







一、导入依赖的库
# 忽视警告:Python 内置的 warnings 模块用于控制警告信息的显示和过滤。
import warnings
warnings.simplefilter('ignore')
# 数据处理库
import numpy as np
import pandas as pd
# 数据可视化库
import matplotlib.pyplot as plt
import seaborn as sns 二、数据探索
1、领域认知

 通过查阅医学文献,可以获取医学专家在长期研究和实践中总结出的与心脏病相关的重要因素。在分析心脏病预测数据时,依据文献确定这些关键因素,并着重关注与之对应的数据集特征,能使数据分析更具针对性和专业性。而且如果模型在训练后确实具备一定的预测能力,那么基于医学文献确定并重点关注的数据特征,很可能在模型中起到关键作用。
通过查阅医学文献,可以获取医学专家在长期研究和实践中总结出的与心脏病相关的重要因素。在分析心脏病预测数据时,依据文献确定这些关键因素,并着重关注与之对应的数据集特征,能使数据分析更具针对性和专业性。而且如果模型在训练后确实具备一定的预测能力,那么基于医学文献确定并重点关注的数据特征,很可能在模型中起到关键作用。
2、数据认知及预处理
data = pd.read_csv("./data/heart.csv")
data.head()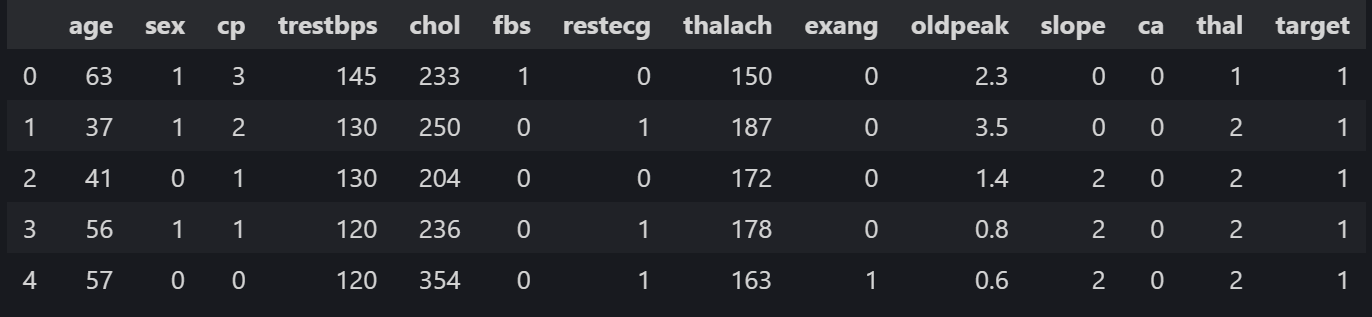
1、数据基本信息:
# 显示数据规模
print(data.shape)
# 显示所有的列名
print(data.columns)
# 显示描述统计信息
print(data.describe())
# 显示列名、空值数量、数据类型
print(data.info())
# 输出:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 303 entries, 0 to 302
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 age 303 non-null int64
1 sex 303 non-null int64
2 cp 303 non-null int64
3 trestbps 303 non-null int64
4 chol 303 non-null int64
5 fbs 303 non-null int64
6 restecg 303 non-null int64
7 thalach 303 non-null int64
8 exang 303 non-null int64
9 oldpeak 303 non-null float64
10 slope 303 non-null int64
11 ca 303 non-null int64
12 thal 303 non-null int64
13 target 303 non-null int64
dtypes: float64(1), int64(13)
memory usage: 33.3 KB
None
2、区分离散变量与连续变量
离散变量:
sex:通常表示性别,一般用整数编码,比如 0 代表女性,1 代表男性,取值是明确的类别。
cp:胸痛类型(chest pain type),通过整数编码不同的胸痛类别,例如 1 代表典型心绞痛,2 代表非典型心绞痛等,其取值是有限个类别对应的整数。
fbs:空腹血糖(fasting blood sugar),一般以 0 和 1 编码表示空腹血糖是否大于 120mg/dl ,只有两个离散的取值,属于离散变量。
