







Google Maps列出了数百万家企业,访问这些宝贵的数据可以提供对消费者行为、市场趋势和竞争分析的深入了解。通过抓取Google Maps数据和评论,开发者、营销人员和数据分析师可以改变他们的工作方式,使他们能够高效地提取基于位置的信息。
在本指南中,我们将引导您完成使用Python抓取Google Maps的过程,涵盖从设置环境到提取数据和聚合评论的所有内容。
了解Google Maps数据
Google Maps提供了大量对各种用例(例如商业分析、市场研究和竞争情报)具有巨大价值的数据。为了有效地抓取Google Maps数据,必须了解可用的数据、其结构以及最佳的提取方法。让我们仔细看看Google Maps提供的不同类型的数据以及如何高效地提取它们。
Google Maps数据类型
当您爬取Google Maps时,最常见的类型是:
- **商家信息:**Google Maps上的每个位置或企业都包含详细信息,包括其名称、地址、联系信息和网站。这些数据通常显示在商家资料中,可以抓取以收集有关各个行业企业的关键信息。
- **评分和评论:**Google Maps上最有价值的数据点之一是与商家相关的评分和评论。这包括平均星级评分、个人评论、评论者姓名、评论日期以及有时评论者的照片。评论可以提供关于客户满意度和情绪的宝贵见解。
- **位置坐标:**Google Maps上的每个地点都与地理坐标(纬度和经度)相关联,这对于地图绘制、地理定位或基于位置的分析非常有用。
- **营业时间:**Google Maps为大多数企业提供营业时间,包括开放和关闭时间,这些时间在周末或节假日可能会有所不同。
- **照片和媒体:**许多企业将其照片上传到他们的Google Maps资料中。可以抓取这些图像以提供有关企业其他背景信息,例如商店布局、食物(对于餐馆)或产品展示。
- **类别和标签:**Google Maps上的企业贴有类别标签(例如餐厅、健身房或酒店),有时还带有关键字,以帮助用户根据其需求过滤和搜索企业。
如何使用Python抓取Google Maps数据和评论
