






摘要
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
摘要-联邦学习(FL)已被广泛用于工业5.0中的隐私保护模型更新,并得到了6 G网络的支持。尽管FL具有保护隐私的优势,但它仍然容易受到攻击,对手可以从本地模型中推断出私人数据或操纵中央服务器(CS)以提供伪造的全局模型。目前的隐私保护方法,主要是基于FedAvg算法,无法优化非独立和同分布(非IID)数据的训练效率。本文提出了培训有效的和可验证的聚集(TEVA)的FL来解决这些问题。该方案结合了阈值Paillier同态加密(TPHE),可验证的聚合,和优化的双动量更新机制(OdMum)。TEVA不仅利用TPHE来保护局部模型的隐私,而且通过可验证的聚合机制来确保全局模型的完整性。此外,TEVA还集成了OdMum算法,以有效应对非IID数据带来的挑战,促进模型快速收敛,并显着提高整体训练效率。安全分析表明,TEVA符合隐私保护的要求。大量的实验结果表明,TEVA可以加速模型收敛,同时产生较低的计算和通信开销。
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
主要问题和背景
提示:这里可以添加本文要记录的大概内容:
随着大数据、人工智能和工业信息化的快速发展,工业物联网(IIoT)的应用和工业生产力得到显著提升[1]。在向强调以人为中心和可持续解决方案的工业5.0转型过程中,发展6G网络对增强这些技术至关重要。6G网络[2]承诺提供前所未有的连接性和数据传输速度,这对优化消费电子设备(CEs)性能及促进创新必不可少。然而,将6G网络融入工业5.0也带来了数据隐私和信任挑战。在这一新阶段,CEs通常将私有数据本地存储,导致数据孤岛,阻碍信息共享与协作[3]。欧盟《通用数据保护条例》(GDPR)[4]的实施进一步加剧了这一问题。尽管GDPR强化了隐私保护,但也限制了CEs间的数据共享与协作,影响了工业生产力及工业5.0所需智能CE设备的发展。
为解决数据隐私和孤岛问题,谷歌提出联邦学习(FL)[5],允许多个CEs在不共享数据的情况下协作训练模型。该方法通过避免直接数据传输降低隐私风险[6]。例如,智能家居中的恒温器、摄像头和语音助手通过本地训练模型优化能源使用模式,无需向中央服务器(CS)传输原始数据。工业自动化中,FL可用于预测性维护和提升制造效率,如汽车工厂的机器人可本地学习缺陷组件特征,形成全局模型以提升生产质量,而无需共享敏感数据。
然而,FL引入了新的安全挑战。Zhu等[7]研究表明,从本地模型上传的梯度可推断敏感信息甚至重建原始数据;Zhao等[8]进一步优化了梯度反演攻击。在工业5.0和6G网络下,这一威胁更为显著:6G的超低时延和高吞吐量使FL部署更广泛,但也扩大了攻击面。梯度泄露可能导致工业系统隐私泄露,危及专有数据安全。
现有隐私保护联邦学习(PPFL)方案多依赖差分隐私(DP)[10,11]和安全多方计算(SMC)如同态加密(HE)[12]和秘密共享(SS)[13]。然而,DP会引入噪声降低精度,HE和SS虽不损失精度但计算成本高。此外,多数方案需多轮交互,通信开销大。因此,工业5.0与6G网络下的首要目标是:在保护CEs隐私的同时最小化计算与通信成本。
FL主要分为跨孤岛联邦学习(CsFL)[14]和跨设备联邦学习(CdFL)。工业5.0中,CsFL面临模型异构性和数据异构性(非独立同分布,non-IID)挑战。传统FedAvg算法[17]假设数据为IID,但在non-IID场景下,本地模型差异导致全局模型收敛慢、精度低。工业5.0中CEs需兼顾隐私与个性化,而CsFL设备数较少(2-100台),稳定性更高,但non-IID问题依然突出。因此,第二个目标是设计适应non-IID数据的CsFL算法,实现快速收敛与高精度。
6G与工业5.0使系统更易暴露于外部环境,单点故障(SPOF)风险加剧[18,19]。non-IID数据导致CEs训练时间与结果不一致,可能引发SPOF,影响模型精度与系统稳定性。现有方案如Hadamard积[18]、双线性映射[20]等难以应对non-IID数据。第三个目标是设计支持non-IID数据的可验证全局模型方案。
为此,本文提出TEVA方案,结合阈值Paillier同态加密(TPHE)、优化双动量更新(OdMum)和可验证聚合。TEVA通过OdMum加速收敛,利用TPHE保障隐私,并通过可验证聚合抵御SPOF。主要贡献如下:
TEVA协议:通过TPHE确保本地模型机密性,防止恶意CS窃取数据;可验证聚合防止CEs中途退出。
OdMum算法:结合历史梯度与动量信息,减少振荡,提升non-IID数据下的收敛速度与公平性。
可验证聚合:基于双线性映射构造辅助与验证标签,支持独立验证全局模型正确性。
安全分析与实验验证:TEVA可抵御恶意CS篡改和共谋攻击,实验证明其高效收敛与合理开销。

