






2.2.1 find_element_by_class_name()
2.2.2 ★find_element_by_xpath()
2.2.3 find_element_by_tag_name()
1.环境配置
======
1.1安装selenium
在命令行或PyCharm terminal 输入pip install Selenium 
1.2安装EdgeDriver
我用习惯了电脑自带的edge浏览器,这里我就安装EdgeDriver。
首先点击浏览器右上角进入设置,或者直接访问 edge://settings/profiles ,点击关于,可以看到你现在的浏览器的版本,我这里是96.0.1054.29
然后进入官网Microsoft Edge Driver - Microsoft Edge Developer,因为我是最新版所以直接选择第一个,点击x86即可自动下载。下载完成后将压缩包解压到指定目录,之后就能通过确定路径进行连接了。
2.selenium的使用
=============
2.1selenium的创建
直接上代码解释。(python格式代码注释比较难看我就用普通格式的代码)
导入包
from selenium import webdriver
if name == ‘main’:
指定路径
driver_path = ‘C:\edgedriver_win64\msedgedriver.exe’
创建driver对象
driver = webdriver.Edge(driver_path)
指定访问网址,如百度
url = ‘https://www.baidu.com/’
访问网址
driver.get(url)
打印源码
print(driver.page_source)
打印当前网址
print(driver.current_url)
运行完后关闭程序
driver.quit()
运行成功后输出源码
 2.2selenium查找元素的方法
2.2selenium查找元素的方法
selenium常用元素定位方法
| 方法 | 描述 |
| — | — |
| find_element_by_id() | 通过元素id属性定位元素 |
| find_element_by_name() | 通过元素name属性定位元素 |
| find_element_by_class_name() | 通过元素class属性定位元素 |
| find_element_by_css_selector() | 通过css选择器定位元素 |
| find_element_by_link_text() | 通过超链接定位元素 |
| find_element_by_xpath() | 通过xpath定位元素 |
| find_element_by_tag_name() | 通过标签名定位元素 |
| find_elements(By.Type,value) | 通用方法 |
| is_display() | 判断某个元素是否存在 |
重点
**selenium定位元素的格式为:find_element_by_xx(), find_elements_by_xx(),**element返回符合条件的单个元素,当出现多个符合条件的元素时,返回的是第一个元素。elements返回的是列表,里面包含所有符合条件的元素;当使用find_element没有查找到元素时,程序将会报错,find_elements没查找到元素会返回空列表,不确定有没有元素时可以使用try-except方法,在之后的例子中我会讲解;如果直接打印element的话会返回这个
<selenium.webdriver.remote.webelement.WebElement (session=“7c081bdc33be8d6a34de5f2ec3a91173”, element=“dede5231-6016-4a4a-ae7c-261c2bac0422”)>
这肯定不是我们想要的结果,一般来说我们要的是文本,此时**要输出文本的话在元素后面加.text即可打印文本,而文本是该节点的所有文本,包括子节点的文本,我在xpath会讲。**下面我以百度为例,讲解如果使用selenium语句获取网页信息。
进入百度,假如我们要爬取热搜词句该怎么做呢?