至少有三种方法可以高效地抓取Google Maps数据:
方法1:使用Scrapeless Google Maps API(推荐)
Scrapeless提供了一个结构良好的JSON,其中包含从Google Maps搜索结果中提取的所有相关信息。它还提供其他综合数据,例如评论、照片和导航路线。通过使用此API,您可以提取Google Maps数据,而无需构建自己的Google Maps抓取工具,从而节省大量时间和精力。
抓取的JSON输出示例:
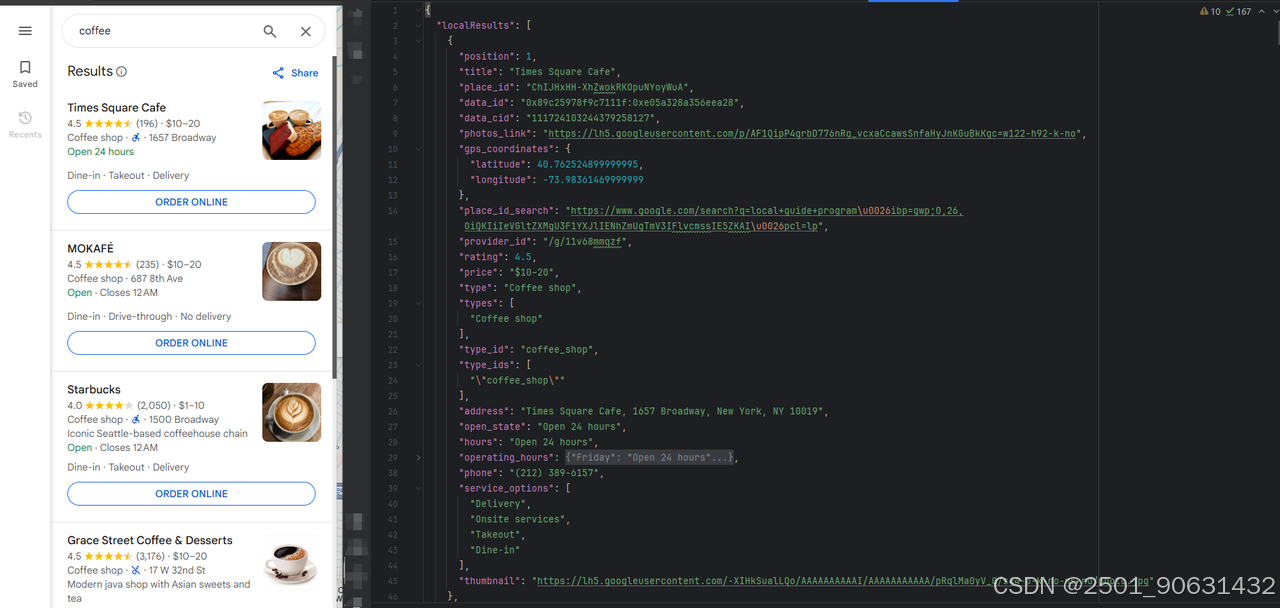
方法2:使用Google Places API
另一种方法是使用Google Places API,但首先,您需要设置一个Google Cloud项目并按照设置说明获取API密钥。配置完成后,您可以使用HTTP POST请求或Python SDK执行搜索。
缺点:
- 获取API密钥的初始设置很复杂。
- 您可能无法提取与直接抓取一样多的数据,尤其是在评论或某些媒体内容方面。
方法3:构建您自己的DIY Google Maps抓取工具
Google Maps动态加载其数据,因此需要使用Puppeteer等工具来正确抓取JavaScript渲染的页面。您可以利用Selenium、Pyppeteer或Playwright Python包来运行无头浏览器并提取相关的Google Maps数据。
缺点:
- 构建自己的Google Maps抓取工具非常耗时。
- 您可能会面临IP封锁、设置多个代理和管理请求限制等挑战。
使用Python抓取Google Map数据[快速简便]
在以下部分,我们将详细说明如何通过结合Python和Scrapeless来抓取Google Map数据。
步骤1:我们将使用的工具
让我们介绍如何使用Scrapeless API抓取Google Maps信息。通常,您可能会使用BeautifulSoup、Selenium、Puppeteer或Requests等库来构建自己的DIY解决方案以抓取Google Maps数据。
