






Selenium仍然是通过浏览器自动化进行网络抓取和测试的流行选择。这些任务传统上使用脚本语言(包括PowerShell)编写。为了利用Selenium在PowerShell中的功能,开发者社区创建了专用绑定,使这种集成成为可能。
然而,由于诸如Cloudflare之类的复杂反机器人系统,网络抓取变得越来越具有挑战性。在本综合指南中,您将探索:
- Selenium和PowerShell入门
- 在浏览器中与网页交互
- 避免反机器人系统的封锁
- 使用Scrapeless抓取浏览器解决Cloudflare挑战
让我们开始吧!
你可以使用Selenium和PowerShell吗?
Selenium是IT社区中最流行的无头浏览器库。其丰富且一致的API使其非常适合构建用于测试和网络抓取的浏览器自动化脚本。
PowerShell 是一个强大的命令外壳,可在Windows客户端和服务器环境中使用。浏览器自动化与脚本完美互补,这就是为什么开发者社区创建了selenium-powershell,它是Selenium WebDriver的PowerShell端口。
即使该库目前正在寻找维护者,它仍然是PowerShell中网络自动化的首选模块。
注意:如果您需要在开始本Selenium PowerShell教程之前复习基础知识,请复习无头浏览器抓取和使用PowerShell进行网络抓取的基础知识。
使用Selenium和PowerShell进行网络抓取:基础知识
注意:本文中的示例是为Windows操作系统设计的,因为某些功能(如Selenium-PowerShell模块和COM对象)是Windows特有的。如果您使用的是macOS或Linux,则可能需要相应地调整这些脚本。
在本节中,我们将介绍使用Selenium与PowerShell的基本概念。在深入研究G2等更复杂的受Cloudflare保护的网站之前,了解基础知识很有帮助。
我们的目标:G2评论
在本教程中,我们将重点关注从G2抓取评论,特别是Airtable评论:https://www.g2.com/products/airtable/reviews。这是一个现实世界的例子,它是一个受Cloudflare保护的网站,这对传统的抓取方法提出了挑战。
以下是使G2成为有趣目标的原因:
- 它受Cloudflare保护,阻止大多数基本的抓取尝试
- 它包含有价值的商业软件评论,可用于市场研究
- 评论的结构使其非常适合数据提取
- 它代表了通常位于反机器人系统背后的那种高价值商业数据
让我们首先看看传统的Selenium与PowerShell方法如何难以应对此网站,然后看看Scrapeless如何解决这个问题。
获取正确的Chrome WebDriver(2025年2月)
使用PowerShell设置Selenium时,一个关键步骤是确保您拥有与Chrome浏览器匹配的正确ChromeDriver版本。截至2025年2月28日,以下是最新版本的Chrome及其相应的WebDriver:
Chrome稳定版 (133.0.6943.141):
- Windows 64位版ChromeDriver:chromedriver-win64.zip
- Windows 32位版ChromeDriver:chromedriver-win32.zip
- Mac (Intel)版ChromeDriver:chromedriver-mac-x64.zip
- Mac (M1/M2)版ChromeDriver:chromedriver-mac-arm64.zip
- Linux版ChromeDriver:chromedriver-linux64.zip
如果您使用的是其他Chrome版本(Beta版、Dev版或Canary版),请确保从Chrome for Testing下载页面的相应部分下载匹配的ChromeDriver。
下载适合您系统的ChromeDriver,解压缩ZIP文件,并将可执行文件放在您的项目文件夹中。然后在您的PowerShell脚本中引用此位置:
$Driver = Start-SeChrome -WebDriverDirectory '/path/to/chromedriver/folder' -Headless使用正确的ChromeDriver版本至关重要 - 如果版本不匹配,Selenium将抛出错误并无法正确控制Chrome。
尝试使用基本Selenium抓取G2
现在,让我们尝试使用基本Selenium设置访问G2评论:
Import-Module -Name Selenium
