






本来参加完国赛后(高教社杯)是不想参加其他数模比赛了,但后面队员给我介绍了MathorCup的含金量,该比赛是由国家一级协会“中国优选法统筹法与经济数学研究会”举办,其第一届会长是华罗庚教授。比赛含金量也是蛮高的,在我们学校算是B类竞赛。
这两天刚比完MathorCup,我们组B题大致思路如下(菜狗思路):
题目如下:



第一问在机器学习的框架下,使用线性回归作为一种算法来解决预测问题。然而直接应用机器学习可能因库存数据量较少而导致误差较大。因此,本问首先使用机器学习对数据进行简单的线性拟合(三次埃尔米特插值),以增强数据的连续性和特征丰富度。完成拟合后,再将数据划分为训练集和测试集,并对其进行机器学习建模和预测。
分析:
要求未来 3 个月 (7 ∼ 9) 内,对 350 个品类每个月的销量和库存进行预测。本问先将附件一给的数据进行预处理,将不同的品类放在不同的 excel 表格中进行检查,确认数据没有异常。然后,由于数据量较少,会造成预测出的结果误差较大。故我们采用分段三次埃尔米特插值,能够创建一份包含两三百行的完整数据集。这样的数据集不仅涵盖了更多的时间点,从而提升了数据的连续性和精度,还显著增加了数据量。最后,使用机器学习进行预测,从而得出答案。
库存量和销量预测可视化如图:
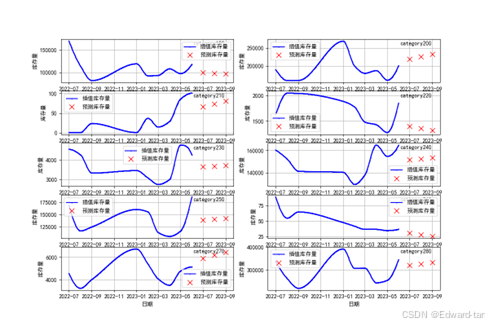
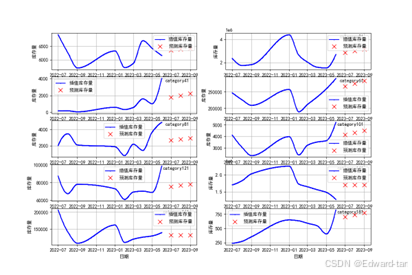
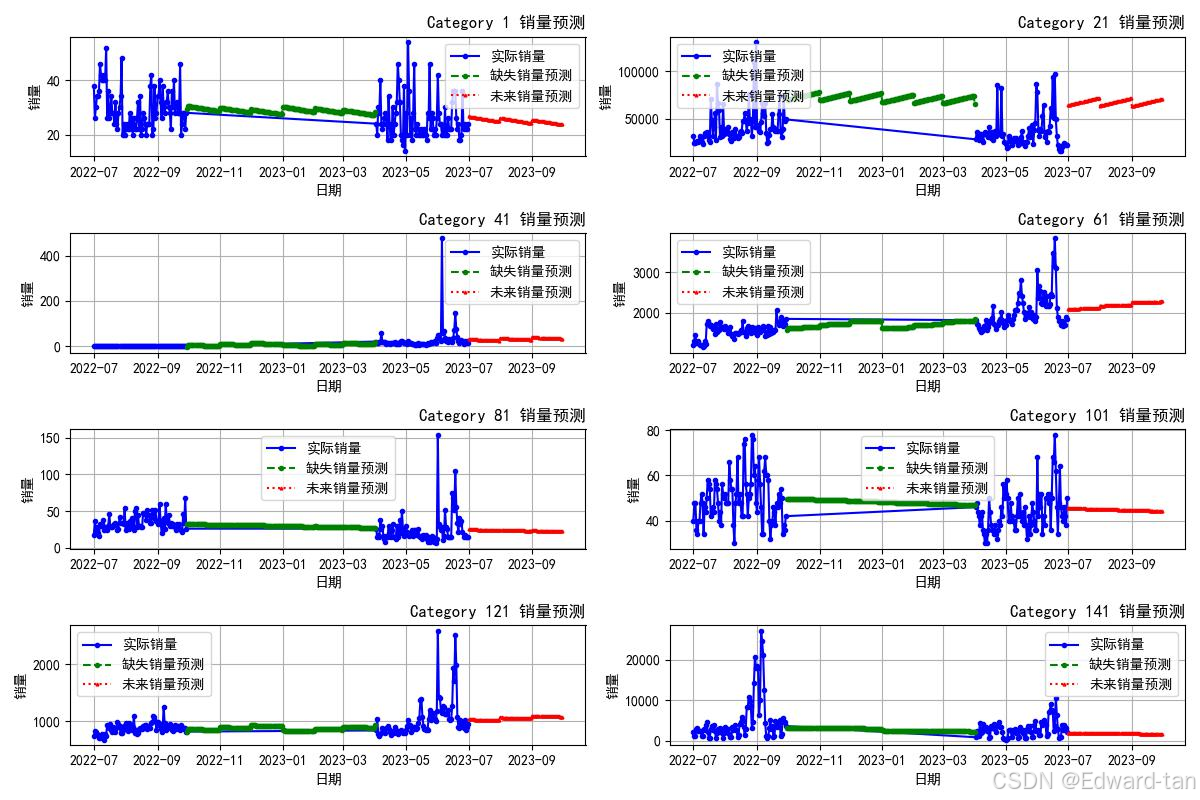
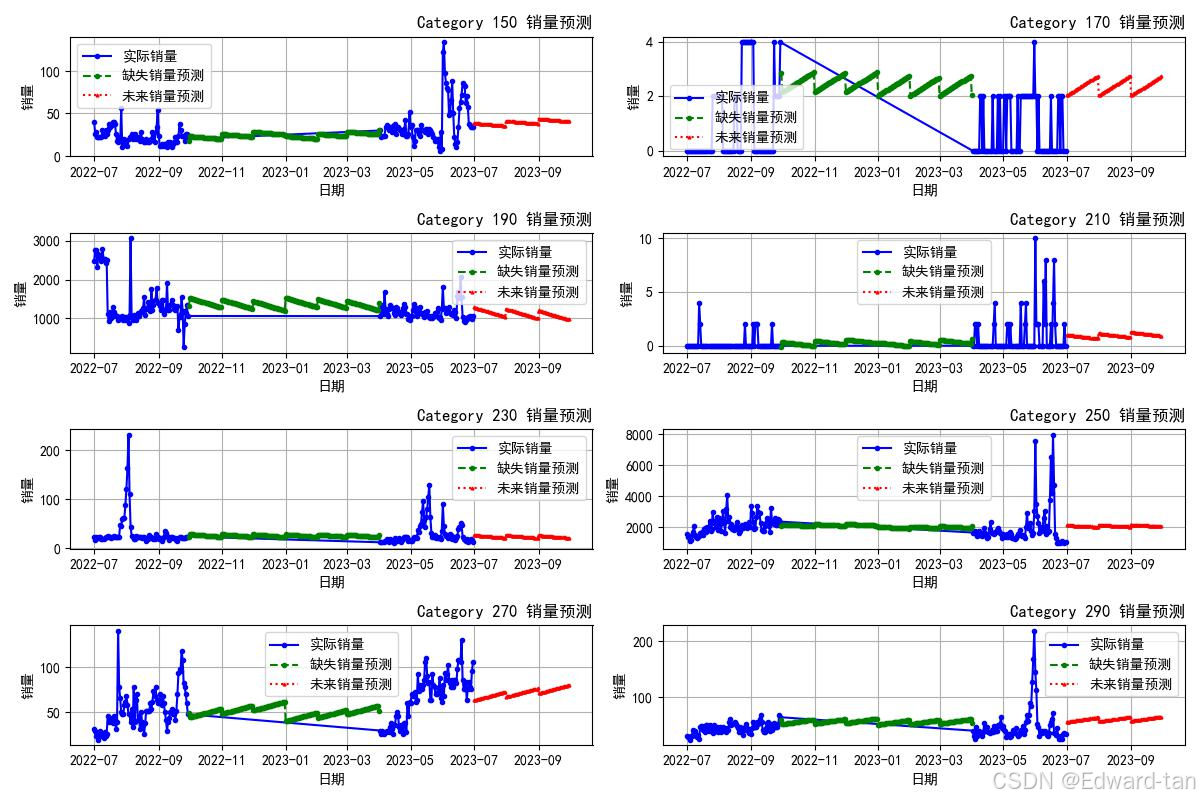
篇幅问题,代码就展示不全,有需要的宝子可以关注并私信领取(包括论文)


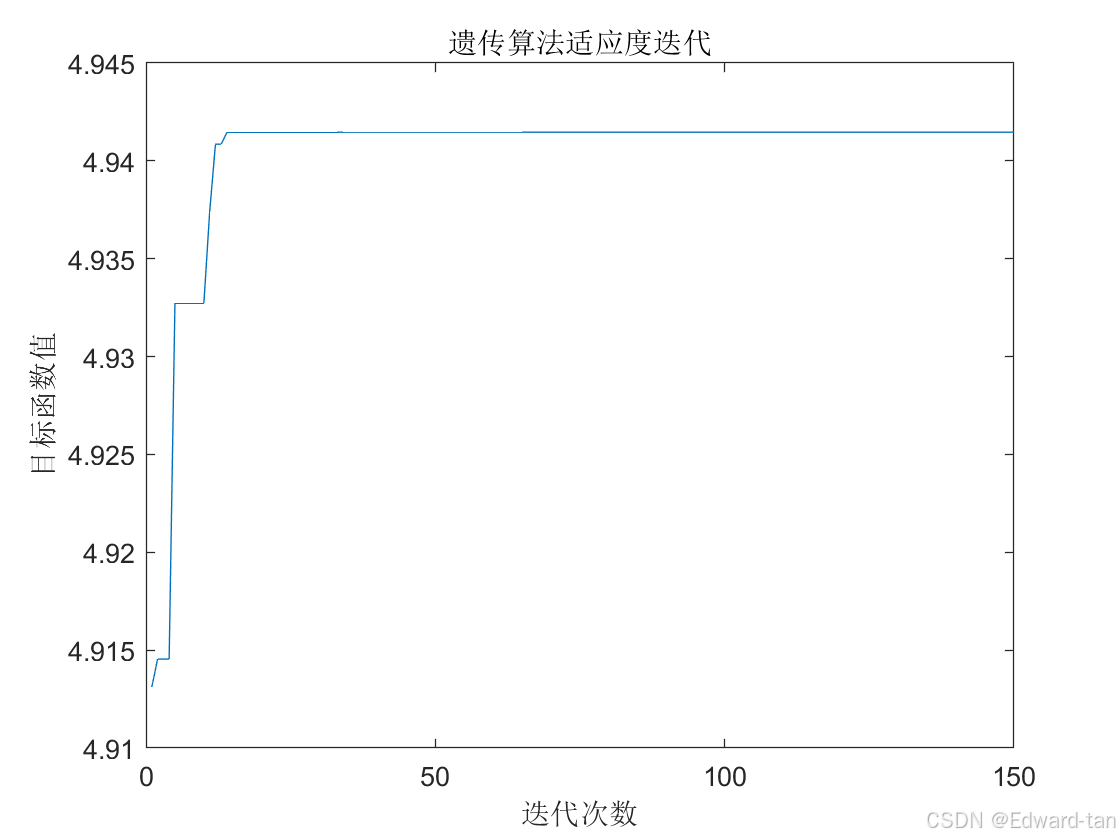
