






季节变化、需求波动和促销活动导致酒店价格频繁变动。手动追踪这些变化几乎是不可能的。相反,通过抓取旅游网站和平台来自动化此过程可以节省时间和精力。
在本文中,我们将向您展示如何从最大的聚合器之一 Google 抓取酒店价格。通过抓取 Google 的酒店数据,您可以快速收集有关酒店价格、评级和设施的大量信息,用于分析、价格比较或动态定价策略。
为什么抓取 Google 酒店价格?

当您搜索与酒店相关的关键词时,Google 会生成一个专门的酒店部分,其中包含数千家酒店的名称、图片、地址、评级和价格。这是因为 Google 将来自数百万个旅游和酒店网站的信息整合到一个地方。
旅行者、企业和分析师可以将此数据用于各种用途:
- 价格比较:比较不同预订平台和旅游网站的价格,以找到最优惠的价格。
- 数据分析:分析师可以使用酒店价格数据来揭示定价趋势、季节性波动和竞争机会。
- 动态定价策略:企业可以根据需求、可用性和竞争对手价格调整价格,从而优化收入和入住率。
- 自定义提醒:监控价格下降以提醒客户或个人使用。
- 旅行聚合服务:为用户提供来自各种来源的酒店价格和选择的综合视图。
- 预算和规划:旅行者可以预测住宿成本并相应调整他们的计划。
简而言之,此数据的用途非常广泛,但在获得洞察力之前,您需要先收集它。
如何使用 Node.js 抓取 Google 酒店价格
在本教程中,我们将编写一个脚本来收集酒店价格数据并将酒店列表按从低到高的价格排序,重点关注纽约的酒店。
1. 先决条件
要遵循本教程,您需要在计算机上安装以下工具:
- Node.js 18+ 和 NPM
- JavaScript 和 Node.js API 的基本知识
2. 设置项目
创建一个项目文件夹:
Copy
mkdir google-hotel-scraper接下来,通过运行以下命令初始化一个 Node.js 项目:
Copy
cd google-hotel-scraper
npm init -y此命令将在文件夹中创建一个 package.json 文件。创建一个 index.js 文件并添加一个简单的 JavaScript 语句:
Copy
touch index.js
echo "console.log('Hello world!');" > index.js使用 Node.js 运行时运行 index.js 文件:
Copy
node index.js如果终端中打印了“Hello world!”,则您的项目正在运行。
3. 安装必要的依赖项
要构建我们的爬虫,我们需要两个 Node.js 包:
- Puppeteer:加载 Google 酒店页面并下载 HTML 内容。
- Cheerio:从 Puppeteer 下载的 HTML 中提取酒店信息。
使用以下命令安装这些包:
Copy