# 初始化Selenium WebDriver
$Driver = Start-SeChrome -WebDriverDirectory './chromedriver-win64' -Headless
# 访问G2评论页面
Enter-SeUrl 'https://www.g2.com/products/airtable/reviews' -Driver $Driver
# 等待页面加载片刻
Start-Sleep -Seconds 5
# 获取页面标题
$Title = $Driver.Title
Write-Host "页面标题:$Title"
# 打印页面源代码
$Html = $Driver.PageSource
$Html | Out-File -FilePath "g2_response.html"
# 关闭浏览器
Stop-SeDriver -Driver $Driver当您运行此脚本时,您不会获得实际的G2评论页面,而是可能会看到:
- Cloudflare挑战页面
- 像“请稍候...”或“正在检查您的浏览器...”之类的标题
- 包含Cloudflare JavaScript挑战的HTML
这是因为Cloudflare检测到像Selenium这样的自动化浏览器并提出了基本Selenium配置无法自动解决的挑战。
G2抓取挑战:了解评论结构
在尝试提取数据之前,让我们了解我们要抓取的内容。G2评论具有结构化格式,包括:
- 评论标题:通常是评论的摘录总结
- 评分:显示为星级(满分5星)
- 日期:评论发布的时间
- 评论文本:分为“您最喜欢什么?”和“您最不喜欢什么?”等部分
- 用户信息:撰写评论的用户详细信息
以下是HTML结构中典型的G2评论的样子:
<div class="paper__bd">
<div class="d-f mb-1">
<div class="f-1 d-f ai-c mb-half-small-only">
<div class="stars large xlarge--medium-down stars-10"></div>
<div class="time-stamp pl-4th ws-nw">
<span><span class="x-current-review-date" data-poison-date="">
<meta content="2025-02-11" itemprop="datePublished">
<time datetime="2025-02-11">Feb 11, 2025</time>
</span></span>
</div>
</div>
</div>
<div class="d-f">
<div class="f-1">
<div data-poison="">
<a class="pjax" href="https://www.g2.com/products/airtable/reviews/airtable-review-10822745">
<div class="m-0 l2" itemprop="name">"Helped us get a handle on our complicated team-based scheduling and management."</div>
</a>
</div>
<div data-poison-text="">
<div itemprop="reviewBody">
<div>
<div class="l5 mt-2">What do you like best about Airtable?</div>
<div>
<p class="formatted-text">The best part about airtable is it's customiizable nature. We worked with a tech specialist to configure Airtable to meet our unique needs and it has so far been adaptable to everything we needed it to do...</p>
</div>
</div>
<!-- More review sections... -->
</div>
</div>
</div>
</div>
</div>解决方法:用于绕过Cloudflare的Scrapeless抓取浏览器
即使使用高级Selenium配置,许多抓取项目也会被Cloudflare的安全系统阻止。这就是Scrapeless抓取浏览器作为改变游戏规则的解决方案出现的地方。
什么是Scrapeless抓取浏览器?
