









目录
0 引言
猎豹算法(cheetah optimizer,CO)是学者MohammadAminAkbari于2022年提出一种自然启发算法,该算法主要模拟猎豹捕食过程,引入随机参数提高模型全局收敛性。

1 数学模型
CO算法的数学模型构建是以猎豹三种主要捕食策略进行,即搜索、静候和攻击。此外,还引入了离开猎物并返回家园的策略,以提高所提框架的人口多样化、收敛性能和鲁棒性,具体模型如下:
1)搜索策略:猎豹通过两种方式寻找猎物;一种是坐着或站着时扫描环境,另一种是主动巡逻周围区域。在狩猎期间,根据猎物的条件、区域的覆盖范围和猎豹自身的条件,猎豹可能会选择这两种搜索模式的连锁。其位置更新的表达式为:

式中中,Xi t+1 ,j和Xi t ,j分别表示猎豹i在第j次排列中的下一个位置和当前位置。t表示当前捕猎时间,T是最大捕猎时间长度。rˆi−,1,j和αi t ,j分别是猎豹i在第j次排列中的随机化参数和步长。第二项是随机化项,其中随机化参数rˆi,j是来自标准正态分布的正态分布随机数。
2)静候策略:在搜索模式下,猎物可能会暴露在猎豹的视野中。在这种情况下,猎豹的每一个动作都可能让猎物意识到它的存在,从而导致猎物逃跑。为了避免这种担忧,猎豹可能会决定伏击(通过躺在地上或藏在灌木丛中)以接近猎物。因此,在这种模式下,猎豹会保持原位,等待猎物靠近这种行为可以建模如下:

式中各参数意义同上。该策略能够避免CO过早收敛。
3)攻击策略:猎豹攻击猎物时依赖两个关键因素:速度和灵活性。当猎豹决定发起攻击时,它会全速冲向猎物。过了一会儿,猎物察觉到猎豹的攻击并开始逃跑。猎豹迅速用锐利的眼睛沿着拦截路径追击猎物,猎豹利用速度和灵活性在这阶段捕获猎物。在群体狩猎方法中,每只猎豹可能会根据逃跑的猎物和领头或邻近猎豹的位置调整自己的位置。简而言之,这些猎豹的所有攻击战术可以数学定义如下:
 式中XB tj表示种群数量,j是猎物在排列rˇi,j中的当前位置,βi t ,j分别是与猎豹j相关的转向因子和互动因子,转向因子rˇi,j是一个随机数,在本文中等于下式,是来自标准正态分布的正态随机数。该因子反映了猎豹在捕食模式下的急转弯。
式中XB tj表示种群数量,j是猎物在排列rˇi,j中的当前位置,βi t ,j分别是与猎豹j相关的转向因子和互动因子,转向因子rˇi,j是一个随机数,在本文中等于下式,是来自标准正态分布的正态随机数。该因子反映了猎豹在捕食模式下的急转弯。
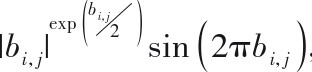
4)离开猎物,返回家园:随机选取一种猎物进行随机生成,进而更最佳猎豹对比,提高随机性
2 优化方式
前篇对支持向量机(支持向量机原理及Matlab代码-CSDN博客)原理讲解,从支持向量机模型运算过程中,可以了解到模型高维映射核函数参数g和处罚因子c对模型预测结果影响最为重要。因此结合上述CO原理介绍,可以将支持向量机的超参数作为猎豹和猎物的个体位置,每一个种群位置对应支持向量机的预测值,将这个预测值作为适应度来模拟猎豹捕食策略,进而进行下一迭代。
3 MATLAB代码
3.1 伪代码