npm install puppeteer cheerio4. 识别要从 Google 酒店页面抓取的信息
要从网页中提取信息,我们首先需要识别定位所需 HTML 元素的 DOM 选择器。
以下是每个相关数据片段的 DOM 选择器的表格:
| 信息 | DOM 选择器 | 描述 |
|---|---|---|
| 酒店容器 | .uaTTDe | 结果列表中的单个酒店项目 |
| 酒店名称 | .QT7m7 > h2 | 酒店名称 |
| 酒店价格 | .kixHKb > span | 一晚的房价 |
| 酒店星级 | .HlxIlc .UqrZme | 星级数 |
| 酒店评级 | .oz2bpb > span | 酒店的客户评价 |
| 酒店选项 | .HlxIlc .XX3dkb | 提供的其他服务 |
| 酒店图片 | .EyfHd .x7VXS | 酒店图片 |
5. 抓取 Google 酒店页面
确定了 DOM 选择器后,让我们使用 Puppeteer 下载页面的 HTML。我们最初的目标页面是:https://www.google.com/travel/search。
在某些国家/地区(主要在欧洲),在重定向到 URL 之前会显示一个同意页面。我们将添加代码来单击“拒绝全部”按钮,等待三秒钟,并确保 Google 酒店页面已完全加载。
使用以下代码更新 index.js 文件:
Copy
const puppeteer = require('puppeteer');
const PAGE_URL = 'https://www.google.com/travel/search';
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const main = async () => {
const browser = await puppeteer.launch({ headless: 'new' });
const page = await browser.newPage();
await page.goto(PAGE_URL);
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe[aria-label="Reject all"]');
await buttonConsentReject?.click();
await waitFor(3000);
const html = await page.content();
await browser.close();
console.log(html);
}
void main();使用 node index.js 运行代码。终端将输出页面的 HTML 内容。
6. 从 HTML 中提取信息