Scrapeless抓取浏览器是一个高性能解决方案,它提供无头浏览器环境,允许您绕过JavaScript挑战而无需维护您自己的基础设施。它与Puppeteer和Playwright集成,以实现无缝自动化,并提供:
- 99.9%的成功率绕过Cloudflare挑战
- 与Puppeteer/Playwright无缝兼容
- AI驱动,自动适应最新的安全策略
- 全球覆盖,访问地理限制内容
立即登录Scrapeless仪表板并在API密钥管理中创建您的API密钥
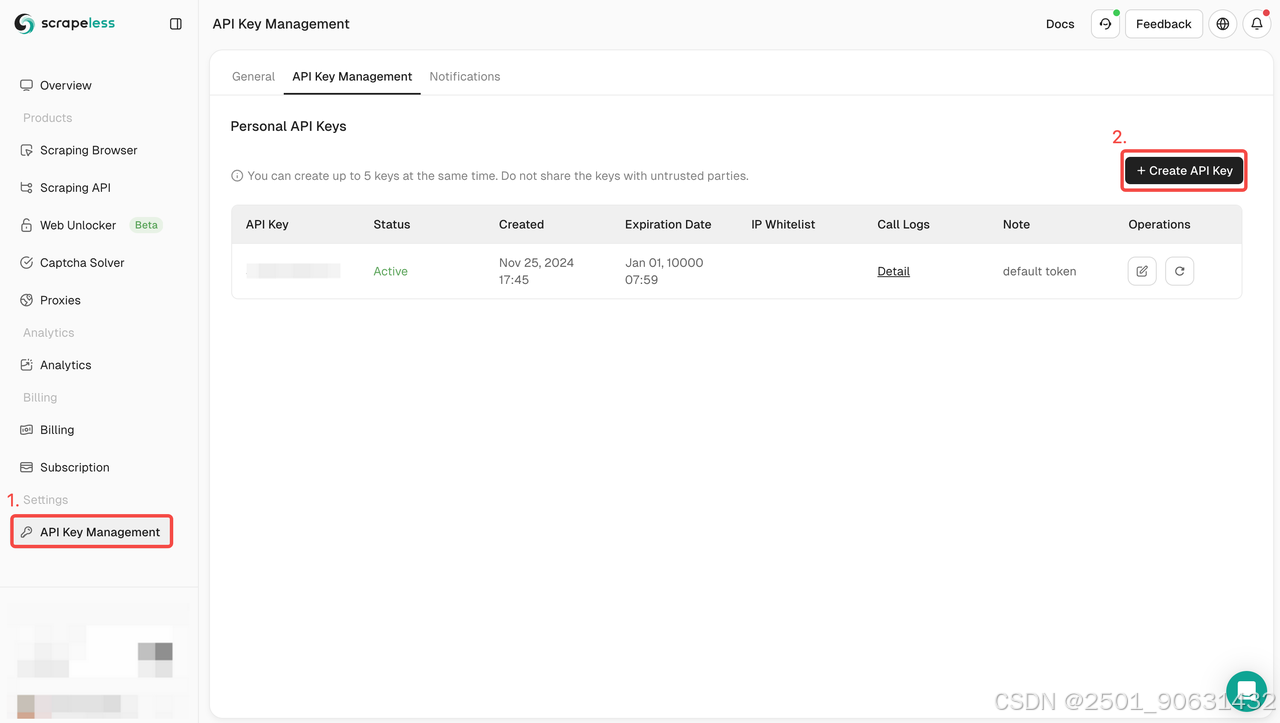
使用Scrapeless抓取浏览器提取G2评论
既然我们了解了为什么标准的Selenium与PowerShell难以应对像G2这样的受Cloudflare保护的网站,那么让我们使用Scrapeless抓取浏览器来实现一个解决方案。
使用Puppeteer设置Scrapeless抓取浏览器
使用Scrapeless抓取浏览器最有效的方法是通过Node.js使用Puppeteer。以下是设置方法:
- 安装Node.js
- 从nodejs.org下载并安装Node.js
- 通过打开命令提示符并键入以下命令来验证安装:
node --version
npm --version- 创建项目文件夹
- 为您的抓取项目创建一个新文件夹
- 在此文件夹中打开命令提示符
- 安装所需软件包
- 使用npm安装puppeteer-core:
npm install puppeteer-core- 创建您的抓取脚本
- 使用以下代码创建一个名为scrape.js的文件:
// scrape.js
const puppeteer = require('puppeteer-core');
async function scrapeG2Reviews() {
// 替换为您实际的Scrapeless API令牌
const API_TOKEN = 'YOUR_API_TOKEN_HERE';
// 配置与Scrapeless抓取浏览器的连接
const connectionURL = `wss://browser.scrapeless.com/browser?token=${API_TOKEN}&session_ttl=180&proxy_country=ANY`;
console.log('连接到Scrapeless抓取浏览器...');
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('已连接!');
const page = await browser.newPage();
// 设置更长的导航超时时间
page.setDefaultNavigationTimeout(120000);
// 数组用于保存所有评论
const allReviews = [];
// 要抓取的页面数
const pagesToScrape = 3;
for (let currentPage = 1; currentPage <= pagesToScrape; currentPage++) {
console.log(`导航到第${currentPage}页...`);
// 直接导航到指定的页码
const pageUrl = currentPage === 1
? 'https://www.g2.com/products/airtable/reviews'
: `https://www.g2.com/products/airtable/reviews?page=${currentPage}`;
await page.goto(pageUrl, {
waitUntil: 'networkidle2',
timeout: 60000
});
console.log(`第${currentPage}页已加载。正在截屏...`);
// 拍摄屏幕截图以验证页面是否已正确加载
await page.screenshot({ path: `g2_page_${currentPage}.png` });
// 等待页面内容加载
// 尝试不同的选择器,因为结构可能已更改
try {
console.log('等待内容加载...');
// 首先尝试原始选择器
await page.waitForSelector('.paper__bd', { timeout: 10000 })
.then(() => console.log('找到选择器:.paper__bd'))
.catch(() => console.log('未找到选择器.paper__bd,正在尝试其他方法...'));
// 如果我们仍然在这里,让我们使用另一种方法检查页面结构
console.log('正在分析页面结构...');
// 获取页面标题以验证我们是否在正确的页面上
const pageTitle = await page.title();
console.log('页面标题:', pageTitle);
// 使用更通用的方法提取评论
console.log('正在提取评论...');
// 尝试使用更具弹性的方法提取评论
const pageReviews = await page.evaluate(() => {
// 使用多个选择器查找评论容器
const reviewElements = Array.from(
document.querySelectorAll('.paper__bd, .review-item, .reviews-section article, [data-testid="review-card"]')
);
console.log(`找到${reviewElements.length}个潜在的评论元素`);
