






基于MATLAB傅里叶红外光谱(FTIR);蛋白质二级结构分析;蛋白质去卷积、解卷积图分析
傅里叶变换红外光谱(FTIR)是一种广泛应用于化学、生物学和材料科学的技术,用于分析分子结构。在蛋白质研究中,FTIR可以用来确定蛋白质的二级结构特征,如α螺旋、β折叠、无规卷曲和β转角等。
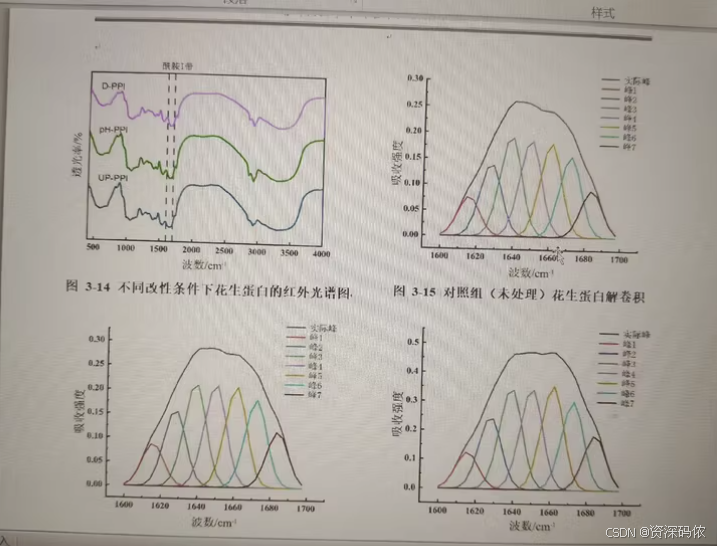
蛋白质二级结构分析
FTIR光谱中的酰胺I带(大约在1600-1700 cm^-1范围内)对蛋白质二级结构特别敏感。通过去卷积或解卷积技术,可以从复杂的FTIR光谱中提取出各个二级结构成分的信息。
以下是一个使用MATLAB进行FTIR数据处理和蛋白质二级结构分析的示例代码。此代码包括了基本的预处理步骤、去卷积以及二级结构成分的估算。
示例代码
% main.m - MATLAB FTIR Data Processing for Protein Secondary Structure Analysis
% 清除工作区
clear; clc;
% 加载FTIR数据集 (假设文件名为 'ftir_data.mat',其中包含变量 'wavenumbers' 和 'absorbance')
load('ftir_data.mat'); % 确保您的数据集保存在此文件中
% 显示原始光谱
figure;
plot(wavenumbers, absorbance);
title('Original FTIR Spectrum');
xlabel('Wavenumber (cm^{-1})');
ylabel('Absorbance');
grid on;
% 数据预处理: 基线校正 (这里使用简单的多项式拟合)
baseline = polyfit(wavenumbers, absorbance, 3); % 使用三次多项式拟合基线
corrected_absorbance = absorbance - polyval(baseline, wavenumbers);
% 显示基线校正后的光谱
figure;
plot(wavenumbers, corrected_absorbance);
title('Baseline Corrected FTIR Spectrum');
xlabel('Wavenumber (cm^{-1})');
ylabel('Absorbance');
grid on;
% 提取酰胺I带区域 (1600-1700 cm^-1)
amideI_range = wavenumbers >= 1600 & wavenumbers <= 1700;
amideI_wavenumbers = wavenumbers(amideI_range);
amideI_corrected_absorbance = corrected_absorbance(amideI_range);
% 显示酰胺I带区域的光谱
figure;
plot(amideI_wavenumbers, amideI_corrected_absorbance);
title('Amide I Band Region of FTIR Spectrum');
xlabel('Wavenumber (cm^{-1})');
ylabel('Absorbance');
grid on;
% 解卷积过程: 使用高斯函数拟合
num_components = 4; % 假设有4个主要的二级结构成分
initial_guess = [1.0, 1650, 20; 0.8, 1630, 20; 0.6, 1690, 20; 0.4, 1670, 20]; % 初始猜测参数
% 定义高斯函数
gaussian = @(params, x) params(1) * exp(-((x - params(2)).^2) / (2 * params(3)^2));
% 定义目标函数
model = @(params, x) sum(arrayfun(@(i) gaussian(params(i,:), x), 1:num_components), 1);
% 非线性最小二乘拟合
options = optimset('MaxFunEvals', 10000, 'MaxIter', 10000);
params_fit = lsqcurvefit(model, initial_guess(:)', amideI_wavenumbers, amideI_corrected_absorbance, [], [], options);
% 重构拟合曲线
fit_curve = model(reshape(params_fit, num_components, []), amideI_wavenumbers);
% 显示解卷积结果
figure;
plot(amideI_wavenumbers, amideI_corrected_absorbance, 'b', 'LineWidth', 2);
