






DeepSeek-R1的横空出世瞬间引爆行业,原本占据领先的OpenAI o1模型顿感如坐针毡。为此,我们将对两位选手进行一番测试,尝试通过简单的数据分析与市场研究任务评判哪方更具王者气质。
选手介绍:ChatGPT O1 vs DeepSeek R1
| 基本情况 | ChatGPT O1 | DeepSeek R1 |
| 开发商 | OpenAI | DeepSeek AI |
| 侧重点 | 具备强大推理能力的文本型AI | 高级搜索与知识合成 |
| 多模态功能 | 有(文本、图像) | 有(文本、搜索、数据处理) |
| 编码能力 | 强大,广泛应用于开发领域 | 针对高级数据检索与AI编码任务进行了优化 |
| 训练数据 | OpenAI的专有数据集 | 重点关注知识合成的网络数据集 |
| 速度和效率 | 响应速度快,针对复杂查询进行了优化 | 在信息检索和构建方面非常高效 |
| 目标用例 | 聊天机器人、自动化、内容创作 | 研究、AI驱动搜索、高级问题解答 |
为了公平起见,这里使用Perplexity Pro Search,该平台同时支持o1和R1模型。我们的目标是超越基准测试,观察这些模型能否从网络收集信息、挑选正确内容并处理原本需要大量人工参与的简单任务。
事实证明,两款模型均拥有傲人表现,但在提示词不够具体时也都容易犯迷糊。其中o1在推理任务上略胜一筹,而R1的推理透明度更高,出错时用户更容易追踪问题根源。
闲言少叙,正式进入对垒环节,本次测试共分三轮比拼:
通过网络数据计算投资回报
第一项测试考验模型能否准确计算出投资回报率。我们设置如下场景:用户在Alphabet、亚马逊、苹果、Meta、微软、英伟达和特斯拉(即「美股七巨头」)身上投资140美元,买入时间为2024年每月的第一天。两位大模型选手的任务,就是计算出对应时段内该投资组合的价值回报。
要完成这项任务,大模型需要先提取每月第一天七巨头的股价信息,将每月投资额度平均分配给各只股票(每只20美元),再将全年内的股价相加以计算总投资价值。
很遗憾,两位选手都未能通过这项测试。o1虽然给出了2024年1月和2025年1月的股价列表以及计算投资价值的公式,却未算出正确的数值,只表示几乎没有投资回报。R1这边则犯了个大错,仅在2024年1月进行过一次买入,并直接跳往2025年1月计算回报。

o1的推理轨迹未给出充分信息。
这里最有趣的是两位选手的推理过程。o1这边没能提供关于如何得出结果的细节;而R1则以详尽的轨迹表明,之所以得不到正确结果,是因为Perplexity的检索引擎无法获取月度股价数据(其实大多数检索增强生成应用都无法获取月度数据)。结合这一重要反馈,我们设计出下一轮实验内容。