简单来说:第一 隐私保护(分片) 第二 优化训练 第三 可验证
提示:以下是本篇文章正文内容,下面案例可供参考
背景内容
工业5.0的目标与6G网络的支持
工业5.0旨在通过人机协作提升生产线的智能化与人性化。在此过程中,将6G网络的超高带宽、超低时延与隐私保护联邦学习(PPFL)结合,对实现工业5.0至关重要。6G网络支持海量设备间的实时信息交互,而PPFL在保护数据隐私的同时促进数据共享与智能分析。此外,6G网络可支持自动驾驶和车联网环境中的应用,通过联邦学习(FL)高效训练模型,解决高通信成本与隐私问题,从而进一步推动工业5.0发展[39]。为增强工业5.0,[40]设计了部署在雾计算中的监控框架,优化任务分配、提升执行精度、降低时延并最大化资源利用率。然而,为避免工业5.0中单点故障(SPOF)导致的数据共享中断,PPFL需具备可验证性。鉴于工业5.0中消费电子设备(CEs)的非独立同分布(non-IID)数据特性,提升模型在non-IID数据上的收敛速度并确保全局模型的公平性,对提升生产效率和灵活性至关重要。本节重点介绍应用于工业5.0的PPFL、可验证联邦学习及non-IID联邦学习。表I通过对比现有方案,明确了TEVA的优势与现有技术的不足。
A. 隐私保护联邦学习(PPFL)
PPFL中常用差分隐私(DP)和安全多方计算(SMC)技术保护隐私。
差分隐私(DP)
He等[22]提出ACS-FL,通过自适应梯度裁剪、权重压缩和参数混洗处理物联网异构数据,缓解维度与数据量问题。
Wei等[23]开发NBAFL,提供理论收敛边界及K客户端随机调度策略,优化固定隐私预算下的收敛性能。
Lin等[10]结合本地DP与模型压缩技术提出Fed-PEMC,在保持精度的同时提升通信效率。
Wang等[11]基于高斯机制提出自适应裁剪DP框架,保护CEs数据隐私。
局限性:DP需在隐私与精度间权衡,噪声添加可能降低模型性能。
安全多方计算(SMC)
同态加密(HE):
Wang等[42]提出PPFLHE,通过HE加密本地模型并引入确认机制处理用户退出问题。
Gupta等[13]结合HE与区块链技术,确保学习过程完整性。
Zhang等[24]将HE与掩码结合保护物联网FL模型,并设计退出机制维持连续性。
秘密共享(SS):
Liu等[43]提出基于SS的雾计算聚合协议,通过“请求-广播”机制容忍用户退出。
Wang等[25]在边缘计算中结合SS、随机掩码与数字签名,保障安全性与训练效率。
Song等[26]提出EPPDA,防止逆向攻击并处理用户退出。
Chen等[44]设计工业区块链中的阈值签名方案,实现去中心化联邦学习。
局限性:现有方案未考虑中央服务器(CS)的恶意行为,且无法验证CS是否伪造全局模型。
B. 可验证联邦学习
为规避SPOF,研究者聚焦于可验证聚合:
双线性映射:VerifyNet[20]、Scheme[27]、SVeriFL[28]、VOSA[29]和Scheme[45]利用双线性映射验证全局模型完整性。
同态哈希与交互证明:VeriFL[21]使用线性同态哈希,SafetyNets[46]采用交互式证明。
其他方法:
[47]结合同态哈希与数字签名实现可追溯验证。
Xie等[30]提出FLVA,通过梯度哈希值防止恶意CS伪造模型。
Islam等[31]采用双因素认证抵御恶意攻击。
[33]构建零知识证明验证梯度,避免暴露本地模型。
[18][32]使用Hadamard积验证模型,[48]基于可信硬件实现可验证性。
局限性:多数方法依赖FedAvg,忽视non-IID数据下的收敛速度与模型精度。
C. 非独立同分布联邦学习(Non-IID FL)
针对FedAvg在non-IID数据中的缺陷,现有方法包括:
Zhu等[34]提出ISFL改进本地训练。
Yang等[49]开发CFedAvg优化通信效率。
Hu等[35]设计Fed-MGDA+,通过多目标优化减少客户端梯度冲突。
Li等[36]提出FedGini,基于基尼系数衡量公平性并添加惩罚项。
Shuai等[37]提出BalanceFL,解决全局与本地数据不平衡问题。
Jiang等[38]设计ArtFL,支持多尺度训练提升数据效用。
局限性:上述方法未考虑隐私保护与SPOF问题。
TEVA的创新
受上述工作启发,我们提出一种高效训练、隐私保护且可验证的聚合方案,有效应对工业5.0中的隐私保护、non-IID数据挑战与SPOF风险。