if (reviewElements.length === 0) {
// 如果未找到具有特定选择器的评论,让我们转储页面结构
const html = document.documentElement.outerHTML;
return { error: '未找到评论', html: html.substring(0, 5000) }; // 前5000个字符用于调试
}
return reviewElements.map(review => {
// 尝试使用多个潜在选择器获取标题
const titleElement =
review.querySelector('[itemprop="name"], .review-title, h3, h4') ||
review.querySelector('a.pjax div');
const title = titleElement ? titleElement.innerText.trim() : '无标题';
// 尝试使用多个潜在选择器获取日期
const dateElement =
review.querySelector('time, .review-date, [data-testid="review-date"]') ||
review.querySelector('.time-stamp');
const date = dateElement ? dateElement.innerText.trim() : '无日期';
// 尝试使用多种方法获取评分
let rating = 0;
const starsElement = review.querySelector('.stars, .rating, [data-testid="star-rating"]');
if (starsElement) {
// 检查stars-X类
const starsClass = starsElement.className;
const starsMatch = starsClass.match(/stars-(\d+)/);
if (starsMatch) {
rating = parseInt(starsMatch[1]) / 2;
} else {
// 否则检查可能包含评分的aria-label
const ariaLabel = starsElement.getAttribute('aria-label');
if (ariaLabel) {
const ratingMatch = ariaLabel.match(/(\d+(\.\d+)?)/);
if (ratingMatch) {
rating = parseFloat(ratingMatch[1]);
}
}
}
}
// 尝试使用多个潜在选择器获取评论文本
const textElements = review.querySelectorAll('.formatted-text, .review-content, p, [data-testid="review-content"]');
let content = '';
textElements.forEach(el => {
const text = el.innerText.trim();
if (text && !text.includes('Review collected by and hosted on G2.com')) {
content += text + '\n\n';
}
});
return {
title,
date,
rating,
content: content.trim() || '未找到内容'
};
});
});
if (pageReviews.error) {
console.log('提取评论出错:', pageReviews.error);
console.log('页面HTML片段:', pageReviews.html);
} else {
console.log(`从第${currentPage}页提取了${pageReviews.length}条评论`);
// 添加到我们的集合中
allReviews.push(...pageReviews);
}
} catch (error) {
console.error('页面出错:', error);
// 在出错时拍摄另一个屏幕截图以进行调试
await page.screenshot({ path: `error_page_${currentPage}.png` });
// 转储页面HTML以进行调试
const html = await page.content();
require('fs').writeFileSync(`error_page_${currentPage}.html`, html);
console.log(`已将错误页面HTML保存到error_page_${currentPage}.html`);
}
// 在页面之间短暂暂停,以免影响服务器
await new Promise(r => setTimeout(r, 2000));
}
console.log(`总共提取了${allReviews.length}条评论`);
// 将所有评论保存到文件
require('fs').writeFileSync('g2_reviews.json', JSON.stringify(allReviews, null, 2));
console.log('评论已保存到g2_reviews.json');
await browser.close();
console.log('完成!');
}
scrapeG2Reviews().catch(console.error);- 运行脚本
- 使用以下命令执行脚本:
node scrape.jsJSON输出格式
运行脚本后,您将拥有一个g2_reviews.json文件,其内容如下所示:
[
{
"title": "\"Helped us get a handle on our complicated team-based scheduling and management.\"",
"date": "Feb 11, 2025",
"rating": 5,
"content": "What do you like best about Airtable?\nThe best part about airtable is it's customiizable nature. We worked with a tech specialist to configure Airtable to meet our unique needs and it has so far been adaptable to everything we needed it to do. It has a huge capacity in terms of features and we were able to get it up and running in a fairly short period of time.\n\nWhat do you dislike about Airtable?\nThere are no real downsides except the intial learning curve. I believe we could have built Airtable out as we needed but it would have been a bigger intial time investment. Working with a tech specialist who knew Airtable well really helped us get up and running fast. It was worth the cost."
},
{
"title": "\"Great for organization, has changed our workflow\"",
"date": "Feb 8, 2025",
"rating": 4.5,
"content": "What do you like best about Airtable?\nWhat I like best about Airtable is its flexibility and customizability. It allows us to create databases that perfectly fit our needs, with custom fields, views, and formulas. The ability to link records between tables is incredibly powerful.\n\nWhat do you dislike about Airtable?\nSometimes the learning curve can be steep for new users, especially when dealing with more complex formulas and automations. The pricing can also become quite expensive as your needs grow and you require more records or features."
},
{
"title": "\"Powerful database tool with a spreadsheet interface\"",
"date": "Jan 29, 2025",
"rating": 4,
"content": "What do you like best about Airtable?\nAirtable combines the familiarity of spreadsheets with the power of a database. I appreciate how it allows for different views of the same data - grid, kanban, calendar, etc. It's intuitive enough for non-technical users but powerful enough for complex data management.\n\nWhat do you dislike about Airtable?\nThe free tier is quite limited, and pricing jumps significantly for premium features. Sometimes performance can slow down with large datasets, and there are occasional sync issues when multiple team members are editing simultaneously."
}
]PowerShell集成:从PowerShell使用Scrapeless抓取浏览器
如果您更喜欢使用PowerShell,您可以创建一个调用Node.js脚本并处理结果的包装器脚本:
- 创建PowerShell包装器脚本
- 使用以下代码创建一个名为run-scraper.ps1的文件:
# 文件:run-scraper.ps1
Write-Host "使用Scrapeless抓取浏览器启动G2.com抓取..."