3.2 CO主函数代码
%% 初始化参数
t = 0; % 狩猎时间计数器
it = 1; % 迭代计算器
T = ceil(D/10)*60; % 狩猎时间
FEs = 0; % 适应度函数计数器
while FEs <= MaxIt
m = 1+randi (ceil(n/2));
i0 = randi(n,1,m);% 随机选择猎豹成员
for k = 1 : m % 每个成员执行以下任务
i = i0(k);
% 定义成员io邻居
if k == length(i0)
a = i0(k-1);
else
a = i0(k+1);
end
X = pop(i).Position; % 第 i 只猎豹的当前位置
X1 = pop(a).Position; % 邻居a的位置
Xb = BestSol.Position; % 领导位置
Xbest = X_best.Position;% 最佳位置
kk=0;
% 执行选择重组种群,可能会提高 CO精度
if i<=2 && t>2 && t>ceil(0.2*T+1) && abs(BestCost(t-2)-BestCost(t-ceil(0.2*T+1)))<=0.0001*Globest(t-1)
X = X_best.Position;
kk = 0;
elseif i == 3
X = BestSol.Position;
kk = -0.1*rand*t/T;
else
kk = 0.25;
end
if mod(it,100)==0 || it==1
xd = randperm(numel(X));
end
Z = X;
%
for j = xd % 选择任意一组安排
r_Hat = randn;% R随机化参数, 可用Eq (1)
r1 = rand;
if k == 1 % 领导者的步长(假定 k==1 与领导者编号相关联)
alpha = 0.0001*t/T.*(ub(j)-lb(j)); % 步长,公式 可用(1)
else % 成员步长
alpha = 0.0001*t/T*abs(Xb(j)-X(j))+0.001.*round(double(rand>0.9));%成员步长,可用公式 (1)
end
r = randn;
r_Check = abs(r).^exp(r/2).*sin(2*pi*r); % 标准正态分布的正态分布随机数,可用Eq(3)
beta = X1(j)-X(j); % 猎豹之间或猎豹与领导者在捕获模式下的互动系数,可用Eq(3)
h0 = exp(2-2*t/T);
H = abs(2*r1*h0-h0);
r2 = rand;
r3 = kk+rand;
if r2 <= r3
r4 = 3*rand;
if H > r4
% 搜索策略
Z(j) = X(j)+r_Hat.^-1.*alpha; % 搜索, Eq(1)
else
% 攻击策略
Z(j) = Xbest(j)+r_Check.*beta; % 攻击, Eq(3)
end
else
Z(j) = X(j); % 坐等, Eq
end
end
% 更新成员 i 的解
% 边界检查
xx1=find(Z<lb);
Z(xx1)=lb(xx1)+rand(1,numel(xx1)).*(ub(xx1)-lb(xx1));
xx1=find(Z>ub);
Z(xx1)=lb(xx1)+rand(1,numel(xx1)).*(ub(xx1)-lb(xx1));
% 适应度比较
NewSol.Position = Z;
NewSol.Cost = SYD(NewSol.Position,net);
net.trainParam.showWindow = 0;
if NewSol.Cost < pop(i).Cost
pop(i) = NewSol;
if pop(i).Cost < BestSol.Cost
BestSol = pop(i);
end
end
FEs = FEs+1;
end
t = t+1;
% 离开猎物,返回家园
if t>T && t-round(T)-1>=1 && t>2
if abs(BestCost(t-1)-BestCost(t-round(T)-1))<=abs(0.01*BestCost(t-1))
% 更改领导者位置
best = X_best.Position;
j0=randi(D,1,ceil(D/10*rand));
best(j0) = lb(j0)+rand(1,length(j0)).*(ub(j0)-lb(j0));
BestSol.Cost = SYD(best,net);
net.trainParam.showWindow = 0;
BestSol.Position = best; % 领导人的新位置
FEs = FEs+1;
i0 = randi(n,1,round(1*n));
pop(i0(n-m+1:n)) = pop1(i0(1:m)); % 一些种群恢复了最初的位置
pop(i) = X_best; % 将成员 i 替换为猎物
t = 1; % 重置狩猎时间
end
end
it = it +1;
% 更新猎物(全体最佳)位置
if BestSol.Cost<X_best.Cost
X_best=BestSol;
end
BestCost(t)=BestSol.Cost;
CO_Convergence(FEs) = X_best.Cost;
end
end3.3 CO-SVM/SVR
猎豹算法优化支持向量机的回归预测模型和分类模型的MATLAB代码复现:


















 101
101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