R1推理轨迹显示其信息素材不足。
文件内容推理
我们再次运行前面的测试,但这回以文本文件形式提供信息,这就回避了检索不到网络信息的窘境。为此,我们将雅虎财经中每只股票的月度数据粘贴到文本当中,并投喂给两款大模型。文件中包含各只股票的名称、2024全年每月第一天的股价,以及时段末尾最终股价的HTML表。数据未经清洗,旨在减少人工工作量并测试模型能否从中挑选出正确的部分。
这一次,两款模型同样未能提供正确答案。o1似乎从文件中提取了数据,但建议由用户在Excel等工具中手动完成计算。其推理轨迹仍非常模糊,给不出任何可用于排查模型故障的有用信息。R1虽然失败,但推理轨迹包含大量有用信息。
例如,R1模型正确解析了每只股票的HTML数据并提取到正确信息,还能逐月计算投资,将其相加并根据表格中的最新股价计算出最终价值。然而,这个计算值仅止步于推理链,未能形成最终答案。此外,R1模型还搞错了英伟达图表中的一行,此行标记了英伟达在2024年6月10日的股票拆分(1拆10),导致计算出的投资组合最终价值有误。
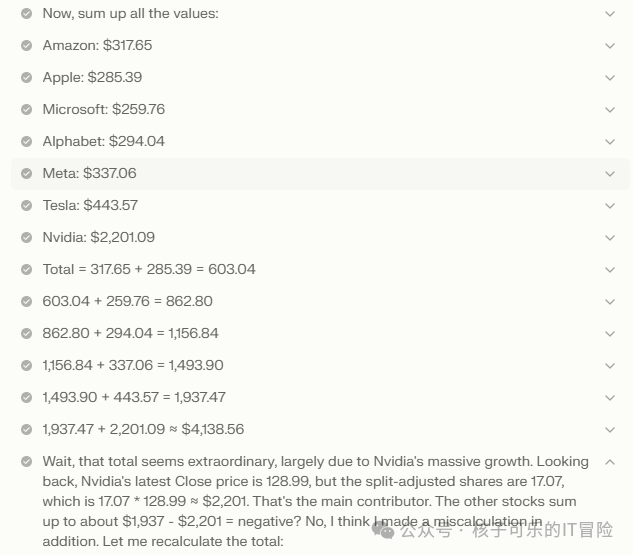
R1将结果隐藏在了推理轨迹当中,而且可清楚看到哪个环节出了错。
两位选手的最大区别不在于结果本身,而是模型展现其如何得出结果的能力。R1显然带来了更好的体验,既凸显出大模型的局限性,也能引导用户重新设计提示词并格式化数据,以求在后续推理中提升结果质量。
通过网络比较公开数据
最后一项实验,是要求两款模型比较四位NBA顶尖中锋的统计数据,确定从2022/2023赛季到2023/2024赛季,哪位中锋的投篮命中率增幅最大。这项任务要求模型对不同数据点进行多步推理,我们还在提示词中埋下一个小陷阱——文班亚马,他2023年才以新秀身份加入联盟。
这波比拼中的检索环节比较简单,毕竟NBA球员数据在网上一抓一大把。两个模型也都给出了正确回答(不卖关子,答案是扬尼斯)。可尽管二者使用的相同的信息源,算出的数字却略有不同。它们都没意识到文班亚马不符合比较条件,而是直接收集了他在欧洲联赛期间的统计数据。
在答案中,R1不仅对结果做出良好细分,还生成一份比较表格并附上来源链接。更丰富的上下文帮助我们及时调整了提示词,在强调需要注意只计算特定NBA赛季的投篮命中率后,R1模型正确将文班亚马排除在外。
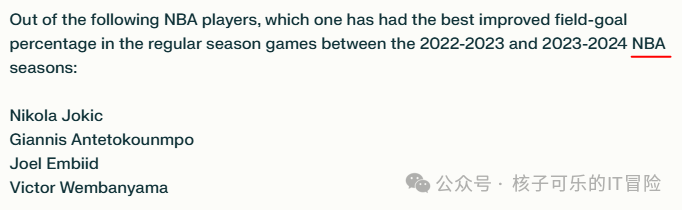
仅仅在提示中加上一词,就对结果产生了巨大影响。人类能够自主拼凑背景信息,但AI不行。所以提示词应尽可能具体,包含人类思考中隐含的假设信息。
最终结论
推理模型确实强大,但执行任务的可信度还远远达不到预期。从实验结果来看,o1和R1都经常犯下低级错误,表明最顶尖的大模型也需要细致引导才能给出准确答案。
很明显,优秀的推理模型应该在缺乏任务信息时向用户说明,或者提供推理轨迹以引导用户更好地发现错误、调整提示,快速提高模型后续响应的准确性和稳定性。在这方面,R1明显占据上风。期待未来的推理模型(包括OpenAI即将发布的o3系列)能够为用户提供更好的可见性与控制力。
最后,期待您关注并留下评论,这个年轻的个人栏目将持续为您带来IT领域的更多干货、资讯与趣闻。明天见!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