对于问题二,基于问题一预测数据建立分仓方案优化模型。通过对数据的分析,综合考虑 3 个业务目标,建立两个约束条件。业务目标分别为仓容利用率、产能利用率与租仓成本。约束条件为各仓库存量不大于仓容上线与销售量不大于产能上限。通过遗传算法,结合三个业务目标,在满足约束条件的情况下,建立多目标规划模型,对分仓方案进行优化。基于模型的优化结果,遗传算法中最大种群适应度为 4.94147 时,寻得最优的分仓方案。
分析:
本文考虑三个业务目标(仓容利用率,产能利用率,租仓成本),两个约束条件来寻求最优的方案。首先确定三个业务目标,利用问题一预测 2024 年 7 月 1 日的库存量与销售量建立库存量矩阵与销售量矩阵。然后建立变量分仓决策矩阵,根据库存量矩阵与销售量矩阵计算出总库存量,再结合仓容上限得出仓容利用率。同理,可以得出产能利用率。再根据租仓日成本计算出,租仓总成本。然后确定两个约束条件,即每个仓库的库存量不超过仓容上限,销售量不超过产能上限。最后利用遗传算法[3],以 3 个业务目标的综合影响作为适应度函数,在满足两个约束条件[4] 下,优化的种群适应度,但适应度达到最优值时,返回分仓决策矩阵,利用决策矩阵得出最佳分仓方案。