restecg:静息心电图结果(resting electrocardiographic results),用整数来编码不同的心电图表现类别,取值为特定的几个类别对应的整数,属于离散变量。
exang:运动诱发心绞痛(exercise - induced angina),常以 0 和 1 编码表示是否出现运动诱发心绞痛,只有两个离散取值,是离散变量。
slope:运动心电图 ST 段斜率,以整数编码不同的斜率类别,取值为有限个类别对应的整数,属于离散变量。
ca:通过造影检查发现的主要血管(0 - 3 )有荧光染色的血管数量,血管数量只能是 0、1、2、3 这样的整数,取值不连续,属于离散变量。
thal: thalassemia(地中海贫血相关指标,推测此处含义 ),一般用整数编码不同的类型或状态,取值是有限个类别对应的整数,属于离散变量。
target:作为分类目标变量,判断疾病是否存在,用整数编码不同的分类结果,是离散变量
连续变量:
age:年龄是可以在一定范围内连续取值的,比如从婴儿到老年人的年龄范围,是连续变量。
trestbps:静息血压(resting blood pressure),血压值在一定区间内取任意值,是连续变量。
chol:胆固醇(cholesterol)水平,胆固醇数值在合理范围内可以有连续的取值,属于连续变量。
thalach:最高心率(maximum heart rate achieved),心率值在一定范围内可连续变化。
oldpeak:运动相对于休息引起的 ST 段压低(ST - depression induced by exercise relative to rest),以浮点数表示,可在一定范围内连续取值,属于连续变量。
或者用代码识别:
# 以下识别方法比较简单,但是并不准确
# 方法 1
discrete_list = []
continuous_list = []
for col in data.columns.tolist():
if data[col].dtype != object:
continuous_list.append(col)
else:
discrete_list.append(col)
print(f"离散变量有{discrete_list}")
print(f"连续变量有{continuous_list}")
# 方法 2
continuous_list = data.select_dtypes(exclude=object).columns.tolist()
discrete_list = data.select_dtypes(include=object).columns.tolist()
print(f"离散变量:{discrete_list}")
print(f"连续变量:{continuous_list}")
data.columns返回的是一个pandas.Index对象,它代表了数据框的列标签。当使用tolist()方法时,会把pandas.Index对象转换为 Python 列表。
3、缺失值计数及补全
# 对缺失值进行计数,若发现某个特殊值(如 -1、NaN 等)出现的频次较高,可能
意味着是缺失值的一种表示方式,后续可以对其进行合适的处理,如删除、填充等。
另外在机器学习中,对于分类变量常常需要进行编码处理。了解每个类别值的出现频
次,有助于决定采用何种编码方式。
missing_values = data.isnull().sum()
print("每列缺失值数量:")
print(missing_values)
# 平均数补全
for col in continuous_list:
if data[col].isnull().sum() > 0:
col_mean = data[col].mean()