但是现在,您可以坐下来放松一下。我们将为您处理这些繁琐的任务。使用Scrapeless,您不再需要担心网络抓取过程中可能出现的各种问题。我们为您提供保障,您只需运行代码即可。
使用Scrapeless轻松抓取Google Map数据,让我们来处理复杂性。无论您是想抓取Google Maps评论、位置还是其他有价值的信息,Scrapeless都是您的理想解决方案。告别手动抓取的麻烦,迎接高效的数据提取。
步骤2:设置和准备
- 在免费注册scrapeless后,您可以获得5美元的免费额度来执行搜索。
- 导航到API密钥管理。然后单击“创建”以生成您的唯一API密钥。创建后,只需单击API密钥即可复制它。
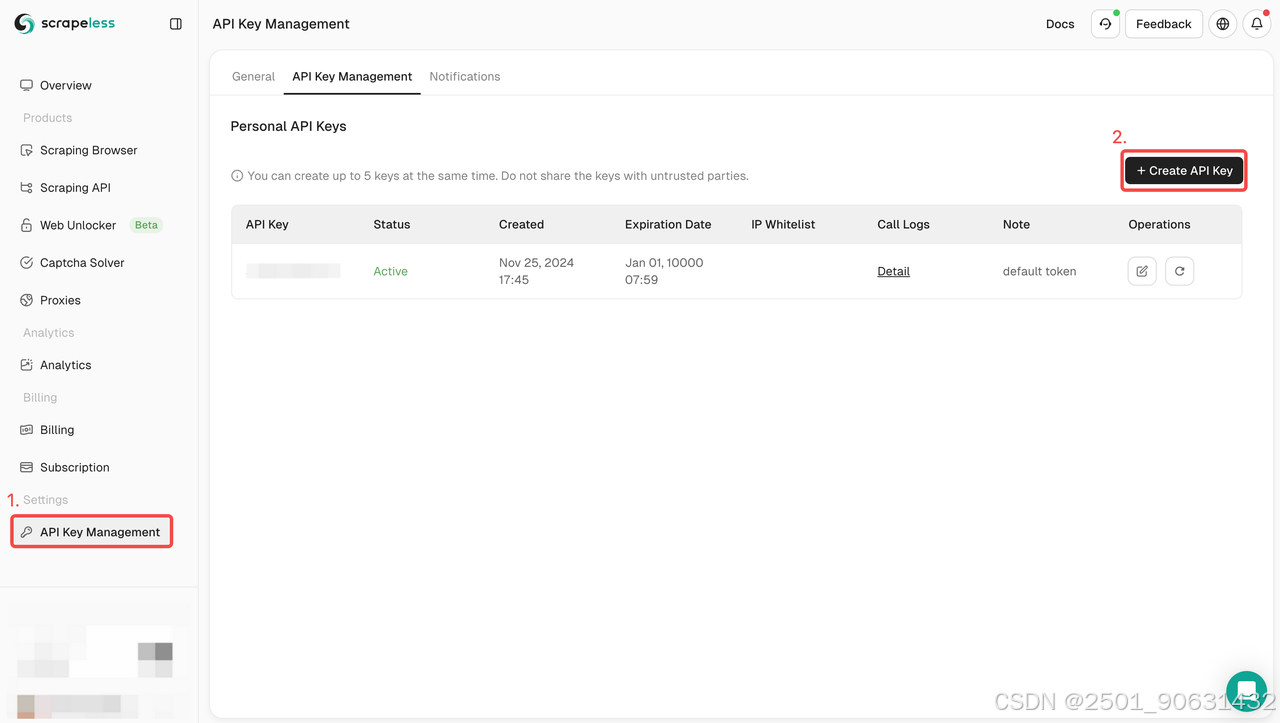
步骤3:编写scrapeless请求代码。
假设我们要根据咖啡关键字查找纽约的场所。此API需要一个ll参数,它是某个区域的纬度和经度。我们可以使用免费工具来获取纬度和经度。
访问此链接,我们只需要输入城市名称或区域,它就会返回相关的经度和纬度。我们将这些数字用逗号分隔,形成一个完整的ll参数。
以纽约为例:
- 纬度:40.712776
- 经度:-74.005974
因此ll值为@40.712776,-74.005974
一旦我们有了ll值,我们就可以形成scrapeless API的完整Python代码:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_maps",
"q": "coffee",
"type": "search",
"ll": "@40.712776,-74.005974.14z",
}
payload = Payload("scraper.google.maps", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()参数说明:
- 将your_token替换为您从Scrapeless网站获得的API密钥。
- q参数可与您要搜索的任何关键字一起使用。
- ll参数指定您要搜索的位置的纬度和经度。