# 创建输出文件夹
$outputFolder = "G2_Reviews_" + (Get-Date -Format "yyyyMMdd_HHmmss")
New-Item -ItemType Directory -Path $outputFolder -Force | Out-Null
# 运行Node.js脚本并捕获输出
$jsonFile = Join-Path $outputFolder "reviews.json"
node scrape.js > $jsonFile
Write-Host "Node.js抓取完成。正在处理结果..."
# 检查文件是否包含有效的JSON数据
try {
# 读取文件内容
$content = Get-Content -Path $jsonFile -Raw
# 提取JSON部分(假设它是所有console.log消息后的输出)
if ($content -match '\[.*\]') {
$jsonContent = $Matches[0]
Set-Content -Path $jsonFile -Value $jsonContent
# 将JSON解析为PowerShell对象
$reviews = $jsonContent | ConvertFrom-Json
# 导出到CSV
$csvPath = Join-Path $outputFolder "g2_reviews.csv"
$reviews | Export-Csv -Path $csvPath -NoTypeInformation -Encoding UTF8
Write-Host "已成功提取$($reviews.Count)条评论"
Write-Host "结果已保存到:$csvPath"
# 基本分析
$averageRating = ($reviews | Measure-Object -Property rating -Average).Average
Write-Host "平均评分:$averageRating(满分5分)"
$ratingDistribution = $reviews | Group-Object -Property rating | Sort-Object -Property Name
foreach ($ratingGroup in $ratingDistribution) {
Write-Host "$($ratingGroup.Name)星:$($ratingGroup.Count)条评论"
}
} else {
Write-Error "在输出中找不到JSON数据"
}
} catch {
Write-Error "处理JSON数据出错: $_"
}- 运行PowerShell包装器脚本
- 打开PowerShell
- 导航到您的项目文件夹
- 执行脚本:
.\run-scraper.ps1- 查看结果
- 该脚本创建一个带有JSON和CSV结果的日期文件夹
- 控制台中显示基本统计信息
- 可以使用Excel或其他应用程序打开CSV文件以进行进一步分析
高级示例:使用Scrapeless抓取浏览器进行多页抓取
对于更高级的用例,以下示例显示了如何从多个页面抓取评论:
// 文件:scrape-g2-multipage.js
const puppeteer = require('puppeteer-core');
async function scrapeG2ReviewsMultiPage() {
// 替换为您实际的Scrapeless API令牌
const API_TOKEN = 'YOUR_API_TOKEN_HERE';
// 配置与Scrapeless抓取浏览器的连接
const connectionURL = `wss://browser.scrapeless.com/browser?token=${API_TOKEN}&session_ttl=300&proxy_country=ANY`;
console.log('连接到Scrapeless抓取浏览器...');
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('已连接!正在打开G2.com...');
const page = await browser.newPage();
// 设置合理的导航超时时间
page.setDefaultNavigationTimeout(60000);
// 数组用于保存所有评论
const allReviews = [];
// 函数用于从当前页面提取评论
const extractReviews = async () => {
return page.evaluate(() => {
return Array.from(document.querySelectorAll('.paper__bd')).map(review => {
// 标题
const titleElement = review.querySelector('a.pjax div[itemprop="name"]');
const title = titleElement ? titleElement.innerText : '无标题';
// 日期
const dateElement = review.querySelector('time');
const date = dateElement ? dateElement.innerText : '无日期';
// 评分
const starsElement = review.querySelector('.stars');
let rating = 0;
if (starsElement) {
const starsClass = starsElement.className;
const match = starsClass.match(/stars-(\d+)/);
if (match) {
rating = parseInt(match[1])/2;