data[col] = data[col].fillna(col_mean)
# 众数补全
for col in discrete_list:
if data[col].isnull().sum() > 0:
col_mode = data[col].mode()
col_mode = col_mode[0]
data[col] = data[col].fillna(col_mode)
print(data)!!!此处没有缺失值,如果有要先补全。如果先进行编码(如独热编码 ),再填充缺失值,可能会影响数据的统计特性。因为填充缺失值时,可能会依据整列数据的均值或中位数计算,而编码后的额外列可能干扰这种计算。这样能确保在编码前数据中的数值型特征处于相对完整、符合原始分布的状态,避免缺失值对编码后数据结构和后续模型训练的潜在影响。
4、离散特征独热编码
data = pd.get_dummies(data, columns=discrete_list, drop_first=True)
print(data.columns)
drop_first=True 的作用:
假设你有一个类别特征 “颜色”,取值有 “红”“绿”“蓝”。使用 get_dummies 进行独热编码时,如果不设置 drop_first,会生成三个新的二进制列,“红” 列在是红色时为 1,其他为 0;“绿” 列和 “蓝” 列同理。但这三个列之间存在线性关系,比如知道了 “红” 和 “绿” 列的值,就能推出 “蓝” 列的值(因为只有这三种颜色,不是红和绿就是蓝)。而设置 drop_first = True 后,会只生成两个列,比如去掉 “蓝” 列。这样就消除了这种完全的线性相关性,降低了多重共线性的风险,让模型更稳定、结果更可靠。简单来说,drop_first 通过减少冗余信息,让模型更健壮、高效且易于解释 。
三、数据可视化
# 设置全局字体为中文字体 (如: SimHei)
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决负号'-'显示为方块(乱码)的问题
plt.rcParams['axes.unicode_minus'] = False
# 设置可视化风格
sns.set(palette = 'pastel', rc = {"figure.figsize": (10,5), # 图形大小、
"axes.titlesize" : 14, # 标题文字尺寸
"axes.labelsize" : 12, # 坐标轴标签文字尺寸
"xtick.labelsize" : 10, # X轴刻度文字尺寸
"ytick.labelsize" : 10 }) # Y轴刻度文字尺寸
# sns.set() 是 seaborn 库中用于设置绘图风格和各种参数的函数。通过调用这个函数,可以
一次性对图表的多个方面进行配置,从而使生成的图表具有统一的外观和风格。
单特征分布情况
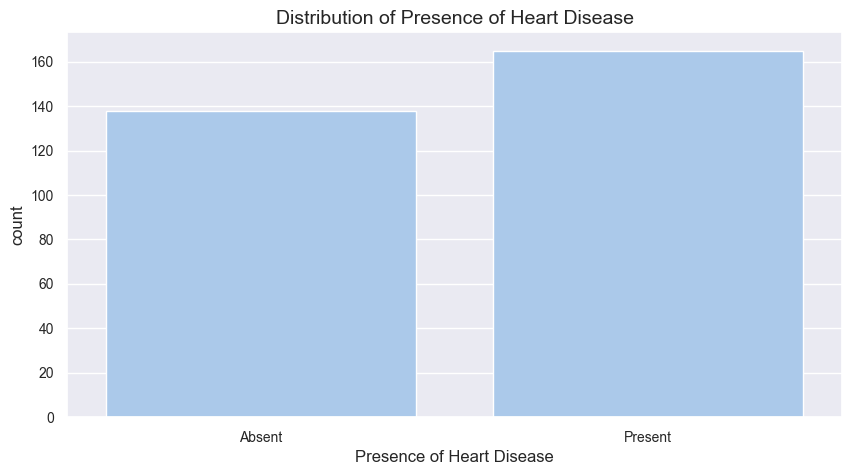
1、患者确诊数量
# 统计"target"列各类别的总数
data.target.value_counts()
# 输出:
target
1 165
0 138
Name: count, dtype: int64说明各类别样本数量相近,在分类任务中,每个类别都有足够的数据供模型学习,模型不会因为某类数据过少而难以捕捉其特征。即若 “患病” 和 “未患病” 两类样本数量差不多,模型就有较为平等的机会去学习患病和未患病个体的特征,从而做出更准确的判断。这个层面讲,数据集相对均衡。
# 绘制计数图
a = sns.countplot(x = 'target', data = data)