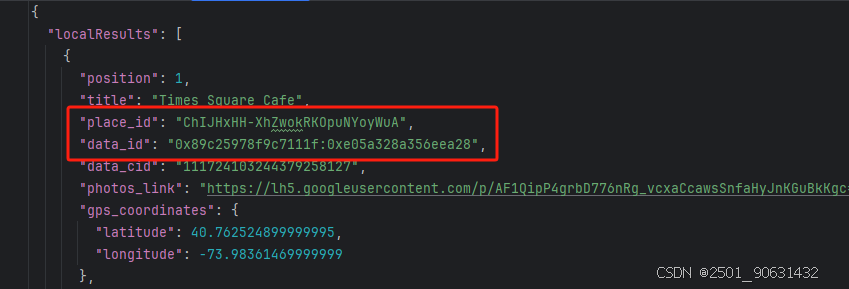
- 搜索结果可以在result['local_results']或result['place_results']中找到。
place结果和local结果之间的区别
Scrapeless API支持两种类型的搜索。默认情况下,类型设置为search,这会在local_results中返回一个结果数组。另一种类型是place,您将type设置为place并使用data参数提供特定位置或企业的详细信息。这种类型的搜索会返回place_results。
更广泛地说,当搜索范围更广时,会提供local_results列表,而当查询非常具体时,或者当您使用type=place的place_id或data来获取特定位置的结果时,place_results会提供特定位置的详细信息。
有关如何使用这些参数的详细说明,请参阅我们的官方Scrapeless API文档
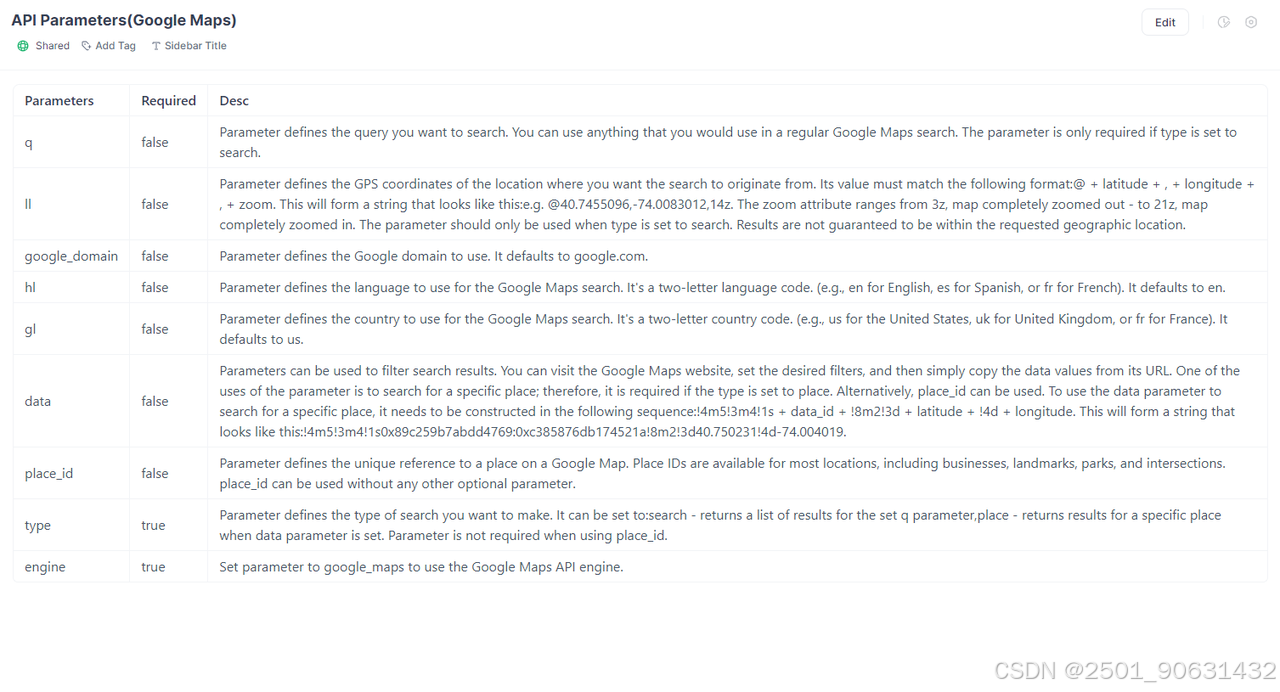
我们可以从这个Scrapeless Google Map API中获得大量数据,例如:
- 标题
- GPS坐标
- 评论摘要
- 平均评分
- 价格
- 类型
- 地址
- 营业时间信息
- 电话
- 网站
- 服务选项
- 等等。
如何分页显示Google Maps上的所有评论?
除了分页显示我们抓取的结果外,Google Maps通常默认每页返回20个结果,第一页的start参数设置为0。如果您想检索第二页的数据,只需将start参数的值增加20即可。
Copy
input_data = {
"engine": "google_maps",
"q": "coffee",
"type": "search",
"ll": "@40.712776,-74.005974.14z",
"start": "20",
}我们建议最多100个(第6页),这与Google Maps网络应用程序的行为相同;超过此限制,结果可能会重复或丢失。
如何将Google Maps结果导出到CSV?
