







数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)
图片数量(jpg文件个数):4662
标注数量(xml文件个数):4662
标注数量(txt文件个数):4662
标注类别数:7
标注类别名称:["violation crossing ","violation crosswalk","violation helmet","violation normal","violation passenger","violation pedestrian","violation trafficlight"]
数据集编号:mbd.pub/o/bread/Zp6Ym59p
交通违规行为,具体包括:violation crossing(越线违规)、violation crosswalk(人行道违规)、violation Helmet(未佩戴头盔违规)、violation normal(正常行为)、violation passenger(乘客违规)、violation pedestrian(行人违规)以及violation trafficlight(交通信号灯违规)。
每个类别标注的框数:
violation crossing 框数 = 910
violation crosswalk框数 = 1070
violation helmet 框数 = 458
violation normal 框数 = 640
violation passenger 框数 = 437
violation pedestrian 框数 = 1146
violation trafficlight 框数 = 278
总框数:4939
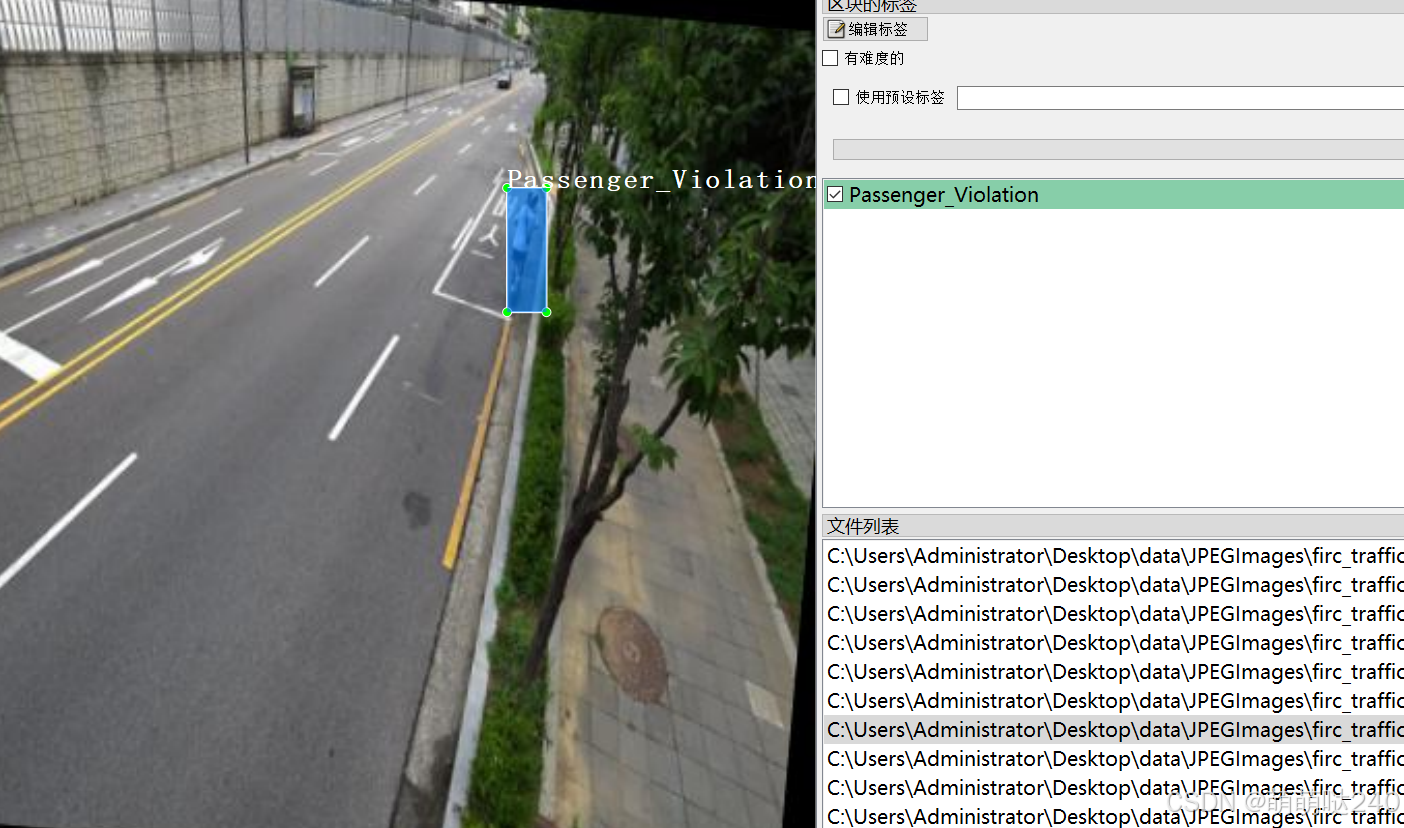
使用标注工具:labelImg
标注规则:对类别进行画矩形框
重要说明:暂无
特别声明:本数据集不对训练的模型或者权重文件精度作任何保证,数据集只提供准确且合理标注
图片预览:
标注例子:

















 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









