






目录
一、Scala基础
1、定义函数识别号码类型
1、了解数据类型
Scala常用数据类型:
| 数据类型c | 描述 |
| Int | 32位有符号补码整数。数值区间为−32768~32767 |
| Float | 32位IEEE754(IEEE浮点数算术标准)单精度浮点数 |
| Double | 64位IEEE754(IEEE浮点数算术标准)双精度浮点数 |
| String | 字符序列,即字符串 |
| Boolean | 布尔值,true或false |
| Unit | 表示无值,作用与Java中的void一样,是不返回任何结果的方法的结果类型。Unit只有一个实例值,写成() |
2、定义与使用常量、变量
(1)、常量
在程序运行过程中值不会发生变化的量为常量或值,常量通过val关键字定义,常量一旦定义就不可更改,即不能对常量进行重新计算或重新赋值。定义一个常量的语法格式如下。
val name: type = initialization
val 关键字后以此跟着常量名称、冒号“:”、数据类型、赋值运算符“=”和初始值。一旦初始化一个常量,就不能对其修改。
(2)、变量
变量是在程序运行过程中值可能发生改变的量。变量使用关键字var定义。与常量不同的是,变量定义之后可以重新被赋值。定义一个变量的语法格式如下。
var name: type = initialization
变量在重新赋值时,只能将同类型的值附给变量。
2、使用运算符
scala是一种面向对象的函数式编程语言,内置丰富的运算符,包括算术运算符、关系运算符、逻辑运算符等,如下表所示:
| 运算符 | 意义 | 示例 | |
| 算术 运算符 | + | 两个数相加 | 1+2或1.+(2) |
| − | 两个数相减 | 1−2或1. − (2) | |
| * | 两个数相乘 | 1*2或1.*(2) | |
| / | 两个数相除 | 1/2或1./(2) | |
| % | 两个数取余 | 1%2或1.%(2) | |
| 关系 运算符 | > | 判断左值是否大于右值,是则结果为真,否则结果为假 | 1>2或1.>(2) |
| < | 判断左值是否小于右值,是则结果为真,否则结果为假 | 1<2或1.<(2) | |
| >= | 判断左值是否大于等于右值,是则结果为真,否则结果为假 | 1>=2或1.>=(2) | |
| <= | 判断左值是否小于等于右值,是则结果为真,否则结果为假 | 1<=2或1.<=(2) | |
| == | 判断左值是否等于右值,是则结果为真,否则结果为假 | 1==2或1.==(2) | |
| != | 判断左值是否不等于右值,是则结果为真,否则结果为假 | 1!=2或1.!=(2) |
| 运算符 | 意义 | 示例 | |
| 逻辑 运算符 | && | 若两个条件成立则结果为真,否则结果为假 | 1>2 && 2>3或1>2.&&(2>3) |
| || | 若两个条件有一个成立则结果为真,否则结果为假 | 1>2 || 2>3或1>2.||(2>3) | |
| ! | 对当前结果取反 | !(1>2) | |
| 位 运算符 | & | 参加运算的两个数据,按二进制位进行&运算,两位同时结果为1结果才为1,否则为0 | 0 & 1或0.&(1) |
| | | 参加运算的两个数据,按二进制位进行|运算,两位只要有一个为1则结果为1 | 0 | 1或0.|(1) | |
| ^ | 参加运算的两个数据,按二进制位进行^运算,两位不同时结果为1,相同时结果为0 | 0^1或0.^(1) |
| 运算符 | 意义 | 示例 | |
| 赋值 运算符 | = | 将右侧的值赋于左侧 | val a = 2 |
| += | 执行加法后再赋值左侧 | a += 2 | |
| −= | 执行减法后再赋值左侧 | a-= 1 | |
| *= | 执行乘法后再赋值左侧 | a *= 2 | |
| /= | 执行除法后再赋值左侧 | a /= 3 | |
| %= | 执行取余后再赋值左侧 | a %= 5 | |
| <<= | 左移位后赋值左侧 | a <<= 2 | |
| >>= | 右移位后赋值左侧 | a >>= 2 | |
| &= | 按位&运算后赋值左侧 | a &= 2 | |
| |= | 按位|运算后赋值左侧 | a |= 2 | |
| ^= | 按位^运算后赋值左侧 | a ^= 2 |
3、定义与使用数组
数组是Scala中常用的一种数据结构,数组是一种存储了相同类型元素的固定大小的顺序集合。
Scala定义一个数组的语法格式如下。
第一种方法
var arr: Array[String] = new Array[String](sum)
第二种方法
var arr: Array[String] = Array(元素1,元素2,...)
数组常用的方法:
| 方法 | 描述 |
| length | 返回数组的长度 |
| head | 查看数组的第一个元素 |
| tail | 查看数组中除了第一个元素外的其他元素 |
| isEmpty | 判断数组是否为空 |
| contains(x) | 判断数组是否包含元素x |
数组的使用:


Scala可以使用range()方法创建区间数组。
使用range()方法前同样需要先通过命令“import Array._”导入包。
4、定义与使用函数
- 函数是Scala的重要组成部分,Scala作为支持函数式编程的语言,可以将函数作为对象.
- 定义函数的语法格式如下。
- def functionName(参数列表): [return type] = {}
- Scala提供了多种不同的函数调用方式,以下是调用函数的标准格式。
- functionName(参数列表)
- 如果函数定义在一个类中,那么可以通过“类名.方法名(参数列表)”的方式调用。
-
1.匿名函数
-
匿名函数即在定义函数时不给出函数名的函数。
Scala中匿名函数是使用箭头“=>”定义的,箭头的左边是参数列表,箭头的右边是表达式,表达式将产生函数的结果。
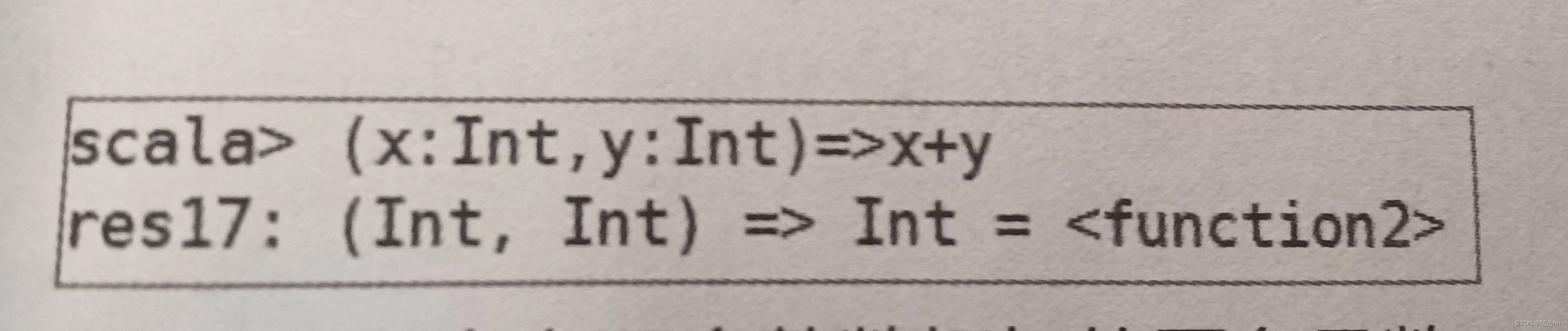
通常可以将匿名函数赋值给一个常量或变量,再通过常量名或变量名调用该函数。

若函数中的每个参数在函数中最多只出现一次,则可以使用占位符“_”代替参数。

2.高阶函数—函数作为参数
- 高阶函数指的是操作其他函数的函数。
- 高阶函数可以将函数作为参数,也可以将函数作为返回值。
- 高阶函数经常将只需要执行一次的函数定义为匿名函数并作为参数。一般情况下,匿名函数的定义是“参数列表=>表达式”。
- 由于匿名参数具有参数推断的特性,即推断参数的数据类型,或根据表达式的计算结果推断返回结果的数据类型,因此定义高阶函数并使用匿名函数作为参数时,可以简化匿名函数的写法。
3.高阶函数—函数作为返回值
- 高阶函数可以产生新的函数,并将新的函数作为返回值。
- 定义高阶函数计算矩形的周长,该函数传入一个Double类型的值作为参数,返回以一个Double类型的值作为参数的函数,如下图。

4.函数柯里化
函数柯里化是指将接收多个参数的函数变换成接收单一参数(最初函数的第一个参数)的函数,新的函数返回一个以原函数余下的参数为参数的函数。
定义两个整数相加的函数,一般函数的写法及其调用方式如下图。

使用函数柯里化方式如下图。

5、定义与使用列表
1、定义列表
Scala的列表(List)与数组非常相似,列表的所有元素都具有相同的类型。
与数组不同的是,列表是不可变的,即列表的元素不能通过赋值进行更改。
定义列表时,需要写明列表元素的数据类型,或者根据列表初值类型自动推断。具有类型T的元素的列表类型可写为List[T]。代码如下:

构造列表的两个基本单位是“Nil”和“::”。
“Nil”可以表示空列表;
“::”称为中缀操作符,表示列表从前端扩展,遵循右结合。代码如下:

2、列表操作常用方法
| 方法 | 描述 |
| def head: A | 获取列表的第一个元素 |
| def init:List[A] | 返回所有元素,除了最后一个元素 |
| def last:A | 获取列表的最后一个元素 |
| def tail:List[A] | 返回所有元素,除了第一个元素 |
| def :::(prefix: List[A]): List[A] | 在列表开头添加指定列表的元素 |
| def take(n: Int): List[A] | 获取列表前n个元素 |
| def contains(elem: Any): Boolean | 判断列表是否包含指定元素 |
Scala中常用的查看列表元素的方法有head、init、last、tail和take()。
- head:查看列表的第一个元素。
- tail:查看第一个元素之后的其余元素。
- last:查看列表的最后一个元素。
- Init:查看除最后一个元素外的所有元素。
- take():查看列表前n个元素。
3、合并列表
如果需要合并两个列表,那么可以使用:::()。
但需要注意,“列表1:::列表2”与“列表1.:::(列表2)”的结果是不一样的,对于前者,列表2的元素添加在列表1的后面;对于后者,列表2的元素添加在列表1的前面。合并两个列表还可以使用concat()方法。