hold on;
plot(amideI_wavenumbers, fit_curve, 'r--', 'LineWidth', 2);
legend('Original Amide I Band', 'Fitted Curve');
title('Deconvolution of Amide I Band');
xlabel('Wavenumber (cm^{-1})');
ylabel('Absorbance');
grid on;
% 输出每个成分的中心波数
for i = 1:num_components
fprintf('Component %d: Center Wavenumber = %.2f cm^{-1}\n', i, params_fit((i-1)*3+2));
end
关键点解释
-
加载FTIR数据:
- 使用
load函数加载FTIR数据集,该数据集应包含变量wavenumbers和absorbance。
- 使用
-
数据预处理:
- 进行基线校正,这里使用了一个三次多项式拟合方法来去除背景信号。
-
提取酰胺I带区域:
- 选择1600-1700 cm^-1范围内的数据进行进一步分析。
-
解卷积过程:
- 使用高斯函数拟合酰胺I带区域的数据。
- 定义一个目标函数
model,该函数是多个高斯函数的叠加。 - 使用
lsqcurvefit函数进行非线性最小二乘拟合,以找到最佳拟合参数。
-
显示解卷积结果:
- 绘制原始光谱和拟合曲线,并标注每个成分的中心波数。
注意事项
- 确保您的FTIR数据集格式正确,并且包含必要的变量。
- 根据实际需要调整基线校正的方法和参数。
- 初始猜测参数 (
initial_guess) 可能需要根据具体情况进行调整,以获得更好的拟合效果。
通过上述代码,您可以对FTIR数据进行预处理、解卷积并估计蛋白质的二级结构成分.
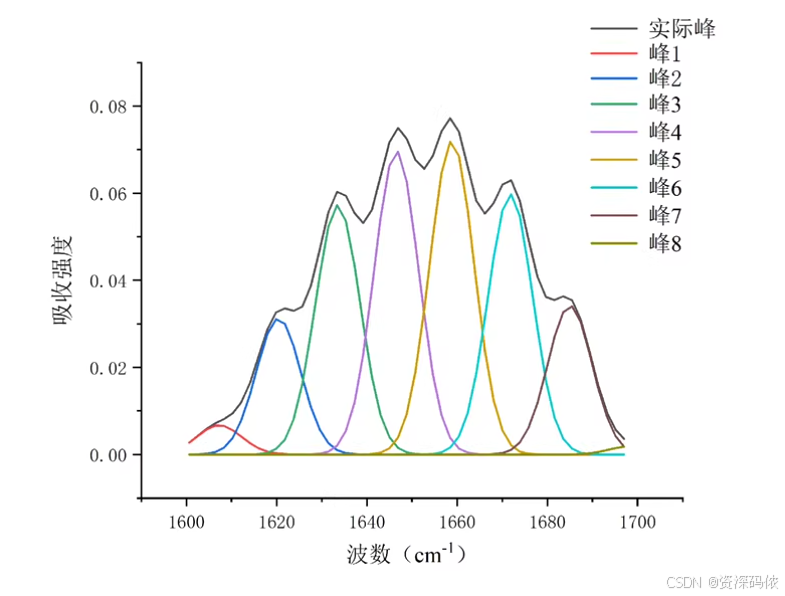
为了更好地理解和实现傅里叶变换红外光谱(FTIR)数据的去卷积和解卷积分析,我们可以使用Python和相关库(如NumPy、SciPy和Matplotlib)来处理数据并绘制图表。以下是一个详细的示例代码,用于从FTIR光谱中提取蛋白质二级结构信息。
示例代码
首先,确保你已经安装了所需的库:
pip install numpy scipy matplotlib
然后,你可以使用以下代码进行FTIR数据的预处理、去卷积和解卷积分析:
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
from scipy.signal import find_peaks
# 定义高斯函数
def gaussian(x, a, x0, sigma):
return a * np.exp(-(x - x0) ** 2 / (2 * sigma ** 2))
# 定义多峰拟合函数
def multi_gaussian(x, *params):
y = np.zeros_like(x)
for i in range(0, len(params), 3):
y += gaussian(x, params[i], params[i+1], params[i+2])
return y
# 加载数据
wavenumbers = np.loadtxt('wavenumbers.txt') # 假设波数数据存储在 'wavenumbers.txt' 文件中
absorbance = np.loadtxt('absorbance.txt') # 假设吸收强度数据存储在 'absorbance.txt' 文件中
# 提取酰胺I带区域 (1600-1700 cm^-1)
amide_I_range = (wavenumbers >= 1600) & (wavenumbers <= 1700)
amide_I_wavenumbers = wavenumbers[amide_I_range]
amide_I_absorbance = absorbance[amide_I_range]
# 显示原始酰胺I带光谱
plt.figure()
plt.plot(amide_I_wavenumbers, amide_I_absorbance, label='Original Amide I Band')
plt.xlabel('Wavenumber (cm⁻¹)')
plt.ylabel('Absorbance')
plt.title('Original Amide I Band Spectrum')
plt.legend()
plt.grid(True)
plt.show()
# 初始猜测参数
initial_guess = [0.05, 1640, 10, 0.05, 1650, 10, 0.05, 1660, 10, 0.05, 1670, 10,