相关工作

odmum 非独立同分布数据


2.公平性调整:
通过负对数函数消除偏好偏差
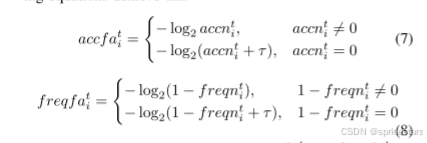
3.权重计算:
结合调整后的准确率与参与频率生成全局权重
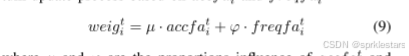
4.全局动量更新:
中央服务器计算全局伪模型并更新动量项:
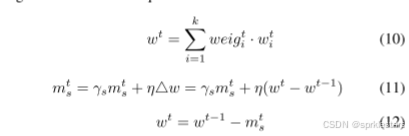
场景II:
直接平均聚合客户端模型:
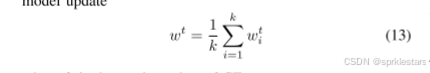
- 客户端同步
无论场景I或II,客户端均按以下操作同步本地模型:
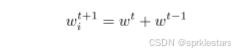
在非独立同分布训练中的函数功能


系统框架
本方案包含三个关键实体:密钥生成中心(KGC)、多个客户端设备(CE)和中央服务器(CS),各角色定义如下:
KGC(密钥生成中心):
负责系统初始化,生成必要的公共参数并安全分发给其他实体。
系统启动后,KGC立即离线,不再参与后续操作以增强安全性。
CE(客户端设备):
在每轮训练中,使用本地私有数据训练模型,并通过**优化双动量更新机制(OdMum)**更新本地模型。
对更新后的本地模型进行加密,并生成验证标签与辅助标签以确保数据完整性与安全性。
将加密模型及标签发送至CS,并负责验证全局模型的准确性。
CS(中央服务器):
应用OdMum更新全局模型,聚合来自多个CE的辅助标签与验证标签,生成全局验证标签。
将全局模型及标签分发给各CE,供其进一步验证与本地处理。
B. 威胁模型
在TEVA框架中,假设如下:
KGC:完全可信,且在发布公共参数后永久离线。
CE:诚实但好奇(Honest-but-Curious),会如实执行协议并提供正确的本地模型,但可能试图窥探其他CE或全局模型的信息。
CS:恶意(Malicious),可能被敌手控制并返回伪造的全局模型,或因计算资源有限返回低精度模型以干扰联邦学习训练。
共谋限制:
禁止KGC与其他实体共谋。
禁止CS与k或(k−1)个CE共谋(若允许,则系统隐私保护失效)。
C. 设计目标
本方案旨在设计一种高效且隐私保护的联邦学习(PPFL)框架,保护CE隐私并防止单点故障(SPOF)破坏训练流程,具体目标如下:
隐私保护:
防止外部敌手或CS从加密的本地模型中推断CE的私有数据。
抵御恶意CS与最多(k−2)个诚实但好奇的CE的共谋攻击,确保本地模型隐私。
可验证性:
当恶意CS返回伪造的全局模型时,CE可有效验证模型正确性,防止伪造模型破坏训练。
高效性:
优化CE本地模型与CS全局模型的更新机制,加速模型收敛。
减少训练轮次、总开销及交互次数,提升整体效率。
关键特性总结:
安全分层:KGC离线设计消除长期密钥暴露风险,CE与CS职责分离降低共谋可能性。
轻量验证:基于标签的验证机制在保证安全性的同时减少计算负担。
抗干扰训练:通过加密与验证标签抵御模型篡改,确保训练过程鲁棒性
系统架构
初始化

电子设备端训练·
简单来说就是初始化 ce先计算局部模型和参与度准确率(odmum模式),发送给cs,cs返回全局模型 本地更新模式2(正常模式)

加密聚合
简单来说就是验证阶段,ce计算出来验证标签和局部模型,发送给cs,cs更新出来动量(更新参与度),全局模型,然后各个ce进入模式2,ce获得全局模型

解密标签


验证
提示:这里对文章进行总结:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