用户可以使用contains()方法判断列表中是否包含某个元素,若列表中存在指定的元素则返回true,否则返回false。

6、定义与使用集合
Scala Set(集合)是没有重复的对象集合,所有的元素都是唯一的。
集合操作常用方法
| 方法 | 描述 |
| def head: A | 获取集合的第一个元素 |
| def init:Set[A] | 返回所有元素,除了最后一个 |
| def last:A | 获取集合的最后一个元素 |
| def tail:Set[A] | 返回所有元素,除了第一个 |
| def ++(elems: A): Set[A] | 合并两个集合 |
| def take(n: Int): List[A] | 获取列表前n个元素 |
| def contains(elem: Any): Boolean | 判断集合中是否包含指定元素 |
Scala合并两个列表时使用的是:::()或concat()方法,而合并两个集合使用的是++()方法。
7、定义与使用映射
- 映射(Map)是一种可迭代的键值对结构。
- 所有的值都可以通过键来获取,并且映射中的键都是唯一的。
- 集合操作常用方法同样也适合映射。
- 另外映射还可以通过keys方法获取所有的键,通过values方法获取所有值,也可以通过isEmpty方法判断映射的数据是否为空
8、定义与使用元组
- 元组(Tuple)是一种类似于列表的结构,但与列表不同的是,元组可以包含不同类型的元素。
- 元组的值是通过将单个的值包含在圆括号中构成的。
- 目前,Scala支持的元组最大长度为22,即Scala元组最多只能包含22个元素。
- 访问元组元素可以通过“元组名称._元素索引”进行,索引从1开始。
9、 用函数组合器
1、map()方法
map()方法可通过一个函数重新计算列表中的所有元素,并且返回一个包含相同数目元素的新列表。

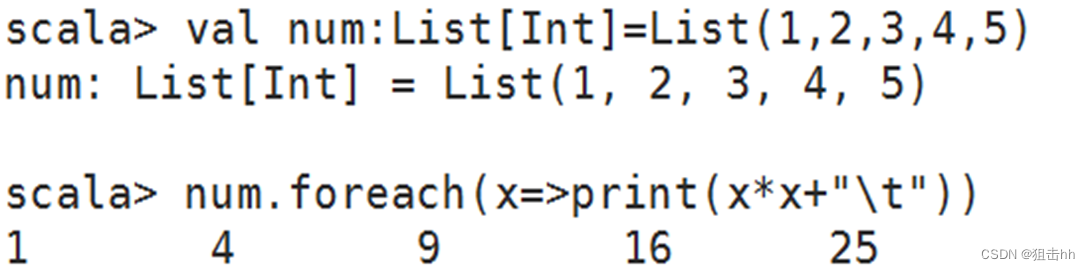
2、foreach()方法
foreach()方法和map()方法类似,但是foreach()方法没有返回值,只用于对参数的结果进行输出。
3、filter()方法
filter()方法可以移除传入函数的返回值为false的元素。

4、flatten()方法
flatten()方法可以将嵌套的结构展开,即flatten()方法可以将一个二维的列表展开成一个一维的列表。

5、flatMap()方法
flatMap()方法结合了map()方法和flatten()方法的功能,接收一个可以处理嵌套列表的函数,再对返回结果进行连接。

6、groupBy()方法
groupBy()方法可对集合中的元素进行分组操作,返回的结果是一个映射。

10、定义Scala类
Scala类继承一个类时需要使用关键字extends。
Scala只允许继承一个父类,并且继承父类的所有属性和方法。
子类继承父类中已经实现的方法时,需要使用override关键字,子类继承父类中未实现的方法时,可以不用override关键字。
11、使用Scala单例模式
Scala中没有static关键字,因此Scala的类中不存在静态成员。但是Scala可以使用object关键字实现单例模式。
Scala中使用单例模式时需要使用object定义一个单例对象(object对象),单例对象在整个程序中只有一个实例。单例对象与类的区别在于单例对象不能带参数。
定义单例对象的语法如下。
- object ObjectName {}
包含main方法的object对象可以作为程序的入口点。
当单例对象与某个类共享同一个名称时,单例对象被称作这个类的伴生对象,类被称为这个单例对象的伴生类。类和它的伴生对象可以互相访问对方的私有成员。
需要注意的是,必须在同一个源文件里定义类和它的伴生对象。
Scala提供了强大的模式匹配机制。一个模式匹配包含了一系列备选项,每个都开始于关键字case。每个备选项都包含了一个模式及一到多个表达式。模式和表达式之间用“=>”隔开。
在Scala中,使用case关键字定义的类称为样例类。样例类是一种特殊的类,经过优化可应用于模式匹配。
- Scala编译器为样例类添加了一些语法上的便捷设定,具体如下。
(1)在伴生对象中提供了apply()方法,因此不使用new关键字也可以构造对象。
(2)样例类参数列表中的所有参数已隐式获得val关键字。
(3)编译器为样例类添加了toString()、hashCode()和equals()等方法。
二、Spark编程基础
1、创建RDD
RDD是一个容错的、只读的、可进行并行操作的数据结构,是一个分布在集群各个节点中的存放元素的集合。RDD的创建有3种不同的方法。
- 第一种是将程序中已存在的Seq集合(如集合、列表、数组)转换成RDD。
- 第二种是对已有RDD进行转换得到新的RDD,这两种方法都是通过内存中已有的集合创建RDD的。
- 第三种是直接读取外部存储系统的数据创建RDD。
2、从内存中读取数据创建RDD
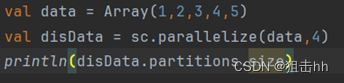
1、parallelize()
parallelize()方法有两个输入参数,说明如下。
- 要转化的集合,必须是Seq集合。Seq表示序列,指的是一类具有一定长度的、可迭代访问的对象,其中每个数据元素均带有一个从0开始的、固定的索引。
- 分区数。若不设分区数,则RDD的分区数默认为该程序分配到的资源的CPU核心数。