虽然我们有页面的 HTML,但直接从原始 HTML 中提取有价值的数据具有挑战性。这就是 Cheerio 的用武之地。
以下代码加载 HTML 并提取每家酒店的房价:
Copy
const cheerio = require("cheerio");
const $ = cheerio.load(html);
$('.uaTTDe').each((i, el) => {
const priceElement = $(el).find('.kixHKb span').first();
console.log(priceElement.text());
});更新 index.js 文件以使用 Cheerio 提取内容,将其存储在数组中,并按从低到高的价格对其进行排序:
const cheerio = require("cheerio");
const puppeteer = require("puppeteer");
const { sanitize } = require("./utils");
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const GOOGLE_HOTEL_PRICE = 'https://www.google.com/travel/search';
const main = async () => {
const browser = await puppeteer.launch({ headless: 'new' });
const page = await browser.newPage();
await page.goto(GOOGLE_HOTEL_PRICE);
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe[aria-label="Reject all"]');
await buttonConsentReject?.click();
await waitFor(3000);
const html = await page.content();
await browser.close();
const hotelsList = [];
const $ = cheerio.load(html);
$('.uaTTDe').each((i, el) => {
const titleElement = $(el).find('.QT7m7 > h2');
const priceElement = $(el).find('.kixHKb span').first();
const reviewsElement = $(el).find('.oz2bpb > span');
const hotelStandingElement = $(el).find('.HlxIlc .UqrZme');