选择第一个文本,右击检查可以马上确定该文本在源码中的位置

接下来就使用几种常见的方法对文本进行获取。
2.2.1 find_element_by_class_name()
我们看到文本前面有个class属性标签,所以我们可以直接通过find_element_by_class_name()的方法对其获取。
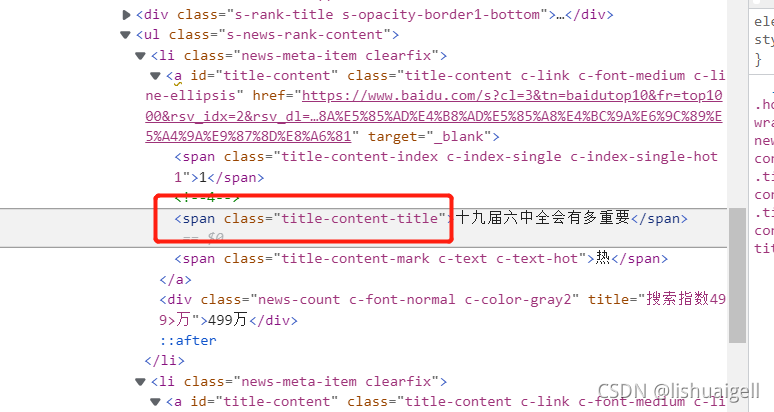
问题来了,我们怎么知道看到的这个class名是不是只有一个,或者说是第一个呢?(因为只有在一个元素,或者是第一个元素的情况时使用find_element查找才能找到刚看到的那个)有两个办法,1.在源码一个一个找。2.在源码中使用xpath确定。我说第二种,回到刚才源码,使用ctrl+F,输入: //span[@class=‘title-content-title’]
 发现他们是有规律的,点击回车可以确定是下一条热搜语句。
发现他们是有规律的,点击回车可以确定是下一条热搜语句。

因此我们可以使用find_elements的方法获取所有热搜语句再进行输出。代码如下。
element如果没有找到元素时,selenium会报错,所以使用try可以避免因未找到元素而终止程序的情况
try:
找第一个符合条件的元素
a = driver.find_element_by_class_name(‘title-content-title’)
print(a.text)
except:
print(‘没有找到该元素!’)
查找所有符合条件的元素
a = driver.find_elements_by_class_name(‘title-content-title’)
如果用elements没找到元素会返回空列表不会报错。
if(len(a) != 0):
for i in a:
print(a.index(i)+1)
print(i.text)
else:
print(‘没有找到该元素!’)
输出如下