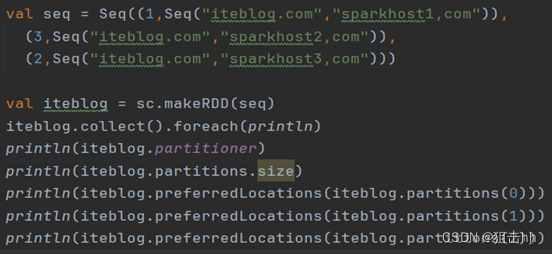
2、 makeRDD()
makeRDD()方法有两种使用方式:
- 第一种方式的使用与parallelize()方法一致;
- 第二种方式是通过接收一个是Seq[(T,Seq[String])]参数类型创建RDD。
第二种方式生成的RDD中保存的是T的值,Seq[String]部分的数据会按照Seq[(T,Seq[String])]的顺序存放到各个分区中,一个Seq[String]对应存放至一个分区,并为数据提供位置信息,通过preferredLocations()方法可以根据位置信息查看每一个分区的值。调用makeRDD()时不可以直接指定RDD的分区个数,分区的个数与Seq[String]参数的个数是保持一致的
3、 从外部存储系统中读取数据创建RDD
从外部存储系统中读取数据创建RDD是指直接读取存放在文件系统中的数据文件创建RDD。
从内存中读取数据创建RDD的方法常用于测试,从外部存储系统中读取数据创建RDD才是用于实践操作的常用方法。
从外部存储系统中读取数据创建RDD可以有很多种数据来源,可通过SparkContext对象的textFile()方法读取数据集,该方法支持多种类型的数据集,如目录、文本文件、压缩文件和通配符匹配的文件等,并且允许设定分区个数。
分别读取HDFS文件和Linux本地文件的数据并创建RDD,具体操作如下。
(1)通过HDFS文件创建RDD,直接通过textFile()方法读取HDFS文件的位置即可。
(2)通过Linux本地文件创建RDD

本地文件的读取也是通过sc.textFile("路径")的方法实现的,在路径前面加上“file://”表示从Linux本地文件系统读取。在IntelliJ IDEA开发环境中可以直接读取本地文件;但在spark-shell中,要求在所有节点的相同位置保存该文件才可以读取它。
4、转换操作
1、使用map()方法转换数据
map()方法是一种基础的RDD转换操作,可以对RDD中的每一个数据元素通过某种函数进行转换并返回新的RDD。
map()方法是转换操作,不会立即进行计算。
转换操作是创建RDD的第二种方法,通过转换已有RDD生成新的RDD。因为RDD是一个不可变的集合,所以如果对RDD数据进行了某种转换,那么会生成一个新的RDD。操作如下:

2、使用sortBy()方法进行排序
sortBy()方法用于对标准RDD进行排序,有3个可输入参数,说明如下。
- 第1个参数是一个函数f:(T) => K,左边是要被排序对象中的每一个元素,右边返回的值是元素中要进行排序的值。
- 第2个参数是ascending,决定排序后RDD中的元素是升序的还是降序的,默认是true,即升序排序,如果需要降序排序那么需要将参数的值设置为false。
- 第3个参数是numPartitions,决定排序后的RDD的分区个数,默认排序后的分区个数和排序之前的分区个数相等,即this.partitions.size。
第一个参数是必须输入的,而后面的两个参数可以不输入。操作如下:

3、使用collect()方法查询数据
collect()方法是一种行动操作,可以将RDD中所有元素转换成数组并返回到Driver端,适用于返回处理后的少量数据。
因为需要从集群各个节点收集数据到本地,经过网络传输,并且加载到Driver内存中,所以如果数据量比较大,会给网络传输造成很大的压力。
因此,数据量较大时,尽量不使用collect()方法,否则可能导致Driver端出现内存溢出问题。
collect()方法有以下两种操作方式。
(1)collect:直接调用collect返回该RDD中的所有元素,返回类型是一个Array[T]数组。

(2)collect[U: ClassTag](f: PartialFunction[T, U]):RDD[U]。这种方式需要提供一个标准的偏函数,将元素保存至一个RDD中。首先定义一个函数one,用于将collect方法得到的数组中数值为1的值替换为“one”,将其他值替换为“other”。
 4、使用flatMap()方法转换数据
4、使用flatMap()方法转换数据
- flatMap()方法将函数参数应用于RDD之中的每一个元素,将返回的迭代器(如数组、列表等)中的所有元素构成新的RDD。
- 使用flatMap()方法时先进行map(映射)再进行flat(扁平化)操作,数据会先经过跟map一样的操作,为每一条输入返回一个迭代器(可迭代的数据类型),然后将所得到的不同级别的迭代器中的元素全部当成同级别的元素,返回一个元素级别全部相同的RDD。
- 这个转换操作通常用来切分单词,操作如下:

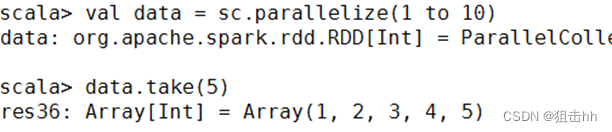
5、使用take()方法查询某几个值
- take(N)方法用于获取RDD的前N个元素,返回数据为数组。
- take()与collect()方法的原理相似,collect()方法用于获取全部数据,take()方法获取指定个数的数据。
获取RDD的前5个元素,操作如下:
6、使用union()方法合并多个RDD
union()方法是一种转换操作,用于将两个RDD合并成一个,不进行去重操作,而且两个RDD中每个元素中的值的个数、数据类型需要保持一致。
使用union()方法合并两个RDD,操作如下:

7、使用filter()方法进行过滤
- filter()方法是一种转换操作,用于过滤RDD中的元素。
- filter()方法需要一个参数,这个参数是一个用于过滤的函数,该函数的返回值为Boolean类型。
- filter()方法将返回值为true的元素保留,将返回值为false的元素过滤掉,最后返回一个存储符合过滤条件的所有元素的新RDD。
创建一个RDD,并且过滤掉每个元组第二个值小于等于1的元素,操作如下:

8、使用distinct()方法进行去重
distinct()方法是一种转换操作,用于RDD的数据去重,去除两个完全相同的元素,没有参数。
创建一个带有重复数据的RDD,并使用distinct()方法去重,操作如下:

5、使用简单的集合操作
Spark中的集合操作常用方法(转换操作)
| 方法 | 描述 |
| union() | 参数是RDD,合并两个RDD的所有元素 |
| intersection() | 参数是RDD,求出两个RDD的共同元素 |
| subtract() | 参数是RDD,将原RDD里和参数RDD里相同的元素去掉 |
| cartesian() | 参数是RDD,求两个RDD的笛卡儿积 |
转换方法:
1、intersection()方法
intersection()方法用于求出两个RDD的共同元素,即找出两个RDD的交集,参数是另一个RDD,先后顺序与结果无关。
创建两个RDD,其中有相同的元素,通过intersection()方法求出两个RDD的交集,操作如下:

2、subtract()方法
subtract()方法用于将前一个RDD中在后一个RDD出现的元素删除,可以认为是求补集的操作,返回值为前一个RDD去除与后一个RDD相同元素后的剩余值所组成的新的RDD。两个RDD的顺序会影响结果。
创建两个RDD,分别为rdd1和rdd2,包含相同元素和不同元素,通过subtract()方法求rdd1和rdd2彼此的补集,操作如下:

3、 cartesian()方法
cartesian()方法可将两个集合的元素两两组合成一组,即求笛卡儿积。
创建两个RDD,分别有4个元素,通过cartesian()方法求两个RDD的笛卡儿积,操作如下:

6、了解键值对RDD
Spark的大部分RDD操作都支持所有种类的单值RDD,但是有少部分特殊的操作只能作用于键值对类型的RDD。
顾名思义,键值对RDD由一组组的键值对组成,这些RDD被称为PairRDD。PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口。
例如,PairRDD提供了reduceByKey()方法,可以分别规约每个键对应的数据,还有join()方法,可以把两个RDD中键相同的元素组合在一起,合并为一个RDD。
有很多种创建键值对RDD的方式,很多存储键值对的数据格式会在读取时直接返回由其键值对组成的PairRDD。
当需要将一个普通的RDD转化为一个PairRDD时可以使用map函数来进行操作,传递的函数需要返回键值对,操作如下:

1、使用键值对RDD的keys和values方法
键值对RDD,包含键和值两个部分。
Spark提供了两种方法,分别获取键值对RDD的键和值。
- keys方法返回一个仅包含键的RDD。
- values方法返回一个仅包含值的RDD。

2、 使用键值对RDD的reduceByKey()方法
当数据集以键值对形式展现时,合并统计键相同的值是很常用的操作。
reduceByKey()方法用于合并具有相同键的值,作用对象是键值对,并且只对每个键的值进行处理,当RDD中有多个键相同的键值对时,则会对每个键对应的值进行处理。
reduceByKey()方法需要接收一个输入函数,键值对RDD相同键的值会根据函数进行合并并且创建一个新的RDD作为返回结果,操作如下:

3、使用键值对RDD的reduceByKey()方法
在进行处理时,reduceByKey()方法将相同键的前两个值传给输入函数,产生一个新的返回值,新产生的返回值与RDD中相同键的下一个值组成两个元素,再传给输入函数,直到最后每个键只有一个对应的值为止。reduceByKey()方法不是一种行动操作,而是一种转换操作,操作如下:

7、连接操作
1、使用join()方法连接两个RDD
(1)join()方法
join()方法用于根据键对两个RDD进行内连接,将两个RDD中键相同的数据的值存放在一个元组中,最后只返回两个RDD中都存在的键的连接结果。
例如,在两个RDD中分别有键值对(K,V)和(K,W),通过join()方法连接会返回(K,(V,W))。
创建两个RDD,含有相同键和不同的键,通过join()方法进行内连接,操作如下:

(2)rightOuterJoin()方法
rightOuterJoin()方法用于根据键对两个RDD进行右外连接,连接结果是右边RDD的所有键的连接结果,不管这些键在左边RDD中是否存在。
在rightOuterJoin()方法中,如果在左边RDD中有对应的键,那么连接结果中值显示为Some类型值;如果没有,那么显示为None值。

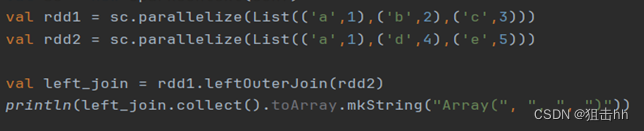
(3)leftOuterJoin()方法
leftOuterJoin()方法用于根据键对两个RDD进行左外连接,与rightOuterJoin()方法相反,返回结果保留左边RDD的所有键。