}
}
// 评论内容
const contentElements = review.querySelectorAll('.formatted-text');
let content = '';
contentElements.forEach(el => {
const text = el.innerText;
if (!text.includes('Review collected by and hosted on G2.com')) {
content += text + '\n\n';
}
});
return {
title,
date,
rating,
content: content.trim()
};
});
});
};
// 导航到第一页
await page.goto('https://www.g2.com/products/airtable/reviews', {
waitUntil: 'networkidle2'
});
// 等待评论加载
await page.waitForSelector('.paper__bd', {timeout: 30000});
// 拍摄第一页的屏幕截图
await page.screenshot({ path: 'page1.png' });
// 要抓取的页面数(演示限制)
const pagesToScrape = 3;
let currentPage = 1;
while (currentPage <= pagesToScrape) {
console.log(`正在抓取第${currentPage}页...`);
// 从当前页面提取评论
const pageReviews = await extractReviews();
console.log(`在第${currentPage}页上找到${pageReviews.length}条评论`);
// 添加到我们的集合中
allReviews.push(...pageReviews);
// 检查是否有下一页按钮const hasNextPage = await page.evaluate(() => {
const nextButton = document.querySelector('a.next_page');
return nextButton && !nextButton.classList.contains('disabled');
});
if (hasNextPage && currentPage < pagesToScrape) {
// 直接跳转到下一页URL
currentPage++;
await page.goto(`https://www.g2.com/products/airtable/reviews?page=${currentPage}`, {
waitUntil: 'networkidle2'
});
// 等待新页面上的评论加载
await page.waitForSelector('.paper__bd', {timeout: 30000});
// 截取新页面的屏幕截图
await page.screenshot({ path: `page${currentPage}.png` });
} else {
break;
}
}
console.log(`已提取的评论总数:${allReviews.length}`);
// 以JSON格式输出所有评论
console.log(JSON.stringify(allReviews, null, 2));
await browser.close();
console.log('完成!');
}
scrapeG2ReviewsMultiPage().catch(console.error);分步指南:开始使用Scrapeless抓取浏览器
为了帮助您开始使用Scrapeless抓取浏览器绕过Cloudflare并从受保护的网站提取数据,请按照以下分步指南操作:
第1步:注册Scrapeless
- 登录Scrapeless 创建您的帐户
- 完成注册流程并开始免费试用
- 导航到您的仪表板以获取您的API密钥
4. 复制API密钥以在您的脚本中使用
第2步:设置您的环境
- 从nodejs.org安装Node.js
- 创建一个新的项目文件夹
- 在此文件夹中打开命令提示符或终端
- 安装puppeteer-core包:
npm install puppeteer-core第3步:创建您的抓取脚本
- 在您的项目文件夹中创建一个新文件(例如,scrape.js)
- 粘贴下面的基本抓取模板:
const puppeteer = require('puppeteer-core');
(async () => {
// 用您的实际Scrapeless API令牌替换
const API_TOKEN = 'YOUR_API_TOKEN_HERE';
const connectionURL = `wss://browser.scrapeless.com/browser?token=${API_TOKEN}&session_ttl=180&proxy_country=ANY`;
console.log('连接到Scrapeless抓取浏览器...');
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('已连接!');
const page = await browser.newPage();
await page.goto('https://www.example.com', {
waitUntil: 'networkidle2',
timeout: 60000
});
console.log('页面加载成功!');
console.log('页面标题:', await page.title());
// 截取屏幕截图
await page.screenshot({ path: 'screenshot.png' });
// 您的抓取逻辑在这里
// ...
