", stackTop(&ps), stackSize(&ps));
popStack(&ps);
printf("current top:%d current size:%d\n", stackTop(&ps), stackSize(&ps));
popStack(&ps);
popStack(&ps);
destroyStack(&ps);
}
与链表相比,栈在测试函数中的定义有所不同
回顾前面链表的测试案例,我们定义的是链表节点指针;在栈的测试案例中,我们定义的是结构体,并没有使用指针。
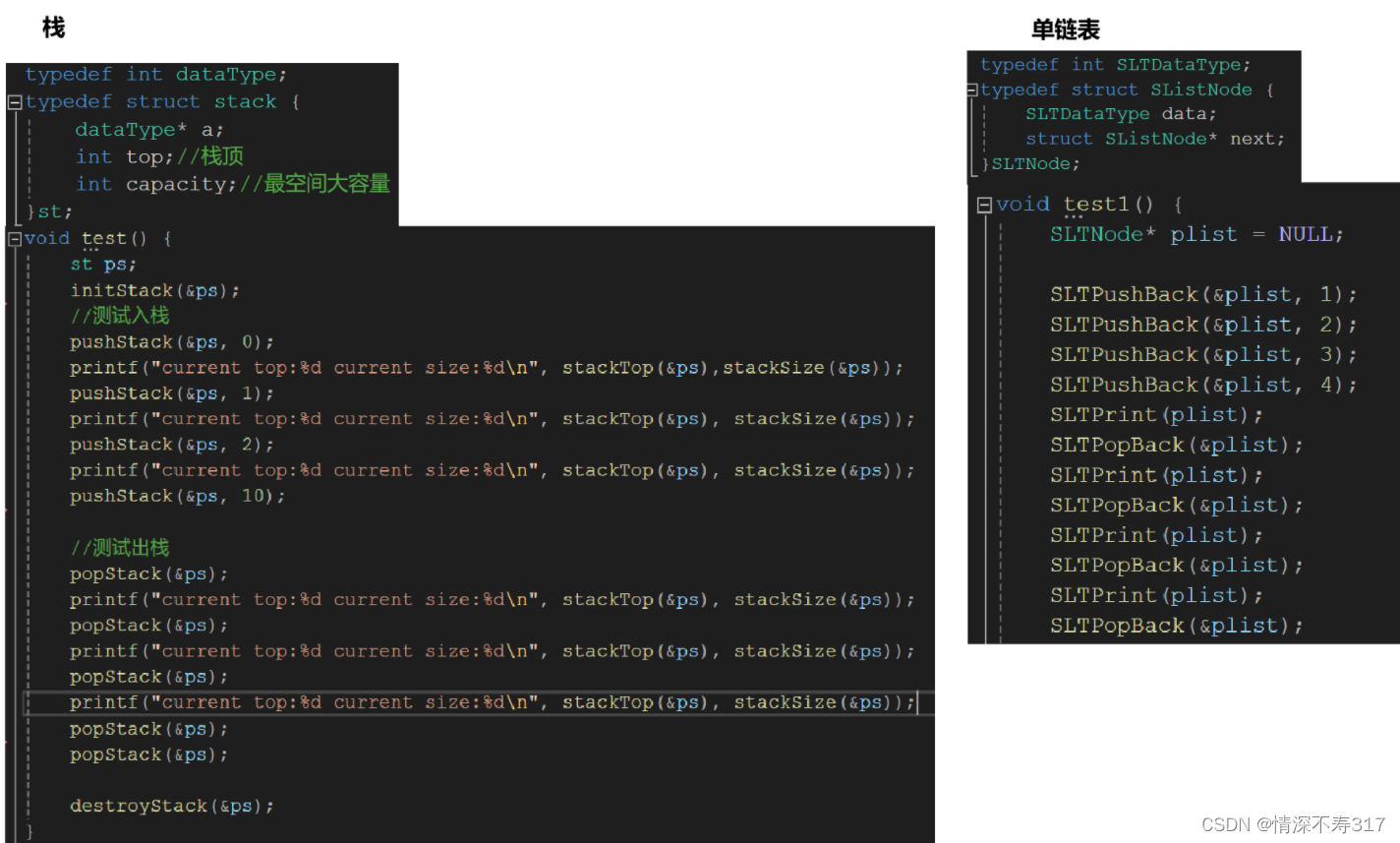
这是为什么呢?
