






Rapid and nondestructive identification of rice storage year using
hyperspectral technology
利用高光谱技术快速无损地识别大米储藏年份
预处理:
1. 多元散点校正法(MSC, Multiplicative Scatter Correction)
作用:减少由于散射(如样本表面粗糙度、颗粒大小)造成的光谱漂移。
原理:将每条光谱校正为与平均光谱相一致的斜率和截距。
2. 标准正态变换(Standard Normal Variate, SNV)
作用:类似MSC,但更侧重于每条光谱自身的均值和标准差归一化处理,去除散射干扰。
原理:每条光谱做中心化(减去均值)和缩放(除以标准差)。
3. 一阶导数法(1st Derivative)
作用:强调光谱曲线的“斜率”,增强特征变化,去除背景干扰。
降维:
1. 主成分分析(PCA)
原理:通过线性组合最大化数据方差,降维为少数几个“主成分”。
作用:降维(减少冗余特征);可视化高维数据结构
在本研究中的应用:可视化不同储藏年份样本的分布趋势。
2. t-分布随机邻域嵌入(t-SNE)
原理:一种非线性降维方法,适合展示高维数据的簇结构。
特点:比PCA更适合展示数据的聚类结构,但不适合做建模。
在本文中:辅助验证不同年份大米在特征空间中的可分性。
特征选择:
1. 竞争性自适应重加权算法(CARS)
原理:基于偏最小二乘回归(PLS)反复迭代,选出对分类最有用的特征波长,提高模型性能。
2. Lasso回归(最小绝对收缩和选择算子)
原理:加入L1正则项,通过压缩部分系数为0来选择特征。
在本文中:从高维光谱特征中筛选出重要波长位置。
水稻的纹理特征分析:
1. 局部二值模式(LBP, Local Binary Pattern) 18个纹理特征
原理:用邻近像素值与中心像素的比较构造二值码,提取局部纹理。
在本文中:捕捉大米表面纹理随老化变化的模式。
2. 灰度共生矩阵(GLCM, Gray Level Co-occurrence Matrix) 24个纹理特征