2.2.2 ★find_element_by_xpath()
同理,如果您已经学会了第一种方式查找的话,那么这种方法肯定难不倒你。
代码如下:
element如果没有找到元素时,selenium会报错,所以使用try可以避免因未找到元素而终止程序的情况
try:
找第一个符合条件的元素
a = driver.find_element_by_class_name(‘title-content-title’)
a = driver.find_elements_by_xpath(‘//span[@class=“title-content-title”]’)
print(a.text)
except:
print(‘没有找到该元素!’)
查找所有符合条件的元素
a = driver.find_elements_by_class_name(‘title-content-title’)
a = driver.find_elements_by_xpath(‘//span[@class=“title-content-title”]’)
如果用elements没找到元素会返回空列表不会报错。
if len(a):
for i in a:
print(a.index(i) + 1)
print(i.text)
else:
print(‘没有找到该元素!’)
输出结果跟上面一样
**值得一提的是,selenium跟以往的xpath有所区别。**比如他无法直接获取元素的属性值,以上面的代码为例,如果你想获取class的值‘title-content-title’的话正常情况直接在xpath路径后面加个/@class即’//span[@class=“title-content-title”]/@class’就可以了,但在selenium里必须先获取span的xpath的路径,在通过.get_attribute(‘class’)进行获取。注意加载百度热搜会有两种版本,一种横版,一种竖版,横版竖版的代码会不一样。
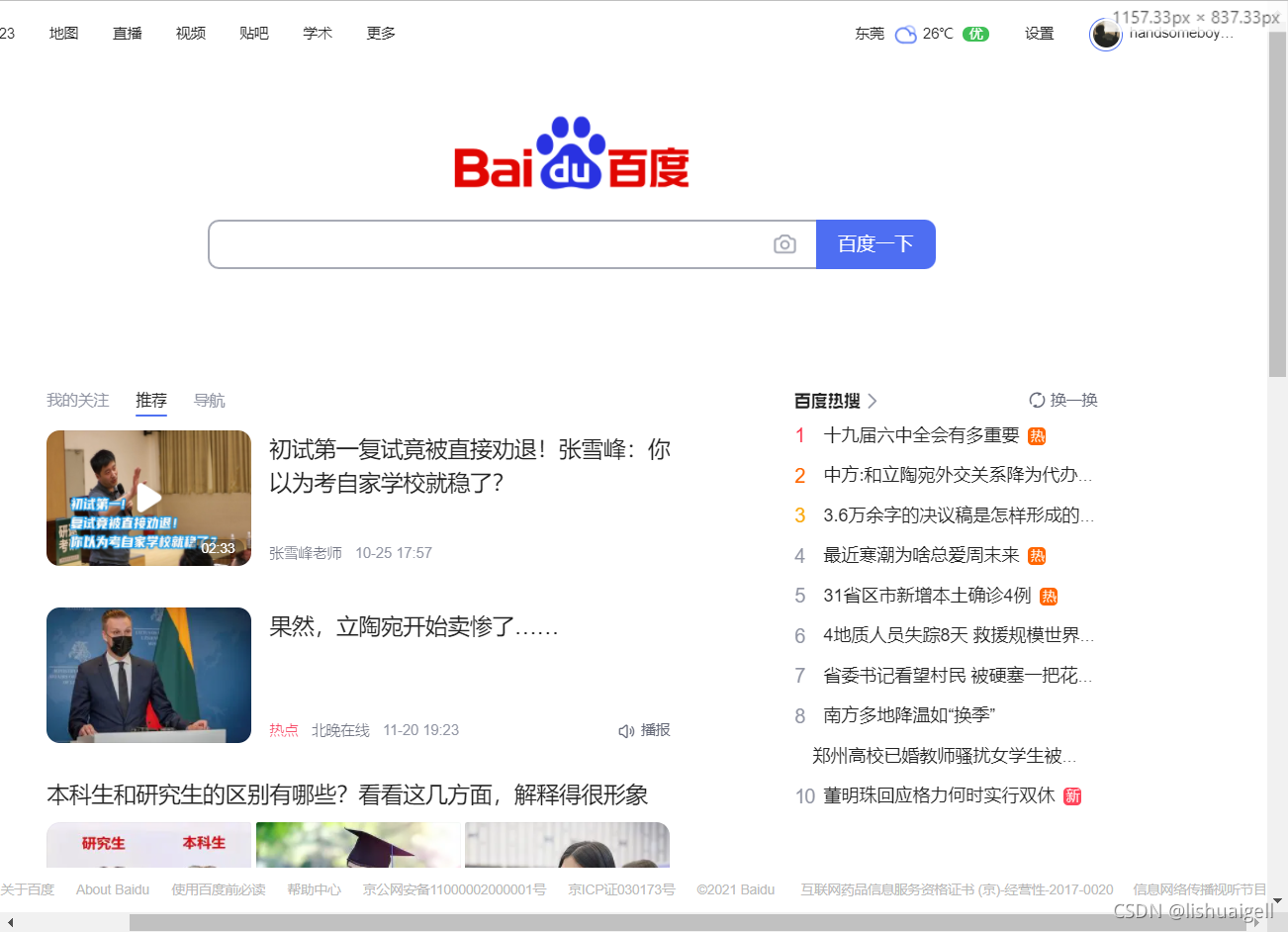
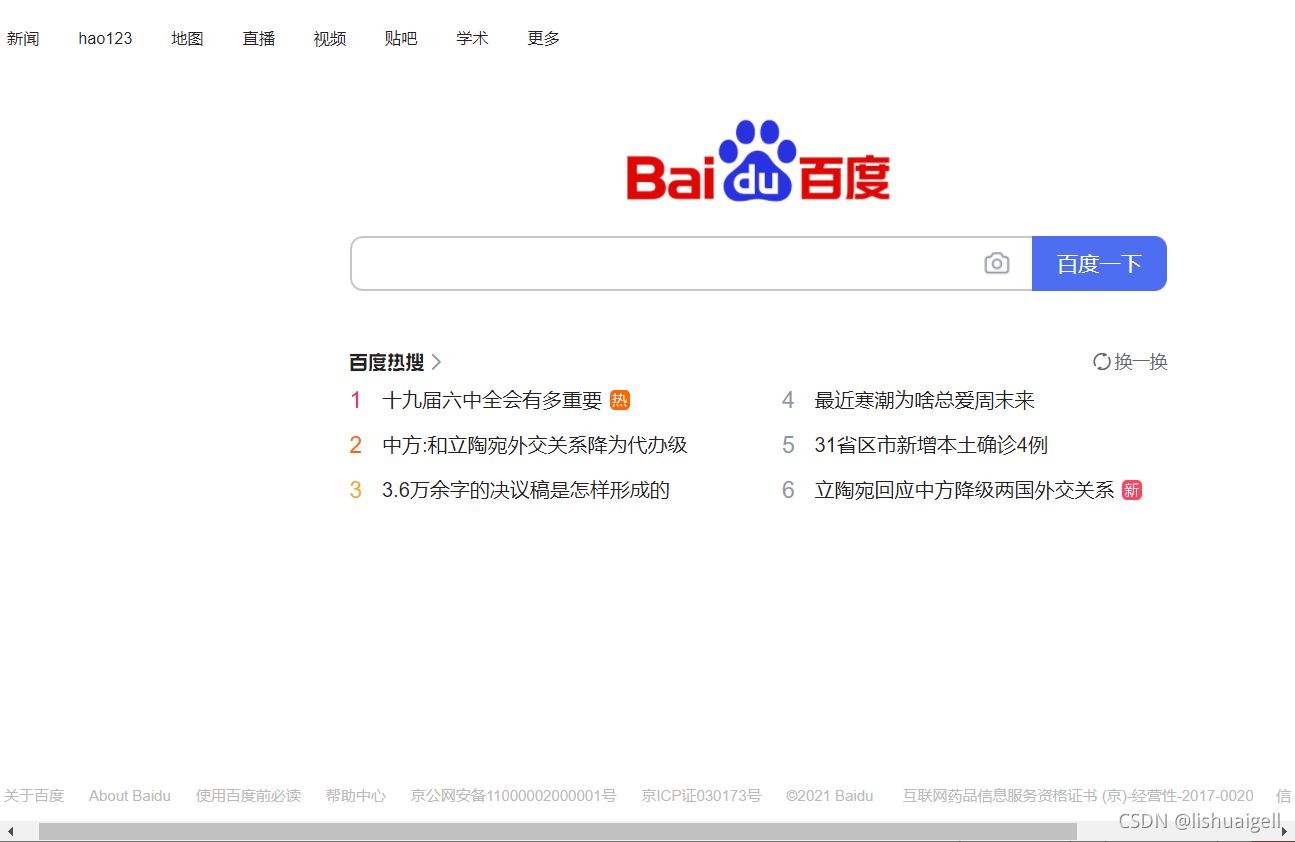
查找的代码如下:
try:
a = driver.find_element_by_xpath(‘//*[@id=“hotsearch-content-wrapper”]/li[1]/a/span[2]’)
print(a.get_attribute(‘class’))
except:
print(‘没有找到该元素!’)
还有一点的不同就是如果想获取一个节点下的文本时一般的xpath是在路径下加个’/text()',而selenium他是在找出元素之后加.text。**而且,他获取的是这个节点下的所有文本,包括子节点的文本。**有什么区别呢?我举个例子:

用常规xpath的话要这样’//div[@class=“job-detail”]/a/text()‘获取完进行拼接后去除‘查看地图’,之后再获取’//div[@class=“job-detail”]/text()'再拼接,如果地址再详细一点的话这样处理起来比较麻烦,但是selenium一步搞定,最后再用字符串分割去掉后面的‘查看地图’即可。这种方法在之后的爬取拉勾网信息中显得比较方便了。
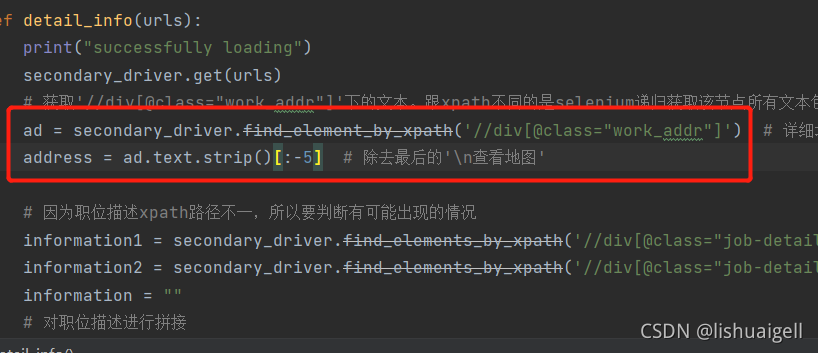