选择使用结构体本身还是结构体指针通常取决于该数据结构的设计需求和使用场景。下面我们将从栈和链表的数据结构、操作和存储方式来分析为什么上面的代码中,栈使用了结构体本身,而链表使用了结构体指针。
我们先来看栈:
栈通常被设计为在固定大小的数组中存储元素,或者在某些实现中,它可能动态地调整其大小(上面则是通过分配更大的数组并复制旧数据)。在上面的代码中,栈结构体 st 包含了一个指向元素数组的指针 dataType* a,一个表示栈顶的索引 top,以及栈的容量 capacity。
当我们在test函数中定义一个栈 st ps; 时,实际上是在栈的作用域内创建了一个栈的实例。这个实例包含了栈的所有状态信息,包括指向数组的指针、栈顶索引和容量。由于栈的大小可能是固定的,或者至少在其生命周期内不需要频繁地改变,因此可以直接在栈上分配这个结构体。
我们再来看链表:
链表则不同,它的节点通常是通过指针相互链接的。在之前讲的链表的代码中,链表节点结构体 SLTNode 包含了一个数据字段 data 和一个指向下一个节点的指针 next。
当我们定义一个链表节点指针 SLTNode* plist = NULL; 时,实际上是在创建一个指向链表节点的指针,该指针最初被初始化为 NULL,表示链表为空。链表的动态性质(我们可以随时在链表的头部、尾部或中间插入或删除节点)使得使用指针来管理链表变得非常方便。通过指针,我们可以轻松地更新节点的链接,而不需要移动节点本身的数据。
此外,链表通常是通过在堆上动态分配内存来创建节点的,这使得链表能够根据需要增长和缩小。使用指针可以轻松地管理这些动态分配的内存块。
总结:在上面的代码中,栈是一个相对固定大小的数据结构,因此可以直接在栈上分配其结构体实例;链表则是一个动态数据结构,其节点通常通过指针链接,并且经常在堆上动态分配内存。因此,使用结构体指针来管理链表节点是更自然和高效的选择。
但是这些设计选择并不是绝对的,而是取决于具体的应用场景和数据结构的需求。在某些情况下,栈也可能使用动态分配的内存和指针(实现栈的基本功能函数中就需要传入二级指针),而链表也可能被设计为具有固定大小的数组结构(尽管这不太常见)。
队列
这里的队列我们采用链表的存储方式去实现。
头文件部分:
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
typedef int QdataType;
typedef struct queueNode
{
struct queueNode* next;
QdataType data;
}QNode;
typedef struct Queue
{
QNode* head;
QNode* tail;
int size;
}Queue;
void initQueue(Queue* pQueue);//初始化队列
QNode* createQueueNode(QdataType x);//创建节点
void queueDestroy(Queue* pQueue);//销毁队列
void pushQueue(Queue* pQueue, QdataType x);//入队
void popQueue(Queue* pQueue);//出队
int sizeQueue(Queue* pQueue);//获取队列元素个数
bool emptyQueue(Queue* pQueue);//判断队列是否为空
QdataType queueFront(Queue* pQueue);//获取队头元素
QdataType queueBack(Queue* pQueue);//获取队尾元素
队列的数据结构
typedef int QdataType;
typedef struct queueNode
{
struct queueNode* next;
QdataType data;
}QNode;
typedef struct Queue
{
QNode* head;
QNode* tail;
int size;
}Queue;
为什么这里有两个结构体呢?