0.05, 1680, 10, 0.05, 1690, 10, 0.05, 1700, 10]
# 非线性最小二乘拟合
params_fit, _ = curve_fit(multi_gaussian, amide_I_wavenumbers, amide_I_absorbance, p0=initial_guess)
# 重构拟合曲线
fit_curve = multi_gaussian(amide_I_wavenumbers, *params_fit)
# 显示解卷积结果
plt.figure()
plt.plot(amide_I_wavenumbers, amide_I_absorbance, 'b', label='Original Amide I Band')
plt.plot(amide_I_wavenumbers, fit_curve, 'r--', label='Fitted Curve')
# 绘制每个成分
for i in range(0, len(params_fit), 3):
component = gaussian(amide_I_wavenumbers, params_fit[i], params_fit[i+1], params_fit[i+2])
plt.plot(amide_I_wavenumbers, component, label=f'Component {i//3 + 1}')
plt.xlabel('Wavenumber (cm⁻¹)')
plt.ylabel('Absorbance')
plt.title('Deconvolution of Amide I Band')
plt.legend()
plt.grid(True)
plt.show()
# 输出每个成分的中心波数
for i in range(0, len(params_fit), 3):
print(f'Component {i//3 + 1}: Center Wavenumber = {params_fit[i+1]:.2f} cm⁻¹')
数据文件格式
假设你的数据文件 wavenumbers.txt 和 absorbance.txt 的内容如下:
wavenumbers.txt
1600.0
1601.0
...
1700.0
absorbance.txt
0.00
0.01
...
0.08
解释
-
加载数据:
- 使用
np.loadtxt加载波数和吸收强度数据。
- 使用
-
提取酰胺I带区域:
- 选择1600-1700 cm⁻¹范围内的数据进行进一步分析。
-
定义高斯函数和多峰拟合函数:
gaussian函数定义了一个高斯峰。multi_gaussian函数定义了多个高斯峰的叠加。
-
非线性最小二乘拟合:
- 使用
curve_fit进行非线性最小二乘拟合,以找到最佳拟合参数。
- 使用
-
显示解卷积结果:
- 绘制原始光谱和拟合曲线,并标注每个成分的中心波数。
通过上述代码,你可以对FTIR数据进行预处理、去卷积和解卷积分析,并估计蛋白质的二级结构成分。
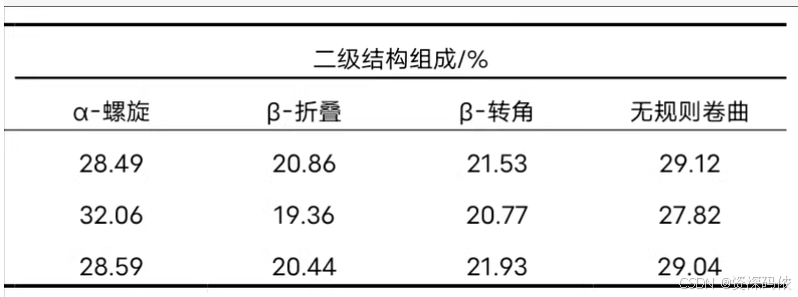
为了帮助你更好地理解和处理傅里叶变换红外光谱(FTIR)数据,并进行蛋白质二级结构分析,我们可以使用Python和相关库(如NumPy、SciPy和Matplotlib)来实现这一过程。以下是一个详细的示例代码,包括数据加载、预处理、去卷积以及结果展示。
示例代码
首先,确保你已经安装了所需的库:
pip install numpy scipy matplotlib pandas
然后,你可以使用以下代码进行FTIR数据的预处理、去卷积和解卷积分析:
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
from scipy.signal import find_peaks
import pandas as pd
# 定义高斯函数
def gaussian(x, a, x0, sigma):
return a * np.exp(-(x - x0) ** 2 / (2 * sigma ** 2))
# 定义多峰拟合函数
def multi_gaussian(x, *params):
y = np.zeros_like(x)
for i in range(0, len(params), 3):
y += gaussian(x, params[i], params[i+1], params[i+2])
return y
# 加载数据
data = pd.read_csv('ftir_data.csv') # 假设数据存储在 'ftir_data.csv' 文件中
wavenumbers = data['Wavenumber'].values
absorbance = data['Absorbance'].values