(4)fullOuterJoin()方法
fullOuterJoin()方法用于对两个RDD进行全外连接,保留两个RDD中所有键的连接结果。
2、使用zip()方法组合两个RDD
zip()方法用于将两个RDD组合成键值对RDD,要求两个RDD的分区数量以及元素数量相同,否则会抛出异常。
将两个RDD组合成Key/Value形式的RDD,这里要求两个RDD的partition数量以及元素数量都相同,否则会抛出异常。
3、使用combineByKey()方法合并相同键的值
- combineByKey()方法是Spark中一个比较核心的高级方法,键值对的其他一些高级方法底层均是使用combineByKey()方法实现的,如groupByKey()方法、reduceByKey()方法等。
- combineByKey()方法用于将键相同的数据聚合,并且允许返回类型与输入数据的类型不同的返回值。
- combineByKey()方法的使用方式如下。
combineByKey(createCombiner,mergeValue,mergeCombiners,numPartitions=None)

combineByKey()方法接收3个重要的参数,具体说明如下。
- (1)createCombiner:V=>C,V是键值对RDD中的值部分,将该值转换为另一种类型的值C,C会作为每一个键的累加器的初始值。
- (2)mergeValue:(C,V)=>C,该函数将元素V聚合到之前的元素C(createCombiner)上(这个操作在每个分区内进行)。
- (3)mergeCombiners:(C,C)=>C,该函数将两个元素C进行合并(这个操作在不同分区间进行)。
- 由于合并操作会遍历分区中所有的元素,因此每个元素(这里指的是键值对)的键只有两种情况:以前没出现过或以前出现过。对于这两种情况,3个参数的执行情况描述如下。
- (1)如果以前没出现过,则执行的是createCombiner()方法,createCombiner()方法会在新遇到的键对应的累加器中赋予初始值,否则执行mergeValue()方法。
- (2)对于已经出现过的键,调用mergeValue()方法进行合并操作,对该键的累加器对应的当前值(C)与新值(V)进行合并。
- (3)由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或更多的分区都有对应同一个键的累加器,就需要使用用户提供的mergeCombiners()方法对各个分区的结果(全是C)进行合并。
4、使用lookup()方法查找指定键的值
lookup(key:K)方法作用于键值对RDD,返回指定键的所有值。
三、Spark SQL ---- 结构化数据文件处理
1、了解Spark SQL基本概念
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象结构叫做DataFrame的数据模型(即带有Schema信息的RDD),Spark SQL作为分布式SQL查询引擎,让用户可以通过SQL、DataFrames API和Datasets API三种方式实现对结构化数据的处理。
Spark SQL主要提供了以下三个功能:
- Spark SQL可从各种结构化数据源中读取数据,进行数据分析。
- Spark SQL包含行业标准的JDBC和ODBC连接方式,因此它不局限于在Spark程序内使用SQL语句进行查询。
- Spark SQL可以无缝地将SQL查询与Spark程序进行结合,它能够将结构化数据作为Spark中的分布式数据集(RDD)进行查询。
Spark要想很好地支持SQL,需要完成解析(Parser)、优化(Optimizer)、执行(Execution)三大过程。
2、掌握DataFrame基本操作
Spark SQL 提供了一个抽象的编程数据模型DataFrame,DataFrame 是由 SchemaRDD 发展而来的,从Spark 1.3.0天开始,SchemaRDD更名为DataFrame。 SchemaRDD 直接继承自RDD,而Data Frame 则自身实现RDD 的绝大多数功能。可以将Spark SQL的 DataFrame理解为一个分布式的Row对象的数据集合,该数据集合提供了由列组成的详细模式信息。
1、创建DataFrame对象
DataFrame可以通过结构化数据文件、外部数据库、Spark计算过程中生成的 RDD Hive 中的表进行创建。不同数据源的数据转换成DataFrame的方式也不同。
(1)、通过结构化数据文件创建DataFrame
一般情况下,结构化数据文件存储在HDFS中,较为常见的结构化数据文件是Parquet文件或 JSON 文件。Spark SQL可以通过load()方法将HDFS上的结构化文件数据转换为 DataFrame,load()方法默认导入的文件格式是Parquet,代码如下:
val dfUsers = spark.read.load("/user/root/sparkSql/users.parquet")
若加载JSON格式的文件数据,将其转换为DataFrame,则还需要使用format()方法,如代码下:
val dfPeople = spark.read.format("json").load("/user/root/sparkSql/people.json")
读者也可以直接使用json()方法将 JSON文件数据转换为DataFrame,如代代码下:
val dfPeople - spark.read.json("/user/root/sparkSql/people.json")
(2)、通过外部数据库创建DataFrame
Spark SQL还可以通过外部数据库(如MySQL、Oracle数据库)创建DataFrame,使用该方式创建DataFrame需要通过Java数据库互连(JavaDatabase Connectivity,JDBC)连接或开放式数据库互连(Open Database Connectivity,ODBC)连接的方式访问数据库。以 MySQL数据库的表数据为例,将MySQL数据库test中的people表的数据转换为DataFrame.。
读者需要将“user”“password”对应的值修改为实际进入MySQL数据库时的账户名称和密码。
# 设置MySQL的url的地址及端口
val url = "jdbc:mysql://192.168.128.130:3306/test"
#连接 MySQL获取数据库test 中的people 表
val jdbcDF = spark.read.format("jdbc").options( Map("url" -> url,"user" -> "root",
"password" -> "123456",
"dbtable" -> "people")).load()
(3)、通过 RDD 创建 DataFrame
通过RDD数据创建DataFrame有两种方式。
第一种方式是利用反射机制推断RDD模式,首先需要定义一个样例类,因为只有样例类才能被Spark隐式地转换为DataFrame,如代码下:
#定义一个样例类
case class Person(name:String, age:Int)
#读取文件创建 RDD
val data = sc.textFile("/user/root/sparkSql/people.txt").map(_.split(","))