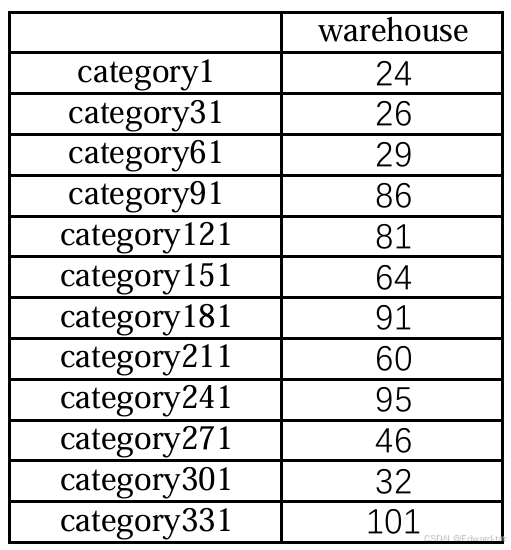
将 python 所求解的数据填充到表中,结果如下图所示:
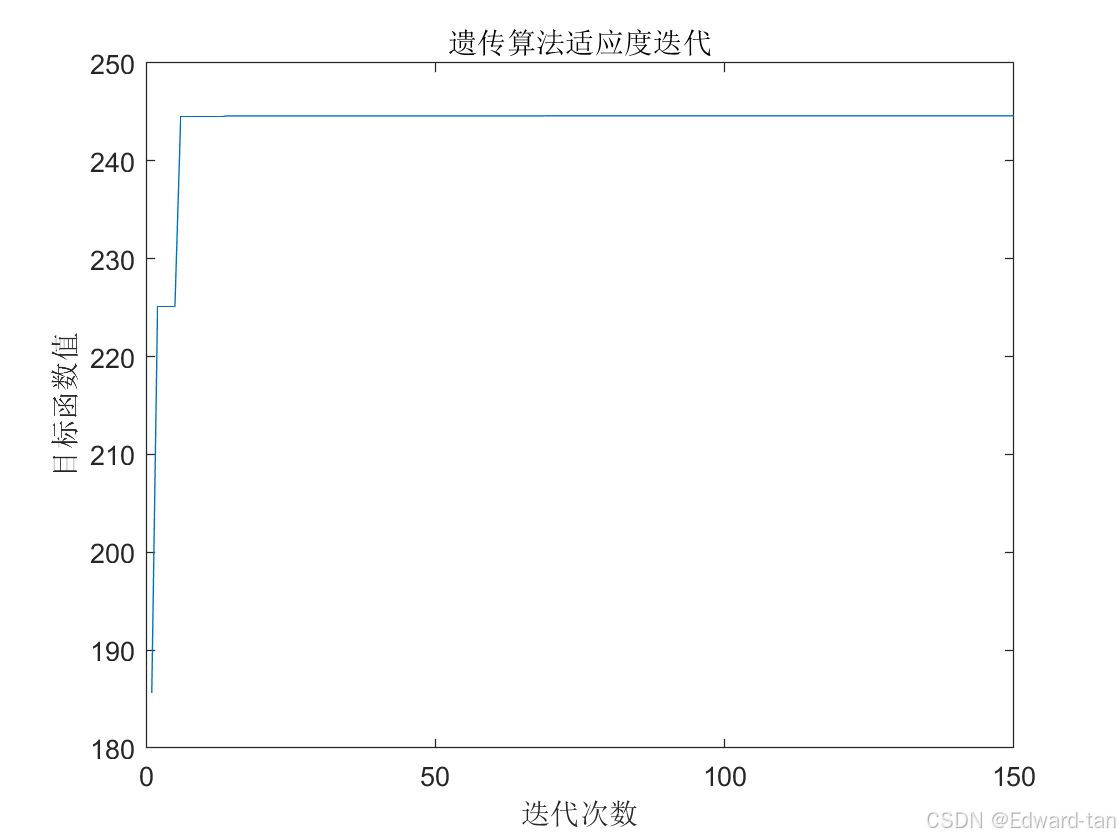
对于问题三,通过对附件 4,附件 5 的数据分析及处理,建立品类的最大关联度的评价模型,并将其作为主要业务目标,再将仓容利用率、产能利用率与租仓成本作为次要业务目标。然后建立约束条件,分别为一品至多三仓、仓库存量不大于仓容上线与销售量不大于产能上限。通过遗传算法,结合 4 个业务目标,3 个约束条件,建立多目标多约束条件的规划模型,对分仓方案进行优化。模型优化结果表示,在种群适应度为30.7586 时,寻得最优分仓方案。
分析:
问题三要求在放开一品一仓(一品不超过三仓)的情况下以最大品类关联度为主要业务目标,建立分仓方案优化模型。问题二的基础上,将关联度作为主要业务目标,其他三个业务作为次元业务目标。首先确定品类最大关联度,对自变量变量分仓决策矩阵进行分析,得出因变量关联度决策矩阵,再通过整理附件 4 得出各个品类的原始关联度矩阵,将品类的等级与件型也作为关联度矩阵的影响指标,最终得到综合关联度矩阵。然后通过关联度决策矩阵与综合关联度矩阵,就可以得到品类最大关联度,将其设置为遗传算法适应度函数中的主要目标,再满足三个约束条件的情况下,同问题二,得到最优分仓方案。

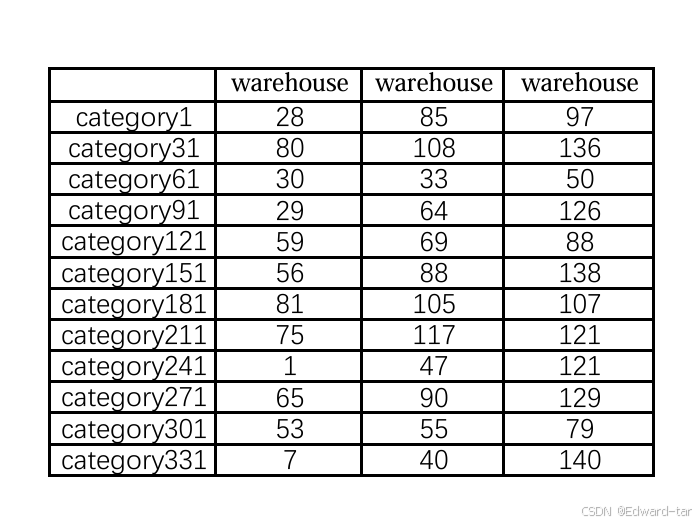
将 python 所求解的数据填充到表中结果如下图所示:
有需要完整论文及完整代码的宝子可以关注并点赞,私信我,我一一发。。。。。。。。。

















 2273
2273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