原理:统计图像中灰度级之间的空间关系(如对比度、熵、能量等)。
作用:量化纹理粗糙度、方向性等宏观特征。
常用指标:对比度、熵、同质性、相关性。
3. Tamura特征 3个纹理特征
原理:模拟人类视觉系统对纹理的感知,如粗糙度、对比度、方向性。
在图像处理中的作用:描述纹理感知的主观因素。
与GLCM互补,提供更加“感官”层面的纹理指标。
特征融合、建模:
1. 鲸鱼优化算法(WOA, Whale Optimization Algorithm)
原理:模拟座头鲸捕食行为的群体智能优化算法。
作用:搜索模型的最优超参数(如SVM的C和gamma)。
2. 支持向量机(SVM)
原理:寻找能最大化类间间隔的超平面,用于分类。
特点:适合小样本、高维特征;可以通过核函数处理非线性问题。
在本研究中:作为融合模型的一部分基础分类器。
3. 极值梯度提升(XGBoost)
原理:改进的梯度提升树(GBDT)算法
具有更强的正则化和处理能力,能处理缺失值;支持并行计算。
在本文中:集成光谱与纹理特征后的主分类模型。
评价指标:准确率、查准率、查全率和F1值
基于提取的纹理特征,建立WOA-SVM和XGBoost模型,结果如表1所示
结果表明,基于纹理数据的XGBoost模型比WOA-SVM模型提取效果更好,LBP算法在图像纹理特征提取算法中准确率最高
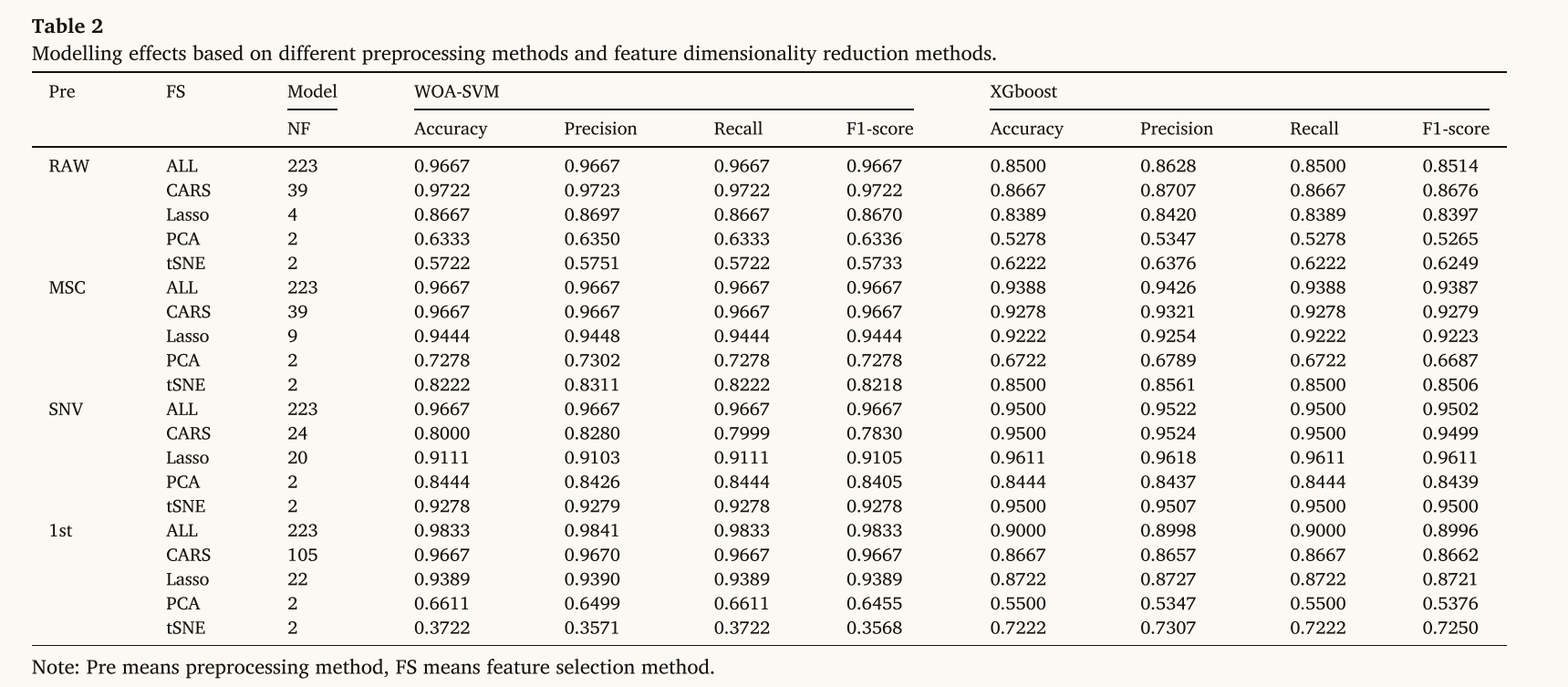
预处理+机器学习,对光谱数据进行学习,建立识别模型,如表2所示
目的:探讨传统机器学习和深度学习在水稻储藏年份识别中的优缺点
采用WOASVM和XGBoost对数据进行训练 训练集:测试集=8:2
(这两个模型训练?机器学习测试?)
结果表明,SNV-tSNE数据具有较好的可分性,与降维可视化所展示的结果一致
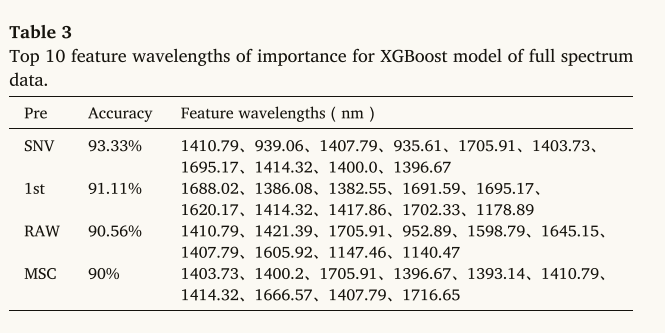
全光谱数据的XGBoost模型的前10个重要特征波长,如表3所示


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