这里的QNode是队列中每个节点的数据结构,Queue是用来维护队列的队头、队尾和记录队列元素个数的数据结构:
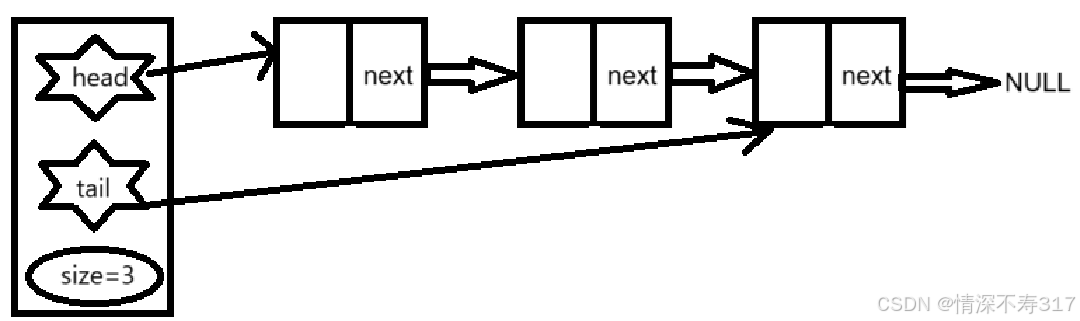
多个数据最好用结构体封装起来。将队列的队头和队尾以及记录元素个数的size封装在结构体是为了在后面调用函数时更加便利,减少参数的传递:
QNode结构体维护的是队列的局部(处理每个入队节点之间的联系),Queue维护的是队列的整体(处理队列的队头和队尾)。
在Queue结构体中放int size的好处
我们回顾之前讲带头双向循环链表的时候,这里的size就是靠遍历来求的。如果在Queue结构体中没有这个size,我们后面想求队列的size也只能靠遍历,这样的话时间复杂度就是O(N)了。
那为什么我们不把int size放在队列的节点结构体中呢?因为这并不是一个合理的设计。为什么呢?因为节点里面存的数据类型不一定是int,如果这里的dataType是char类型,存进去的数据超过了128会溢出。
初始化队列
void initQueue(Queue* pQueue)
{
assert(pQueue);
pQueue->head = pQueue->tail = NULL;
pQueue->size = 0;
printf("The queue has been initialized.\n");
}
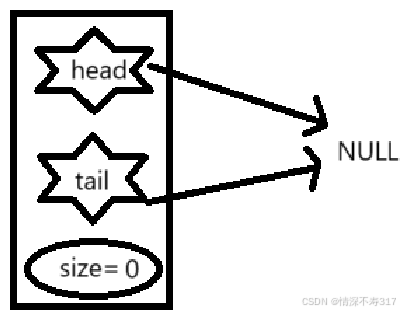
队列为空时,队头队尾都指向空。
创建待入队的节点
QNode* createQueueNode(dataType x)
{
QNode* newNode = (QNode*)malloc(sizeof(QNode));
if (newNode == NULL) {
perror("malloc fail");
return NULL;
}
newNode->data = x;