const options = [];
const pictureURLs = [];
$(el).find('.HlxIlc .XX3dkb').each((i, element) => {
options.push($(element).find('span').last().text());
});
$(el).find('.EyfHd .x7VXS').each((i, element) => {
pictureURLs.push($(element).attr('src'));
});
const hotelInfo = sanitize({
title: titleElement.text(),
price: priceElement.text(),
standing: hotelStandingElement.text(),
averageReview: reviewsElement.eq(0).text(),
reviewsCount: reviewsElement.eq(1).text(),
options,
pictures: pictureURLs,
});
hotelsList.push(hotelInfo);
});
const sortedHotelsList = hotelsList.slice().sort((hotelOne, hotelTwo) => {
if (!hotelTwo.price) {
return 1;
}
return hotelOne.price - hotelTwo.price;
});
console.log(sortedHotelsList);
}
void main();运行代码并查看结果。您刚刚收集了所有酒店的信息。
在之前的內容中,我們通過 Node.js 和 Puppeteer 實現了 Google 酒店價格的爬取。雖然這種方法可以滿足基本需求,但在處理複雜的反爬蟲機制時需要編寫大量的代碼,並且可能會遇到許多挑戰。
為了更有效地完成任務,我們可以推薦一種更簡單的方法:使用 Scrapeless Deep SerpAPI。
使用 Scrapeless Deep SerpApi 爬取 Google 酒店信息
Deep SerpApi 是一款專為大型語言模型 (LLM) 和 AI 代理設計的專用搜索引擎,旨在提供實時、準確和無偏見的信息,以幫助 AI 應用程序高效地檢索和處理數據。
它可以幫助開發者快速獲取 Google 搜索引擎超過 20 種不同場景的結果。它支持多個參數設置,可以根據地區、語言和設備類型自定義搜索,並為開發者提供可以直接使用的結構化 JSON 数据。

Deep SerpAPI 的優勢
-