2.2.3 find_element_by_tag_name()
没遇到合适的例子,没办法举例,本质上还是跟前面的查找方法一样的,有不懂的地方可以问我。
2.2.4 find_element_by_id()
这个我可以跟下面一起讲吗?见2.4.1
2.3selenium的常用动作
| 方法名 | 描述 |
| — | — |
| move_to_element() | 鼠标悬浮在某元素上 |
| click() | 左键单击元素 |
| double_click() | 左键双击元素 |
| context_click() | 右键单击元素 |
| click_and_hold() | 长按元素 |
send_keys(str)
|
传入元素
|
以及执行js脚本 driver.execute_script(),设置窗体起始位置driver.set_window_position();
设置窗体大小driver.set_window_size(),driver.maximize_window(),使用句柄等。
2.4selenium实践
2.4.1通过搜索框查找信息
同样以百度为例,我们在搜索框右击检查,发现这里有个‘input’,说明我们是可以向里面传递字符串的

假设id为’kw’的元素不止一个,那么我们就使用find_elements_id()进行查找,将返回的元素列表进行输出,如果输出的元素不止一个,那么我们需提升过滤条件,或者使用xpath路径查找。而这里返回的元素是唯一的,因此我们可以直接使用find_element_id(),确定元素后使用send_keys()传递字符串。一般的,‘kw’其实就是’keywords’,作为一名合格的程序员,良好的编程习惯不能少,每个变量都应该以其作用来命名。话说回来。传递完参数后我们就点击搜索按钮即可搜索。至于搜索按钮…选中按钮右击检查可看到class名称有个‘btn’,因此可以大概知道这是一个按钮,实际上就是,因为我们通过检查来确定源码位置的,所以他标出来的位置就是目的位置。
我们找到这个元素的位置后使用click()就可以完成点击搜索了。下面看一下代码如何实现:
导入包
from selenium import webdriver
if name == ‘main’:
指定路径
driver_path = ‘C:\edgedriver_win64\msedgedriver.exe’
创建driver对象
driver = webdriver.Edge(driver_path)
指定访问网址,如百度
url = ‘https://www.baidu.com/’
访问网址
driver.get(url)
str = input(“请输入您想要查找的关键词:”)
try:
kw = driver.find_element_by_id(‘kw’)
kw.send_keys(str)
btn = driver.find_element_by_id(‘su’)
btn.click()
except:
print(‘没有找到该元素!’)
driver.quit()
2.4.2获取浮窗数据
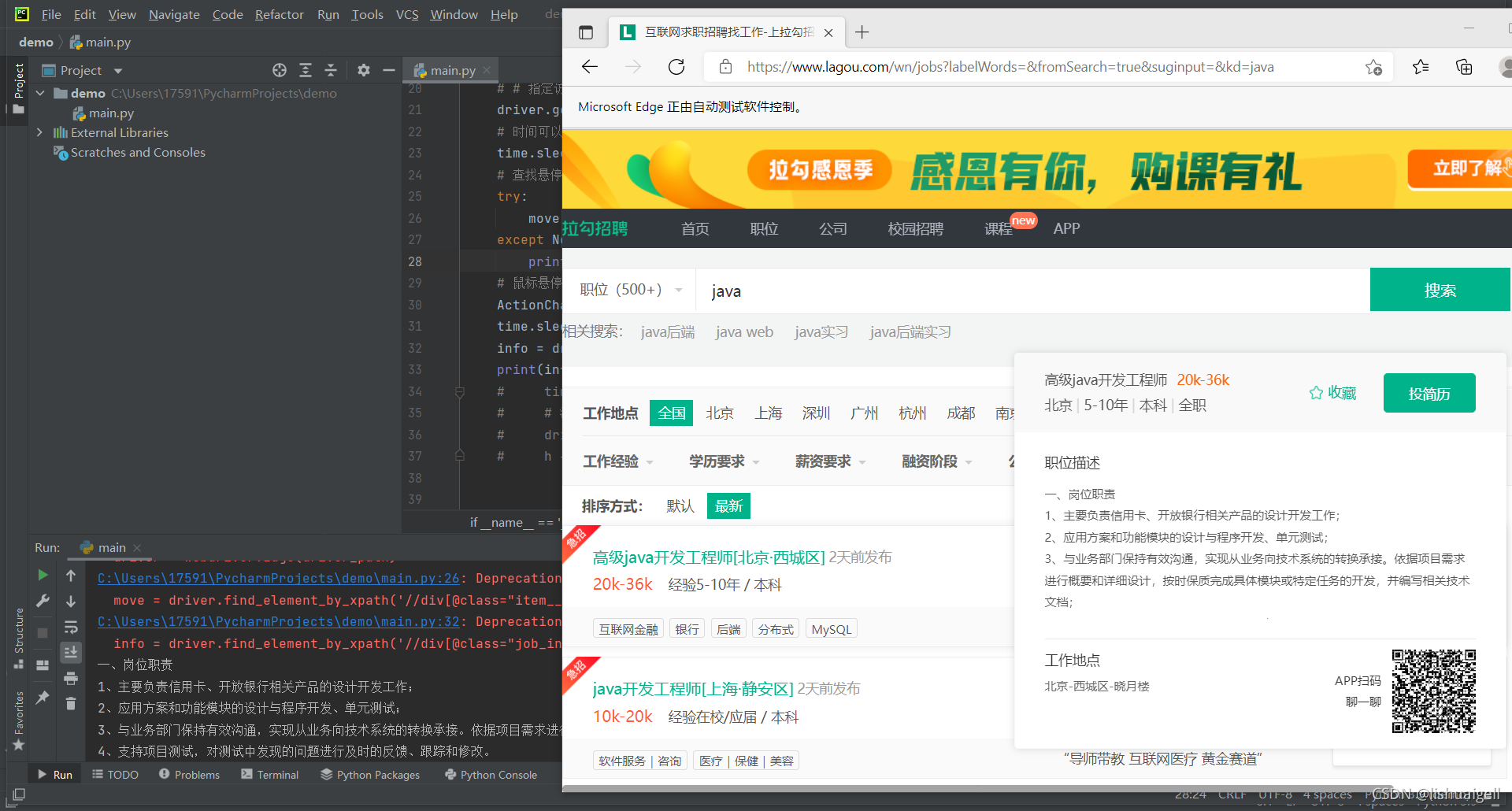
我们以拉勾网为例,进入到招聘信息界面