newNode->next = NULL;
return newNode;
}
入队
void pushQueue(Queue* pQueue, QdataType x)
{
assert(pQueue);
QNode* newNode = createQueueNode(x);
if (pQueue->head == NULL) {
assert(pQueue->tail == NULL);
//此时队列无元素
pQueue->head = pQueue->tail = newNode;
}
else {
//此时队列有元素
pQueue->tail->next = newNode;
pQueue->tail = newNode;
}
++pQueue->size;
}
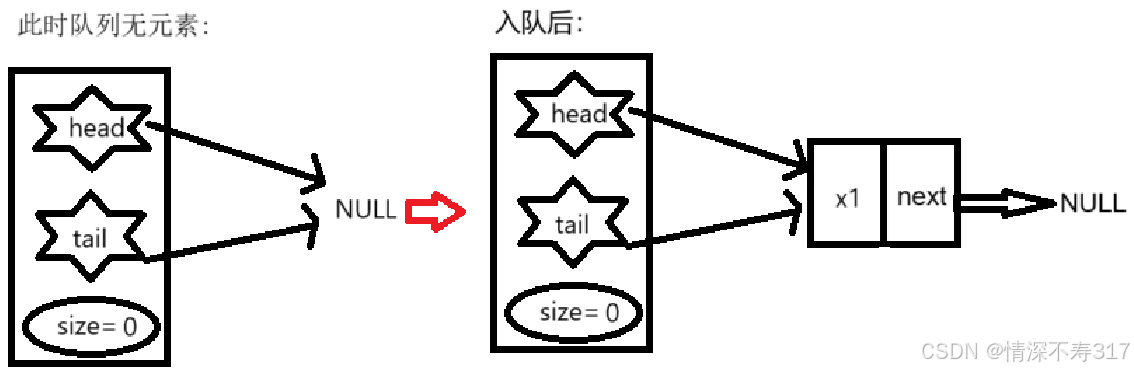
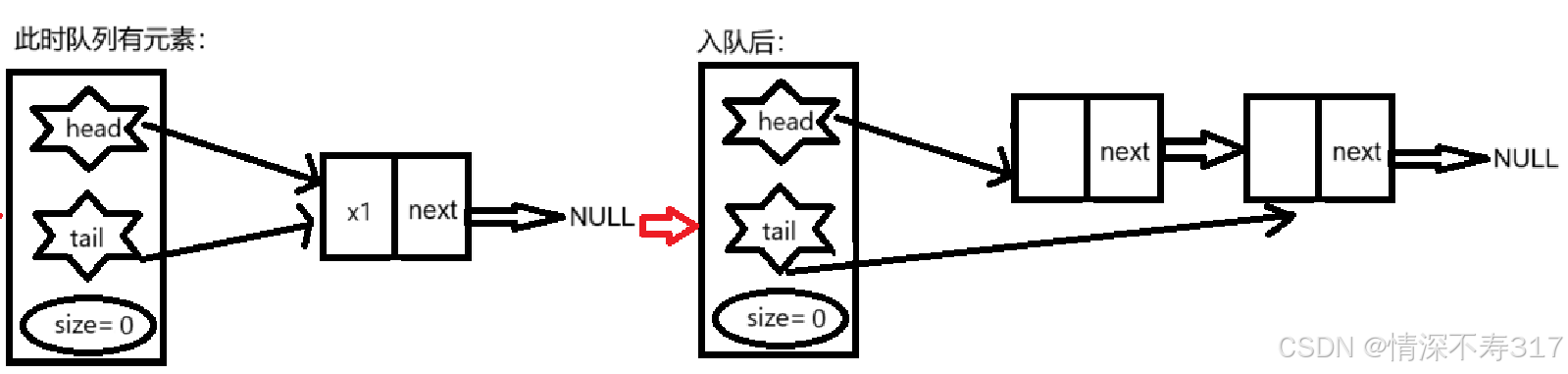
出队
void popQueue(Queue* pQueue)
{
assert(pQueue);
assert(pQueue->size != 0);//队列不能为空
QNode* out = pQueue->head;//备份要出队的元素
pQueue->head = pQueue->head->next;
free(out);
if (pQueue->size == 1) {
//当队列只有一个元素时,需要将尾指针置空
pQueue->tail = NULL;
}
--pQueue->size;
}
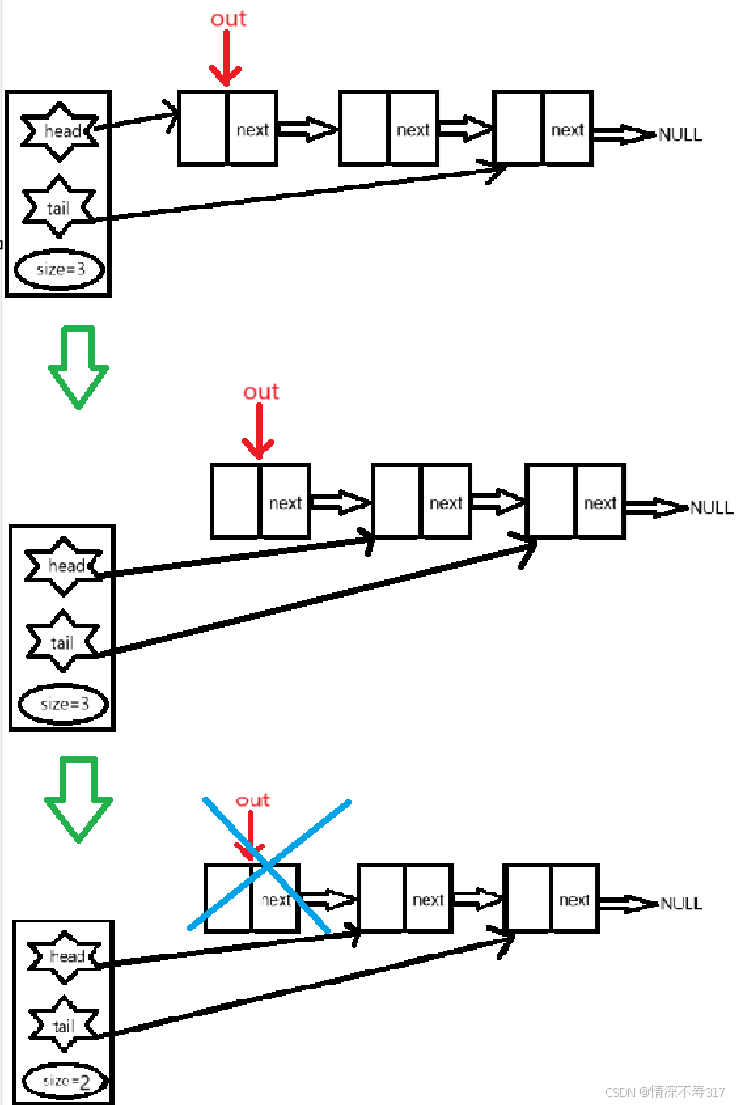
出队时,我们需要单独考虑队列只有一个元素的情况,最后一定不能忘了把tail 指针置空。如果忘了会出现如下情况:
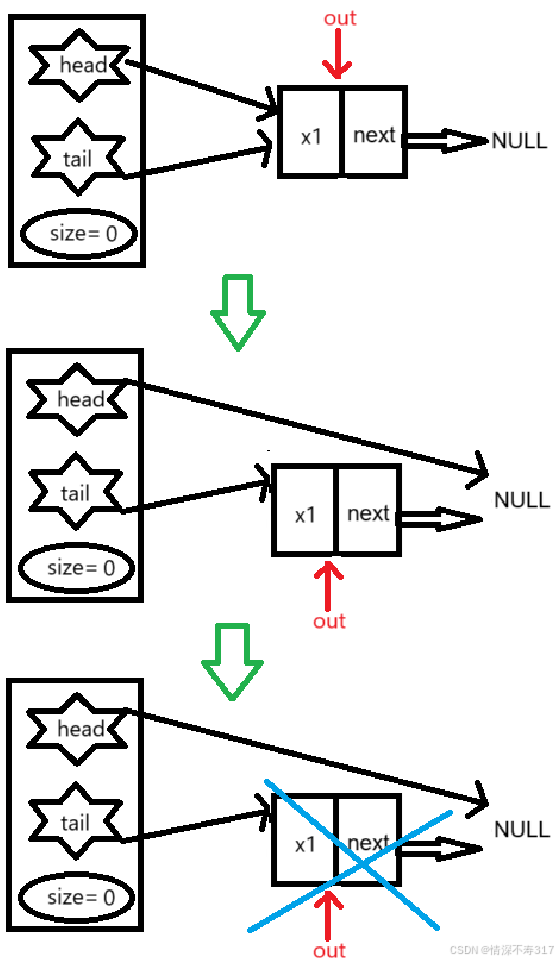
此时 tail 指针还会指向原来那个已经被释放的内存位置,如果后续代码试图访问 tail 指针指向的位置,比如为了检查队列是否为空或者尝试读取队列的尾部元素,就会导致访问无效内存。
获取队列元素个数
int sizeQueue(Queue* pQueue)
{
assert(pQueue);
return pQueue->size;
}
判断队列是否为空
bool emptyQueue(Queue* pQueue)
{
assert(pQueue);
if (pQueue->size == 0) {
return true;
}
else {
return false;
}
}
访问队头元素
QdataType queueFront(Queue* pQueue)
{
assert(pQueue);
assert(pQueue->size != 0);
return pQueue->head->data;
}
访问队尾元素
QdataType queueBack(Queue* pQueue)
{
assert(pQueue);
assert(pQueue->size != 0);
return pQueue->tail->data;
}
销毁队列
void queueDestroy(Queue* pQueue)
{
assert(pQueue);
QNode* cur = pQueue->head;
while (cur) {
QNode* tmp = cur;
cur = cur->next;
free(tmp);
}
pQueue->head = pQueue->tail = NULL;
pQueue->size = 0;
printf("The queue has been destroyed.\n");
}


















 1203
1203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