如果您需要Google Maps结果中的数据,您可以添加以下代码。此代码示例向您展示如何将所有local_results存储在CSV中。在此示例中,我们保存了标题、地址、电话和网站。
result = response.json()
local_results = result['local_results']
with open('maps-results.csv', 'w', newline='') as csvfile:
csv_writer = csv.writer(csvfile)
# 写入标题
csv_writer.writerow(["Title", "Address", "Phone Number", "Website"])
# 写入数据
for result in local_results:
csv_writer.writerow(
[result["title"], result["address"], result["phone"], result["website"] if "website" in result else ""])
print('Done writing to CSV file.')如何抓取Google Maps评论
Scrapeless还提供一个评论API,用于获取有关特定位置评论的详细信息。要使用此功能,您需要获取place_id或data_id。
只需修改input_data中的参数,即可获得与您提供的参数相对应的API结果。这种方法使您可以高效地抓取Google Maps评论,利用Scrapeless API的强大功能。
input_data = {
"engine": "google_maps_reviews",
"data_id": "0x89c259af336b3341:0xa4969e07ce3108de",
}**注意:**data_id或place_id参数将在local_results或place_results结果中返回。
结果将包括评论链接、评分、用户详细信息、摘要和点赞数。您可以使用sort_by参数按评分从高到低排序。
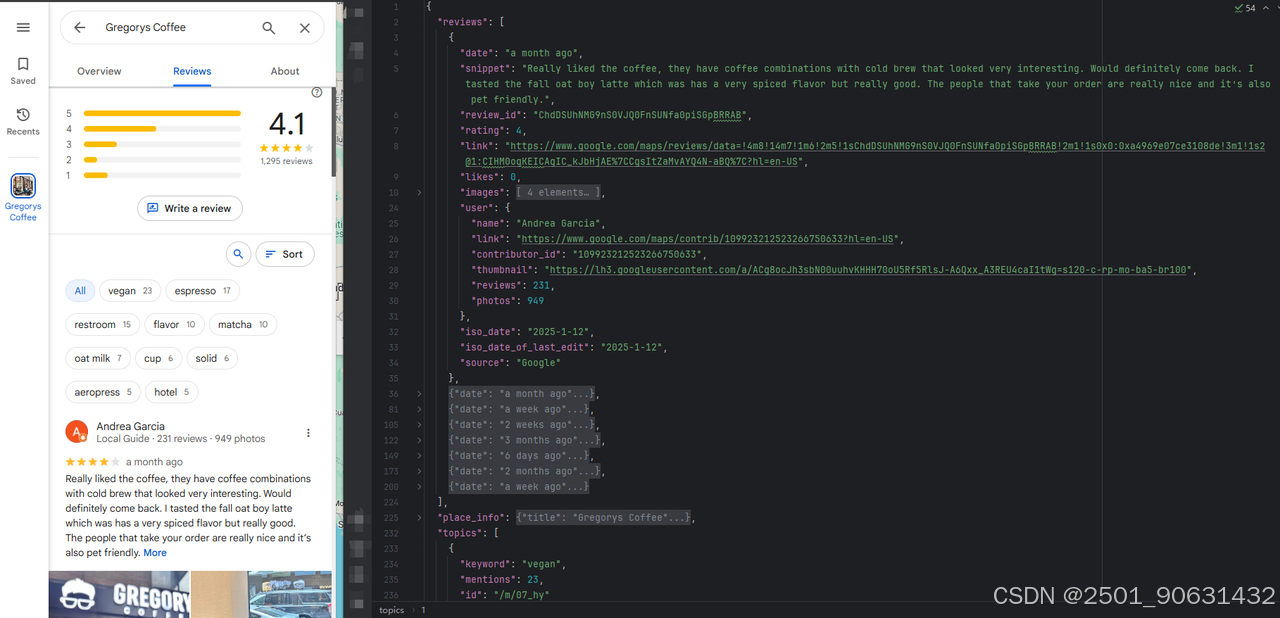
如何分页显示评论
如何分页显示评论API响应中的可用值以获取所有评论数据?请参见下文。
- 获取上述评论API响应中的next_page_token:

- 组装请求参数以启动请求,我们将向您返回评论的下一页:
input_data = {
"engine": "google_maps_reviews",
"data_id": "0x89c259af336b3341:0xa4969e07ce3108de",
"next_page_token": "CAESY0NBRVFDQnBFUTJwRlNVRlNTWEJEWjI5QlVEZGZURUZMUVU5ZlgxOWZSV2hEU21OSVRrMXBiR0Z4ZG1wNWNqRjJhMEZCUVVGQlIyZHVPVEpSWTBOaGQxWm5abmRuV1VGRFNVRQ=="
}Scrapeless还可以为您抓取哪些其他数据
Scrapeless为您提供了多种抓取场景,包括上面显示的本地和位置结果。此外,我们还提供多个API,例如贡献者、路线API、照片API等。对于不同的API,您只需要构建不同的参数:
这里,以爬取路线API为例。您只需要更改上面代码中input_data中的参数即可。结果将包括距离、时间、每次旅程的详细信息等。
Copy
input_data = {
"engine": "google_maps_directions",
"start_addr": "Austin-Bergstrom International Airport",
"end_addr": "5540 N Lamar Blvd, Austin, TX 78756, USA",
}此外,您可以使用travel_mode参数来选择出行方式:
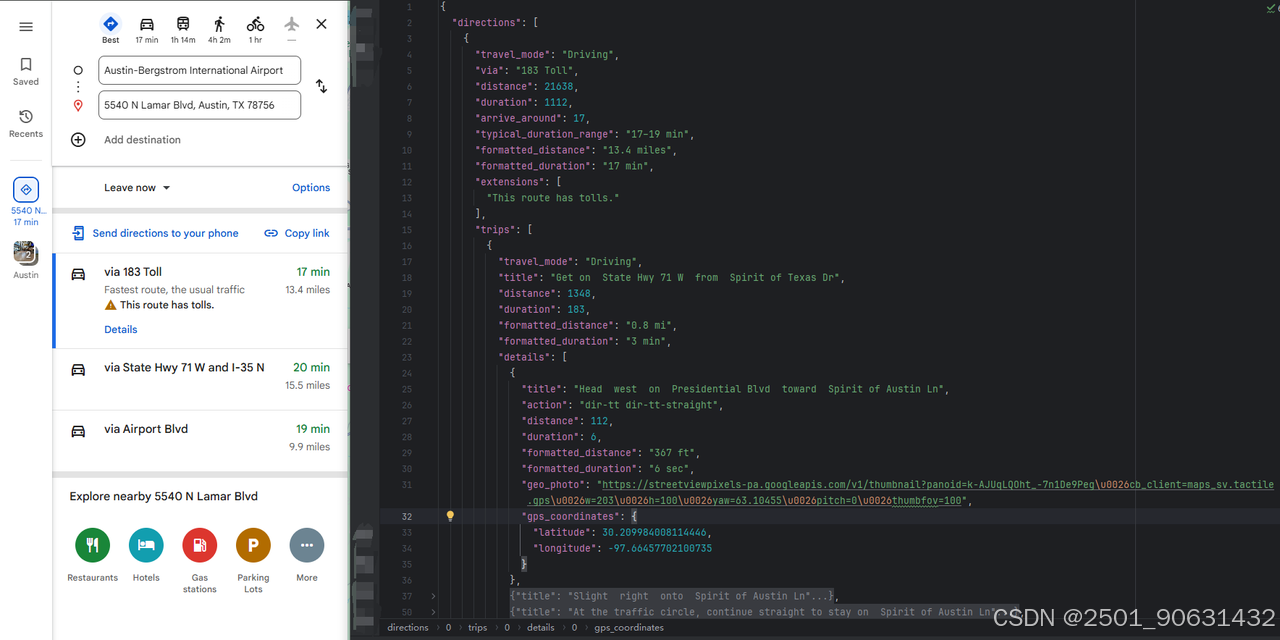
以上是如何抓取Google Maps数据和地点评论的方法。希望对您有所帮助。
结论
抓取Google Maps数据和评论可以成为非常有效的工具。但是,如果没有合适的工具,这可能是一项技术挑战,经常会出现CAPTCHA、IP封锁和复杂的数据提取等问题。
使用Scrapeless,您可以绕过常见的抓取障碍并获取所有类型的信息。
立即注册并获得100,000次免费请求,并通过加入Discord社区获得免费积分。

















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