当我们将鼠标停留在职位名称上面时会弹出这个简略信息的浮窗

而当鼠标移开时浮窗信息也随之消失。右击检查源码,发现他是动态的

为了能够获取浮窗信息我们必须要将鼠标停留在上面才能获取信息,右击检查

发现文本信息在类名为这串代码的节点下

接下来用driver的类名查找元素的办法就能爬取浮窗信息了。我们结合代码分析一下
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver import ActionChains
if name == ‘main’:
指定路径
driver_path = ‘C:\edgedriver_win64\msedgedriver.exe’
创建driver对象
driver = webdriver.Edge(driver_path)
# 指定访问网址
driver.get(‘https://www.lagou.com/wn/jobs?labelWords=&fromSearch=true&suginput=&kd=java’)
时间可以适当修改
time.sleep(2)
查找悬停目标元素,如果没找到会抛出异常,所以要用try捕获
try:
move = driver.find_element_by_xpath(‘//div[@class=“item__10RTO”]’) # 查找符合条件的第一个元素
except NoSuchElementException as e:
print(“没有该元素!”)
鼠标悬停至招聘信息中,获取二级页面简略信息
ActionChains(driver).move_to_element(move).perform()
等待两秒再获取浮窗信息,不然可能数据没更新
time.sleep(2)
获取浮窗信息
try:
info = driver.find_element_by_class_name(“job_discription__1qxwN”)
打印浮窗信息
print(info.text)
except NoSuchElementException as e:
print(“没有该元素!”)
成功结果如图:
2.4.3实现翻页功能
我们仍以刚才的界面为例,将滑动条滑到底部找到翻页按钮右击检查寻找其特征发现其在class名为‘lg-pagination-next’的节点下。
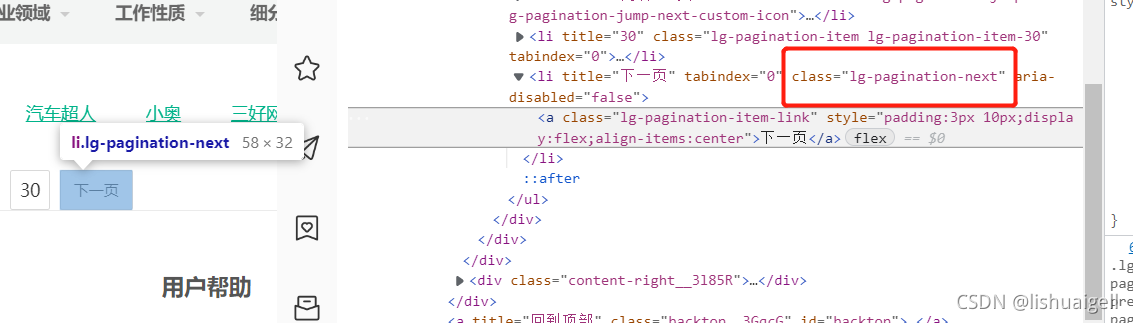
复制类名并查找发现就一个,说明我们可以通过它来确定下一页按钮的位置。当没有这个按钮说明是最后一页了我们用try语句捕获异常即可。注意,在翻页的过程中最好先将滚动条滑动至底部再进行翻页操作,因为可能会有广告浮窗影响点击。翻页代码如下:
导入包
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver import ActionChains
if name == ‘main’:
指定路径
driver_path = ‘C:\edgedriver_win64\msedgedriver.exe’