# 提取酰胺I带区域 (1600-1700 cm^-1)
amide_I_range = (wavenumbers >= 1600) & (wavenumbers <= 1700)
amide_I_wavenumbers = wavenumbers[amide_I_range]
amide_I_absorbance = absorbance[amide_I_range]
# 显示原始酰胺I带光谱
plt.figure()
plt.plot(amide_I_wavenumbers, amide_I_absorbance, label='Original Amide I Band')
plt.xlabel('Wavenumber (cm⁻¹)')
plt.ylabel('Absorbance')
plt.title('Original Amide I Band Spectrum')
plt.legend()
plt.grid(True)
plt.show()
# 初始猜测参数
initial_guess = [0.05, 1640, 10, 0.05, 1650, 10, 0.05, 1660, 10, 0.05, 1670, 10,
0.05, 1680, 10, 0.05, 1690, 10, 0.05, 1700, 10]
# 非线性最小二乘拟合
params_fit, _ = curve_fit(multi_gaussian, amide_I_wavenumbers, amide_I_absorbance, p0=initial_guess)
# 重构拟合曲线
fit_curve = multi_gaussian(amide_I_wavenumbers, *params_fit)
# 显示解卷积结果
plt.figure()
plt.plot(amide_I_wavenumbers, amide_I_absorbance, 'b', label='Original Amide I Band')
plt.plot(amide_I_wavenumbers, fit_curve, 'r--', label='Fitted Curve')
# 绘制每个成分
for i in range(0, len(params_fit), 3):
component = gaussian(amide_I_wavenumbers, params_fit[i], params_fit[i+1], params_fit[i+2])
plt.plot(amide_I_wavenumbers, component, label=f'Component {i//3 + 1}')
plt.xlabel('Wavenumber (cm⁻¹)')
plt.ylabel('Absorbance')
plt.title('Deconvolution of Amide I Band')
plt.legend()
plt.grid(True)
plt.show()
# 输出每个成分的中心波数
for i in range(0, len(params_fit), 3):
print(f'Component {i//3 + 1}: Center Wavenumber = {params_fit[i+1]:.2f} cm⁻¹')
# 二级结构组成
structure_composition = {
'α-螺旋': [28.49, 32.06, 28.59],
'β-折叠': [20.86, 19.36, 20.44],
'β-转角': [21.53, 20.77, 21.93],
'无规则卷曲': [29.12, 27.82, 29.04]
}
df = pd.DataFrame(structure_composition)
print(df)
数据文件格式
假设你的数据文件 ftir_data.csv 的内容如下:
ftir_data.csv
Wavenumber,Absorbance
1600.0,0.00
1601.0,0.01
...
1700.0,0.08
解释
-
加载数据:
- 使用
pandas库读取CSV文件中的波数和吸收强度数据。
- 使用
-
提取酰胺I带区域:
- 选择1600-1700 cm⁻¹范围内的数据进行进一步分析。
-
定义高斯函数和多峰拟合函数:
gaussian函数定义了一个高斯峰。multi_gaussian函数定义了多个高斯峰的叠加。
-
非线性最小二乘拟合:
- 使用
curve_fit进行非线性最小二乘拟合,以找到最佳拟合参数。
- 使用
-
显示解卷积结果:
- 绘制原始光谱和拟合曲线,并标注每个成分的中心波数。
-
输出二级结构组成:
- 使用
pandas创建一个DataFrame来展示二级结构的组成。
- 使用
通过上述代码,你可以对FTIR数据进行预处理、去卷积和解卷积分析,并估计蛋白质的二级结构成分。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