#RDD转成 DataFrame
val people = data.map(p => Person (p(0),p(1) .trim.toInt)).toDF()
第二种方式是采用编程指定Schema的方式将RDD转换成DataFrame,
实现步骤如下:
(1)加载数据创建RDD。
(2)使用StructType创建一个和步骤(1)的RDD中的数据结构相匹配的 Schema。
(3)通过createDataFrame()方法将Schema应用到RDD上,将RDD数据转换成 DataFrame,如代码下:
#创建RDD
val people = sc.textFile("/user/root/sparkSql/people.txt" )
#用structType创建一个数据结构相匹配的 schema
val schemaString = "name age"
import org.apache.spark.sql.Row import org.apache.spark.sql.types.{StructType, StructField, stringType)
val schema - StructType(schemaString.split(" ").map(
fieldName => StructField(fieldName,StringType, true)))
#Schema转成RDD再转成 DataFrame
val rowRDD =people.map(_.split(",")).map(p => Row (p(0),p(1).trim))
val peopleDataFrame =spark.createDataFrame(rowRDD,schema)
(4)、 通过 Hive 中的表创建 DataFrame
通过Hive中的表创建DataFrame,可以使用SparkSession对象。
使用SparkSession对象并调用sq1)方法查询Hive中的表数据并将其转换成DataFrame,如查询test 数据库中的people 表数据并将其转换成DataFrame,如代码下:
# 选择 Hive 中的 test数据库
spark.sql("use test")
# 将Hive中test数据库中的people 表转换成 DataFrame
val people = spark.sql ("select * from people")
2、查看 DataFrame数据
DataFrame的常用方法,具体如下表如示:
| 方法名称 | 相关说明 |
| show() | 查看DataFrame中的具体内容信息 |
| printSchema() | 查看DataFrame的Schema信息 |
| select() | 查看DataFrame中选取部分列的数据及进行重命名 |
| filter() | 实现条件查询,过滤出想要的结果 |
| groupBy() | 对记录进行分组 |
| sort() | 对特定字段进行排序操作 |
1. printSchema:输出数据模式
创建DataFrame对象后,一般会查看DataFrame数据模式。使用printSchema函数可以查看DataFrame数据模式,输出列的名称和类型,代码如下:
movies.printSchema
2、show(): 查看数据
使用show()方法可以查看DataFrame数据,可输入的参数及说明如表
| 方法名称 | 相关说明 |
| show() | 显示前20条记录 |
| show(numRows:Int) | 显示numRows 条记录 |
| show(truncate:Boolean) | 是否最多只显示20个字符,默认为true |
| show(numRows:lnt,truncate:Boolean) | 显示numRows条记录并设置过长字符串的显示格式 |
使用show(方法查看 DataFrame对象movies 中的数据,show()方法与show(true)方查询到的结果一样,只显示前20条记录,并且最多只显示20个字符。如果需要显示所字符,那么需要使用show(false)方法,代码如下:
#显示前20条记录
movies.show ()
#显示所有字符
movies.show(false)
3.first()/head()/take()/takeAsList(): 获取若干条记录
获取 DataFrame若干条记录除了使用showO方法之外,还可以使用first()、head()、take
takeAsList()方法,解释说明如表
| 方法名称 | 相关说明 |
| first() | 获取第一条记录 |
| head(n:Int) | 获取前n条记录 |
| take(n:Int) | 获取前n条记录 |
| takeAsList(n:Int) | 获取前n条记录,并以列表的形式展现 |
分别使用first()、head()、take(、takeAsList()方法查看movies中前几条记录,代码如下:
# 获取第一条记录
movies.first()
# head ()方法获取前3条记录
movies.head (3)
# take()方法获取前3条记录
movies.take(3)
# takeAsList()方法获取前3条数据,并以列表的形式展现
movies.takeAsList(3)
4. collect()/collectAsList(): 获取所有数据
collect()可以查询DataFrame中所有的数据,并返回一个数组,collectAsListO方法和collect()方法类似可以查询DataFrame中所有的数据,但是返回的是列表。代码如下:
#使用co1lect()方法获取数据
movies,collect ()
#使用collectAsList()方法获取数据
movies,collectAsList()
3、掌握DataFrame 查询操作
DataFrame查询数据有两种方法,第一种是将DtaFrame注册成临时表,再通过SQL语句查询数据。第二种方法是直接在DtaFrame对象查询。
| 方法名称 | 相关说明 |
| where()/filter() | 条件查询 |
| select()/selectExpr()/col()/apply() | 查询指定字段的数据信息 |
| limit() | 查询前n条记录 |
| order By()/sort() | 排序查询 |
| groupBy() | 分组查询 |
| join() | 连接查询 |
1、where()/fiter()方法
使用where()或filter()方法可以查询数据中符合条件的所有字段的信息。
(1) where()方法
DataFrame可以使用where(conditionExpr:String)方法查询符合指定条件的数据,参可以使用and 或or。where()方法的返回结果仍然为DataFrame。代码如下:
#使用where查询user对象中性别为女且年龄为18岁的用户信息
val userWhere = user.where("gender = 'F' and age = 18")# 查看查询结果的前3条信息 userWhere.show(3)
(2)filter()方法
DataFrame 还可以使用filter()方法筛选出符合条件的数据, 代码如下:
# 使用 filter()方法查询user 对象中性生别为女并且年龄为18岁的用户信息
val userFilter = user.filter ("g ender = 'F' and age = 18")
# 查看查询结果的前3条信息
userFilter.show(3)
2. select()/selectExpr()/col()/apply()方法
where()和 filter()方法查询的数据包含的是所有字段的信息,但是有时用户只需要查询
部分字段的值即可,DataFrame提供了查询指定字段的值的方法,如select(、selectExprO、 col()和 apply()方法等,用法介绍如下。
(1) select()方法:获取指定字段值
# 使用 select()方法查询user对象中userId及gender 字段的数据
val userSelect = user.select("userId", "gender")
# 查看查询结果的前3条信息
userSelect.show(3)
(2)selectExpr()方法:对指定字段进行特殊处理
在实际业务中,可能需要对某些字段进行特殊处理,如为某个字段取别名、对某个字段的数据进行四舍五入等。DataFrame提供了selectExpr()方法,可以对指定字段取别名或调用 UDF函数对其进行其他处理。selectExpr()方法传入 String 类型的参数,返回一个DataFrame 对象。
(3) col()/apply()方法
col()和apply()方法也可以获取DataFrame指定字段,但只能获取一个字段,并且返回的是一个Column对象。分别使用col()和apply()方法查询user对象中zip字段的数据,代码如下:
#查询 user对象中 zip字段的数据
val userCol = user.col("zip")
#查看查询结果
user.select(userCol).collect
t# 查询 user 对象中zip字段的数据
val userApply = user.apply("zip")
# 查看查询结果
user.select(userApply).collect
3、limit()方法
limit()方法可以获取指定DataFrame数据的前n条记录。不同于take()与 head()方法, limit()方法不是行动操作,因此并不会直接返回查询结果,需要结合show()方法或其他行动操作才可以显示结果。使用limit()方法查查询user对象的前3条记录,并使用show()方法显示查询结果,如代码下:
# 查询 user对象前3条记录
val userLimit = user.limit(3)
# 查看查询结果
userLimit.show()
4、orderBy()/sort()方法
orderBy()方法用于根据指定字段对数据进行排序,默认为升序排序。若要求降序排序, orderBy(方法的参数可以使用“desc("字段段名称")”或“$"字段名称".desc”,也可以在指定字段前面加“-”。使用orderBy()方法根据u serId 字段对 user对象进行降序排序,如代码下:
# 使用 orderBy()方法根据 userId字段对寸user 对象进行降序排序
val userOrderBy = user.orderBy(deesc("userId"))
val userOrderBy = user.orderBy($" userId".desc)
val userOrderBy =u iser.orderBy(-user("userId"))
#查看结果的前3条信息
userOrderBy.show(3)
sort()方法也可以根据指定字段对数据进行排序,用法与orderBy()方法一样。使用 sort()方法根据userId字段对user对象进行升序排序,如代码下:
# 使用sort方法根据userId字段对 us er 对象进行升序排序
val userSort = user.sort(asc("u serId"))
val userSort = user.sort($"user Id".asc)
val userSort = user.sort(user(" userId"))
# 查看查询结果的前3条信息
userSort.show(3)
5、groupBy()方法
使用groupBy()方法可以根据指旨定字段对数据进行分组操作。groupBy(方法的输入参数既可以是String类型型的字段名,也可以是Column对象。
| 方法名称 | 相关说明 |
| max(colNames:String) | 获取分组中指定字段或所有的数值类型字段的最大值 |
| min(colNames:String) | 获取分组中指定字段或所有的数值类型字段的最小值 |
| mean(colNames:String) | 获取分组中指定字段或所有的数值类型字段的平均值 |
| sum(colNames:String) | 获取分组中指定字段或所有的数值类型字段的值的和 |
| count() | 获取分组中的元素个数 |
#根据 gender 字段对user对象进行分组,并计算分组中的元素个数
val userGroupByCount = user.groupBy("gender").count
userGroupByCount.show()
6、join()方法
DataFrame提供了join()方法用于连接两个表。使用如下:
| 方法名称 | 相关说明 |
| join(right:DataFrame) | 返回两个表的笛卡儿积 |
| join(right:DataFrame,joinExprs:Column) | 根据两表中相同的某个字段进行连接 |
| join(right:DataFrame,joinExprs:Column,joinType:String) | 根据两表中相同的某个字段进行连接并指定连接类型 |
使用join(right:DataFrame)方法连接rating和user两个DataFrame数据,如代码下:
#允许笛卡儿积操作
spark.conf.set("spark.sql.crossJoin.enabled", "true")
#使用join(right:DataFrame)方法连接rating和user两个DataFrame数据
val dfjoin = user.join(rating)
#查看前3条记录
dfjoin.show(3)
4、掌握DataFrame输出操作
DataFrame提供了很多输出操作的方法,其中save()方法可以将DataFrame数据保存成文件;saveAsTable()方法可以将DataFrame数据保存成持久化的表,并在Hive的元数据库中创建一个指针指向该表的位置,持久化的表会一直保留,即使Spark程序重启也没有影响,只要连接至同一个元数据服务即可读取表数据。读取持久化表时,只需要用表名作为参数,调用spark.table()方法即可加载表数据并创建DataFrame。
默认情况下,saveAsTable()方法会创建一个内部表,表数据的位置是由元数据服务控制的。如果删除表,那么表数据也会同步册删除。














 477
477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