**最低價格:**Deep SerpAPI 的價格低至 $0.1/k。它是市場上最低的價格。
-
**易於使用:**無需編寫複雜的代碼,只需通過 API 調用即可獲取數據。
-
**實時:**每個請求都可以即時返回最新的搜索結果,確保數據的及時性。
-
**全球支持:**通過全球 IP 地址和瀏覽器集群,確保搜索結果與真實用户的體驗一致。
-
**豐富的數據類型:**支持 超過 20 種 搜索類型,例如 Google 搜索、Google 地圖、Google 購物等。
-
**高成功率:**提供高達 99.995% 的服務可用性 (SLA)。
如何使用 Deep SerpAPI playground 抓取 Google 酒店信息
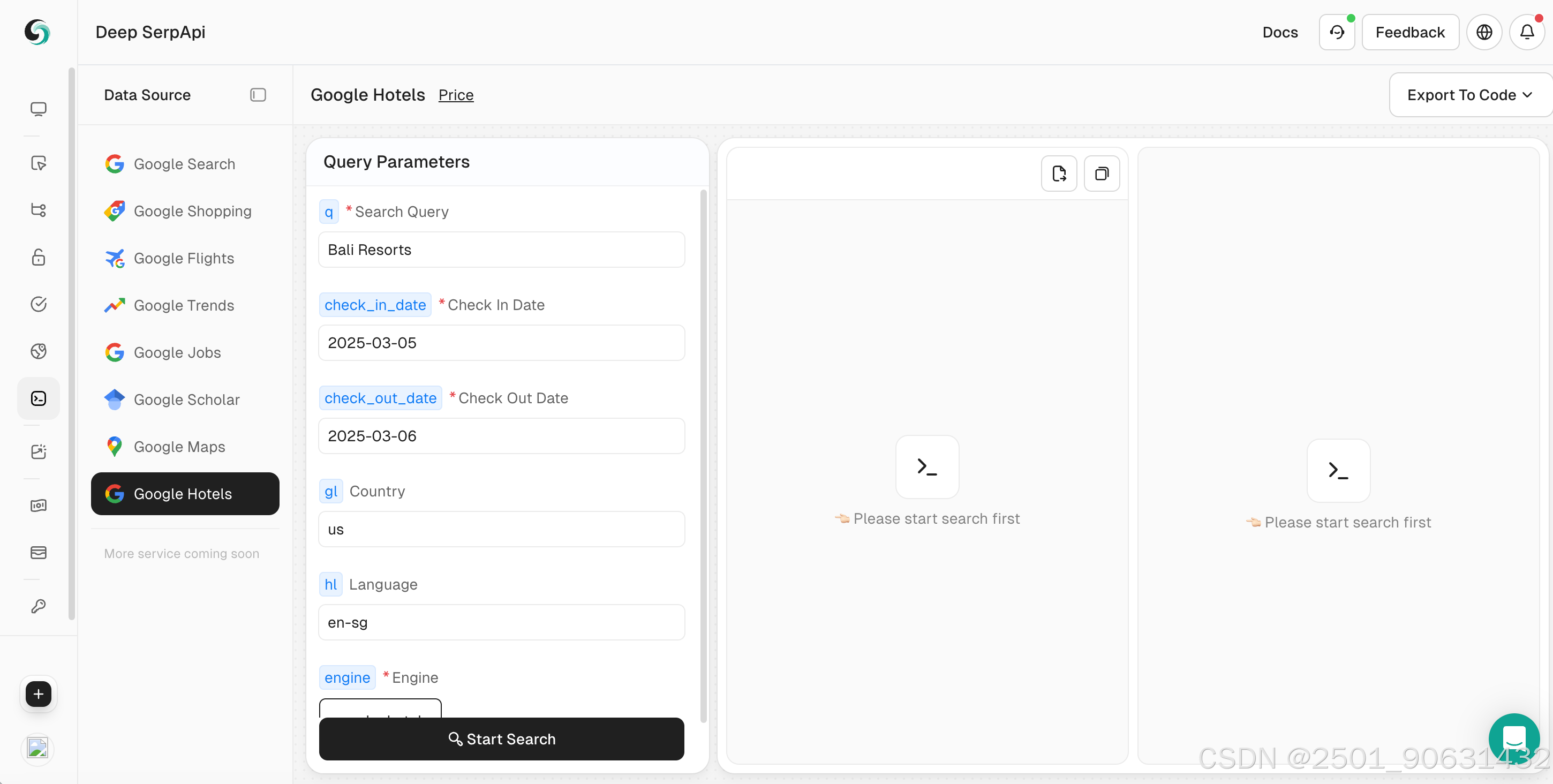
Deep SerpAPI 提供了一個強大的線上工具 Playground,允許開發者無需編寫代碼即可快速抓取 Google 酒店信息。Playground 是一個可視化界面,可以通過簡單的參數設置和點擊操作獲取結構化的搜索結果數據。以下是使用 Deep SerpAPI Playground 抓取 Google 酒店信息的詳細步驟。
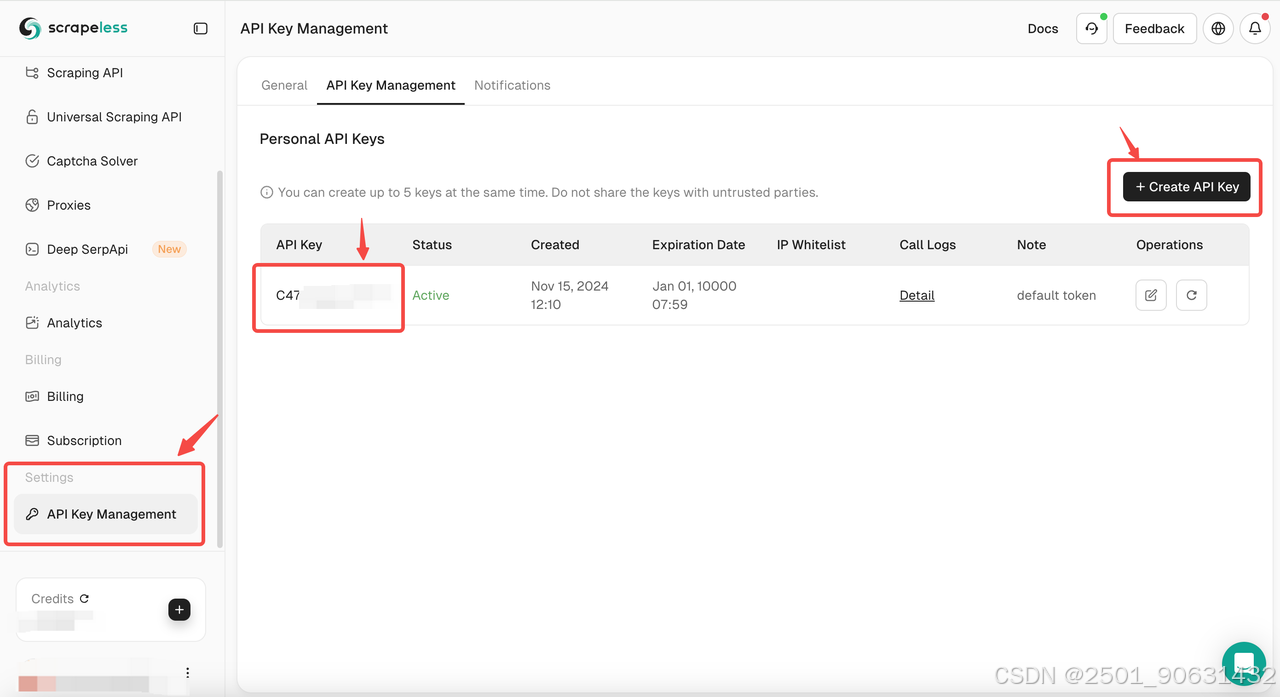
如何獲取 Deep SerpAPI 的 API KEY:
- 在 Scrapeless 上免費註冊 後,您將獲得 20,000 次免費搜索查詢。
- 前往 API 密鑰管理。然後點擊 創建 以生成唯一的 API 密鑰。創建後,只需點擊 AP 即可複製它。
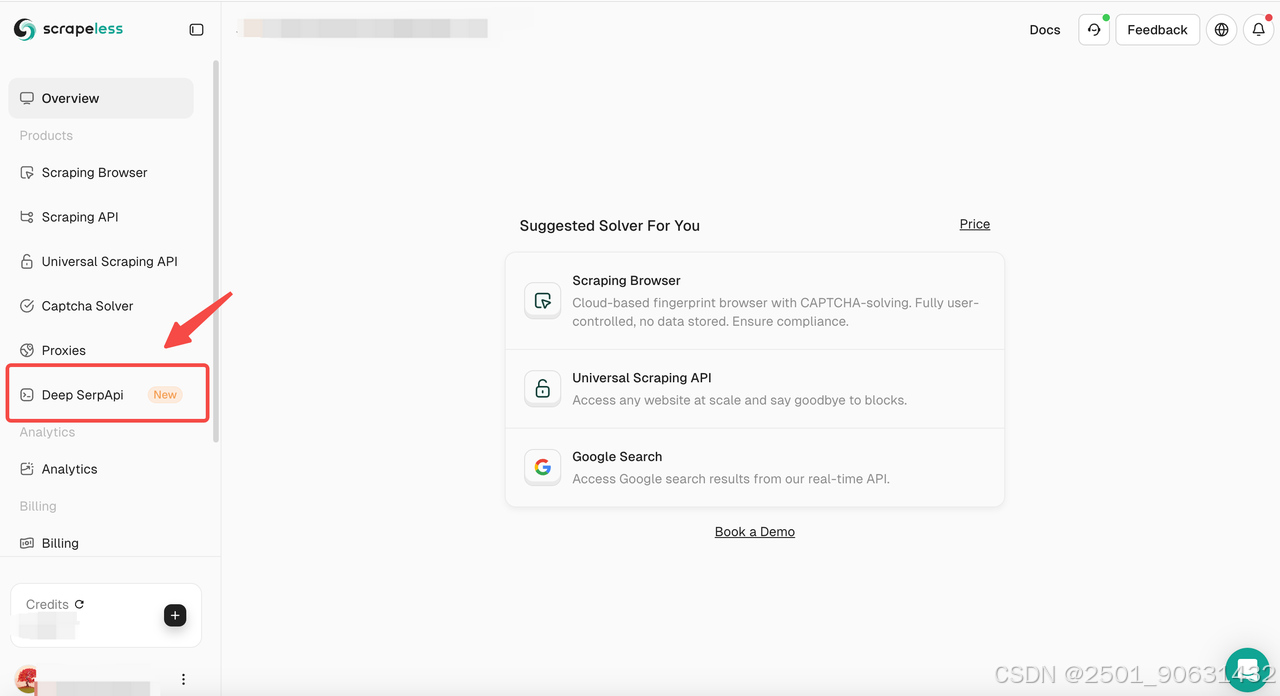
1. 註冊並訪問 Playground
- 創建帳戶:如果您還沒有,請註冊 Deep SerpAPI 帳戶。
- 訪問 Deep SerpApi Playground:登錄後,導航到“Deep SerpApi”部分。
2. 設置搜索參數
- 在 Playground 中,輸入您的搜索關鍵字,例如“紐約酒店”。
- 設置其他參數,例如入住日期、退房日期、國家/地區、語言等。
您也可以點擊查看 官方 API 文檔 了解 Scrapeless 的 Google 酒店參數。
3. 執行搜索
- 點擊“開始搜索”按鈕,Playground 將向 Deep Serp API 發送請求並返回結構化的 JSON 數據。
- 返回的數據將包括酒店名稱、品牌詳情、價格信息、描述、評級、設施、附近位置、酒店評級等。
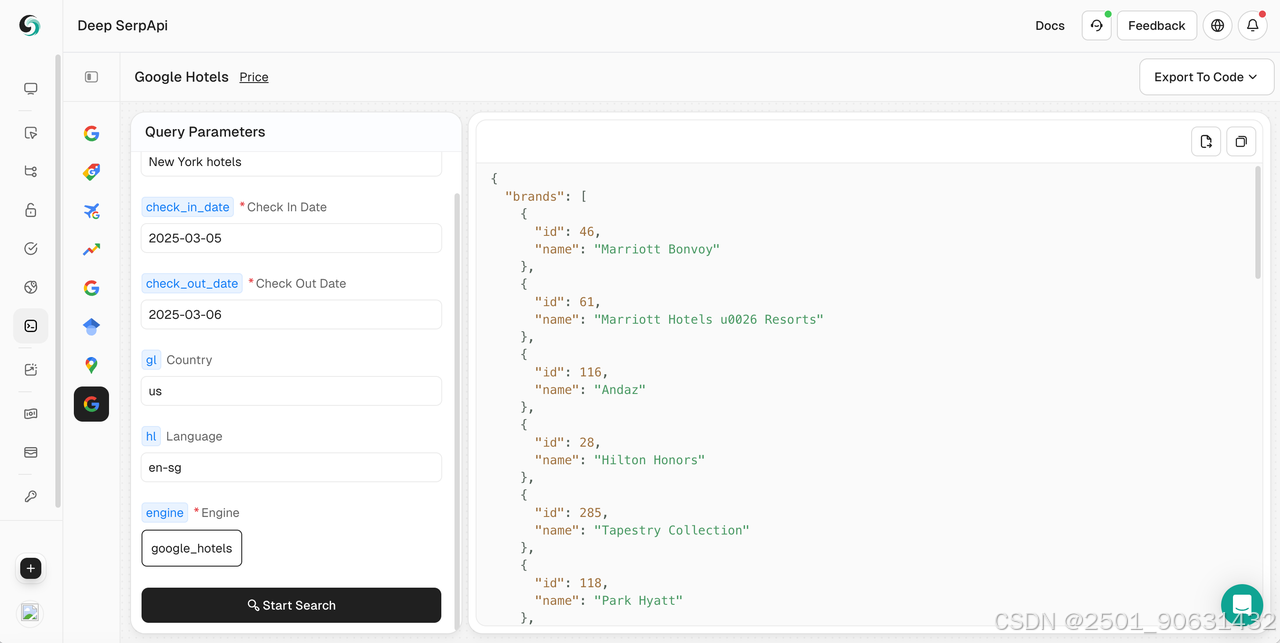
4. 查看和導出數據
- 瀏覽返回的 JSON 數據以查看每家酒店的詳細信息。
- 如有必要,您可以點擊右上角的“導出”將數據導出到 CSV 或 JSON 格式,以便進一步分析。