创建driver对象
driver = webdriver.Edge(driver_path)
# 指定访问网址
driver.get(‘https://www.lagou.com/wn/jobs?labelWords=&fromSearch=true&suginput=&kd=java’)
定义起始页码
page = 1
定义翻页次数
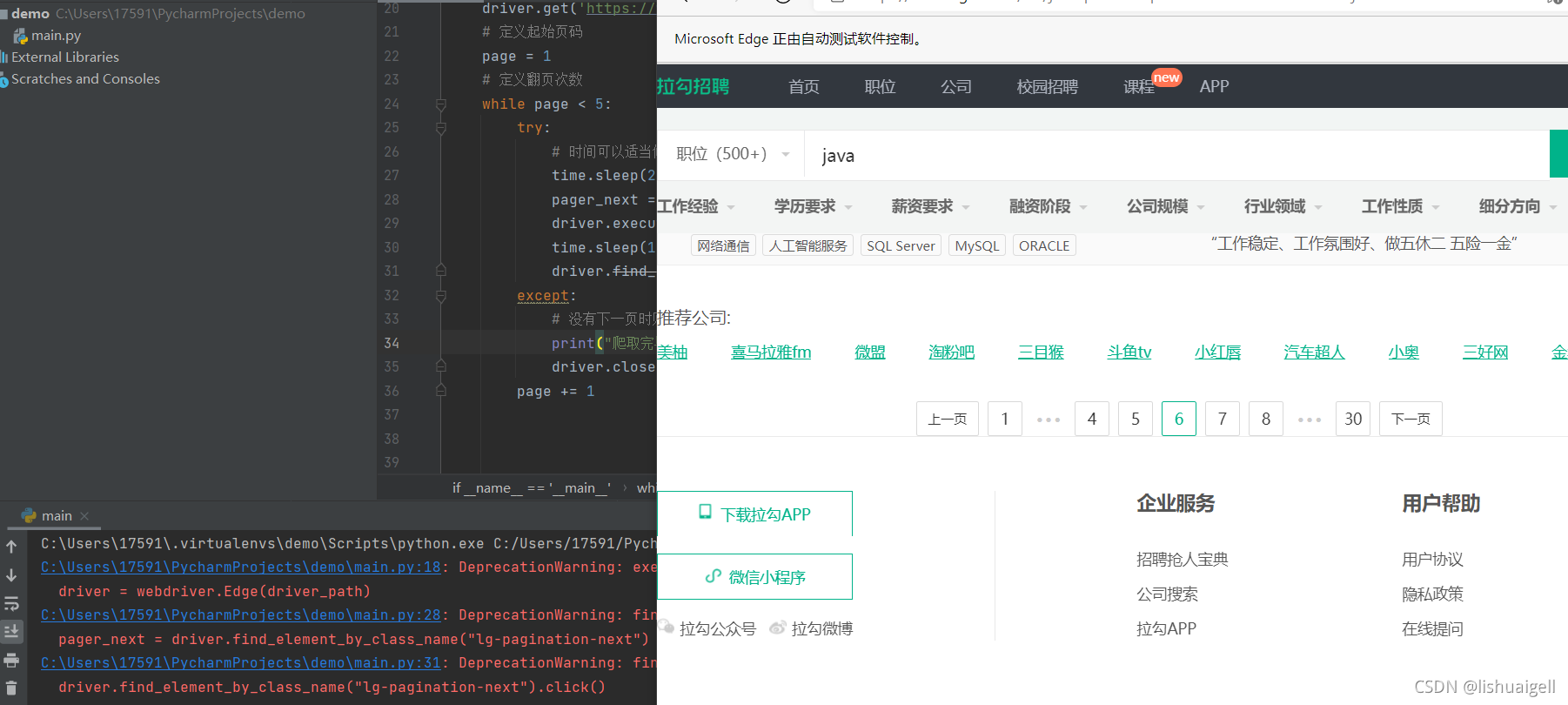
while page < 6:
try:
时间可以适当修改
time.sleep(2)
pager_next = driver.find_element_by_class_name(“lg-pagination-next”)
driver.execute_script(“scroll(0,2500)”) # 下拉滚动条,拉到底,不然会有弹窗影响点击
time.sleep(1)
driver.find_element_by_class_name(“lg-pagination-next”).click()
except:
没有下一页时则直接关闭
print(“爬取完毕!”)
driver.close()
page += 1
翻页成功如图
2.4.4使用句柄实现多窗口爬取数据
假如我们原本在一级界面窗口,为了得到招聘的详情信息,我们就要点击名称进入二级界面

点击后进入了一个新的窗口
 如果我们要获取详情界面的数据,直接使用find_element的方法查找的话是行不通的,因为此时的driver还在一级界面,直接使用那个方法的话只能查找一级界面的元素。所以要切换句柄,将driver切换至详情界面的窗口,然后就可以信息进行获取了,获取完窗口的信息然后关闭这里的窗口,然后在切换至一级页面的句柄即可。
如果我们要获取详情界面的数据,直接使用find_element的方法查找的话是行不通的,因为此时的driver还在一级界面,直接使用那个方法的话只能查找一级界面的元素。所以要切换句柄,将driver切换至详情界面的窗口,然后就可以信息进行获取了,获取完窗口的信息然后关闭这里的窗口,然后在切换至一级页面的句柄即可。
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver import ActionChains
if name == ‘main’:
指定路径
driver_path = ‘C:\edgedriver_win64\msedgedriver.exe’
创建driver对象
driver = webdriver.Edge(driver_path)
如果你觉得每次都要拖走浏览器来看控制台信息可以试试这个
设置浏览器初始位置,(x偏移量,y偏移量)
driver.set_window_position(500, 0)

















 1686
1686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