await browser.close();
console.log('完成!');
})().catch(console.error);- 为您的目标网站定制脚本
- 将YOUR_API_TOKEN_HERE替换为您实际的Scrapeless API令牌
- 将https://www.example.com替换为您的目标URL
第4步:运行您的脚本
- 在您的项目文件夹中打开命令提示符或终端
- 使用以下命令运行您的脚本:
node scrape.js- 检查控制台输出和屏幕截图以验证脚本是否正常工作
第5步:与PowerShell集成(可选)
如果您想与PowerShell集成,请创建如上一节所示的包装器脚本。
⚠️ 想轻松突破数据抓取难题,解锁海量准确数据?别犹豫!立即注册Scrapeless,享受免费试用,无需任何费用。
比较传统方法与Scrapeless抓取浏览器
为了更好地理解Scrapeless抓取浏览器为网络抓取生态系统带来的价值,让我们将传统的Selenium与PowerShell方法与Scrapeless解决方案进行比较:
| 功能 | 传统的Selenium + PowerShell | Scrapeless抓取浏览器 |
|---|---|---|
| 绕过Cloudflare | 有限的,需要大量的定制 | 99.9%的成功率,具有AI驱动的适应性 |
| 设置复杂性 | 高(需要本地WebDriver,维护) | 低(基于云,没有本地依赖项) |
| JavaScript支持 | 基本的,可能需要自定义脚本 | 使用完整的JS执行进行高级渲染 |
| 反检测 | 基本的(用户代理定制) | 综合的浏览器指纹保护 |
| 可扩展性 | 受本地资源限制 | 基于云的基础设施,可处理大量数据 |
| 维护 | 高(需要定期更新WebDriver) | 无(托管服务) |
如比较所示,虽然Selenium与PowerShell为网络自动化提供了一个良好的起点,但Scrapeless抓取浏览器为现代网络抓取挑战提供了一个更强大、更可扩展、更有效的解决方案,尤其是在处理像Cloudflare这样的反机器人系统时。
结论
在本综合教程中,您学习了:
- 使用Selenium与PowerShell抓取受Cloudflare保护的网站的挑战
- Scrapeless抓取浏览器如何提供绕过Cloudflare的强大解决方案
- 设置和使用Scrapeless抓取浏览器的分步说明
- 多页抓取和数据提取的高级技术
- 如何集成Node.js和PowerShell以实现完整的抓取工作流程
虽然Selenium与PowerShell为自动化提供了坚实的基础,但现代网络抓取通常需要专门的工具来克服日益复杂的反机器人措施。Scrapeless抓取浏览器提供了一个强大、无缝的解决方案,它可以与现有工作流程集成,同时消除维护复杂抓取基础设施的麻烦。
通过使用Scrapeless抓取浏览器和Puppeteer,您可以可靠地从受Cloudflare保护的网站(如G2)提取数据,从而可以访问原本难以获得的有价值的商业情报和市场研究数据。
注册免费试用 Scrapeless,立即开始从受Cloudflare保护的网站提取数据!
更多值得关注的解决方案:Scrapeless Deep SerpApi
Deep SerpApi是一个专门为大型语言模型(LLM)和AI代理设计的专业搜索引擎API。它提供实时、准确和公正的信息,使AI应用程序能够高效地从Google及其他来源检索和处理数据。
✅ 全面的数据覆盖接口:涵盖20多个Google SERP场景和主流搜索引擎。
✅ 经济高效:Deep SerpApi的定价从每千次查询0.10美元起,响应时间为1-2秒,使开发人员和企业能够高效且低成本地获取数据。
✅ 高级数据集成能力:可以集成来自所有可用在线渠道和搜索引擎的信息。
✅ 获取实时更新,数据在过去24小时内刷新。
作为我们未来路线图的一部分,我们完全致力于满足AI开发人员的需求,简化动态网络信息与AI驱动解决方案的集成。目标是提供一个一体化API,允许通过单个调用进行无缝搜索和数据提取。
🎺🎺激动人心的公告!
开发者支持计划:将Scrapeless Deep SerpApi集成到您的AI工具、应用程序或项目中。[我们已经支持Dify,并将很快支持Langchain、Langflow、FlowiseAI和其他框架]。然后在GitHub或社交媒体上分享您的成果,您将获得1-12个月的免费开发者支持,每月最高可达500美元。
如果您有任何问题或需要帮助,请随时加入Scrapeless Discord社区!您不仅可以获得即时支持,而且还可以率先了解最新的产品更新和独家优惠!
注意:在抓取网站时,请始终尊重robots.txt文件、网站服务条款和适用的法律。负责任和道德地使用本教程中的信息。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