a.set_title('Distribution of Presence of Heart Disease') # 设置图形标题
a.set_xticklabels(['Absent', 'Present']) # 设置条形标签
plt.xlabel("Presence of Heart Disease") # 设置X轴标签
# 显示图形
plt.show()
2、患者年龄分布
创建计数图可以方便查看此数据集中包含的患者的年龄以及每个年龄出现的频率。
g = sns.countplot(x = 'age', data = data) # 绘制计数图,其中x为age,数据为dt
g.set_title('Distribution of Age') # 设置图形标题
plt.xlabel('Age') # 设置X轴标签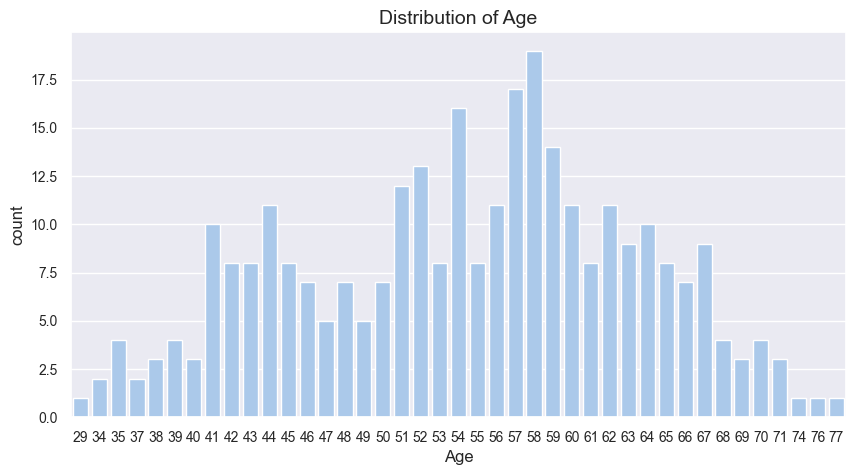 3、患者性别分布
3、患者性别分布
data.sex.value_counts()
# 输出:
sex
1 207
0 96
Name: count, dtype: int64# hue 是 seaborn 库中用于分类绘图的一个参数,按指定变量sex对数据进行分组,
为不同组别的数据条赋予不同颜色
b = sns.countplot(x = 'target', data = dt, hue = 'sex')
# legend:以female/male作为标签,在图形中嵌入图例
plt.legend(['Female', 'Male'])
b.set_title('Distribution of Presence of Heart Disease by Sex')
b.set_xticklabels(['Absent', 'Present'])
# 显示图形
plt.show() 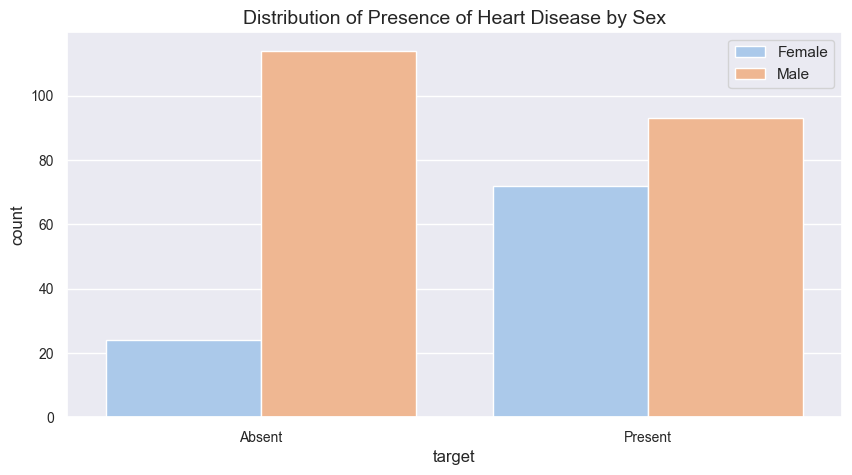
4、诱因分析
# 可视化患者血清胆固醇浓度分布
sns.distplot(data['chol'].dropna(), kde=True, color='darkblue', bins=40)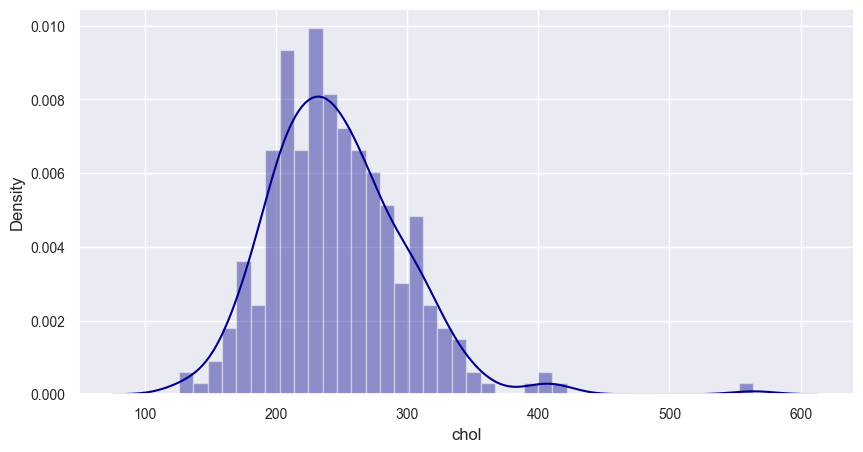
-
dropna()方法用于移除chol列中的缺失值(NaN),确保参与绘图的数据都是有效的。 -
kde=True表示在绘制直方图的同时,绘制核密度估计曲线。核密度估计曲线可以帮助我们更直观地了解数据的分布形状,它是对数据概率密度函数的一种非参数估计。 -
color='darkblue'该参数用于指定直方图和核密度估计曲线的颜色为深蓝色(darkblue)。 -
bins参数用于指定直方图的区间数量。这里设置为 40,表示将数据的取值范围划分为 40 个区间,每个区间对应直方图中的一个柱子。bins的数量会影响直方图的形状和细节程度,数量越多,直方图越精细,但可能会导致数据过于分散;数量越少,直方图越平滑,但可能会丢失一些细节信息。
# 可视化患者(入院时)的静息血压分布
sns.distplot(data['trestbps'].dropna(), kde=True, color='darkgreen', bins=10)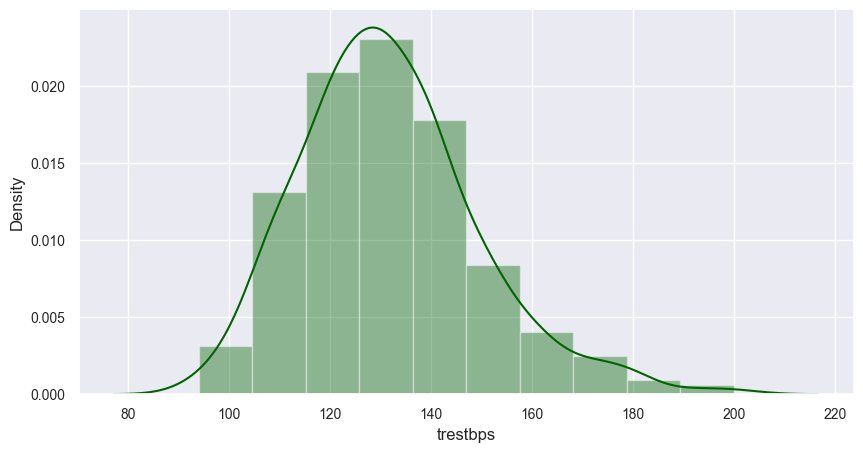
在 seaborn 库中,displot的纵轴有时会显示为 density(密度)而非简单的频数。当比较多个不同样本量的数据集时,使用频数可能会因为样本量的差异而导致图形难以直观比较。而使用密度绘图,由于密度是标准化的,不受样本量的影响,能够更清晰地展示两个数据集的分布形状差异。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