5. 集成到您的項目中
- 如果您需要將數據集成到您的應用程序中,Deep SerpAPI 提供了多種編程語言的庫支持,包括 Python、JavaScript、Ruby、PHP、Java、C#、C++、Swift、Go 和 Rust。
示例代碼 (Python)
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_hotel",
q: query,
engine: 'google',
gl: 'us',
hl: 'en'
}
payload = Payload("scraper.google.hotel", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Deep SerpAPI 定價計劃:經濟實惠且功能強大
Deep SerpAPI 提供了一個經濟高效的解決方案,幫助開發者快速獲取 Google 搜索結果頁面 (SERP) 數據。它的定價計劃非常具有競爭力,價格低至 每 1,000 次查詢 $0.1,適用於 Google 的 20 多種搜索結果場景。
免費開發者支持計劃
Deep SerpAPI 現在還提供免費的開發者支持計劃,幫助開發者更好地集成和使用其 API。以下是該計劃的詳細信息:
- **集成支持:**將 Deep SerpAPI 集成到您的 AI 工具、應用程序或項目中。我們已經支持 Dify,並且很快將支持 Langchain、Langflow、FlowiseAI 和其他框架。
- **免費支持時長:**集成後,開發者可以通過在 GitHub 或社交媒體上分享您的成果獲得 1-12 個月的免費開發者支持。
- **使用配額:**每月高達 500k 次使用,幫助開發者在項目的早期階段不用擔心成本問題。

您可以加入 Discord 聯繫 Liam 了解活動參與方式
結論
總之,使用 Node.js 抓取 Google 酒店價格對於收集價格數據來說是一種有價值的方法,但它也存在一些挑戰,例如處理動態內容和避免被檢測。雖然 Puppeteer 或 Playwright 等工具可以提供幫助,但它們需要持續的維護和技術專業知識。為了簡化這個過程,我們推薦使用 Scrapeless,它提供了一個無需編碼的輕鬆解決方案,可以高效且可靠地提取酒店價格數據。使用 Scrapeless,您可以專注於洞察力,而不是網頁抓取的複雜性。立即嘗試並簡化您的數據收集!
附加資源
如何使用 Python 抓取 Google 新聞
如何將 Selenium 與 PowerShell 一起使用
使用 Scrapeless 從 Google 購物抓取產品詳情


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









