






数据集说明
CIFAR-10数据集由10个类的60000个32x32彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像。数据集分为5个训练批次和1个测试批次,每个批次有10000个图像。测试批次包含来自每个类别的恰好1000个随机选择的图像。训练批次以随机顺序选取剩余图像,但一些训练批次可能更多会选取来自一个类别的图像。总体来说,五个训练集之和包含来自每个类的正好5000张图像。图6-27 显示了数据集中涉及的10个类,以及来自每个类的10个随机图像。

加载数据
这里采用FyTarch提供的数据集加载工具torchvision,同时对数据进行预处理。为方便起见,我们已预先下载好数据并解压,存放在当前目录的data目录下,所以,参数download=False。
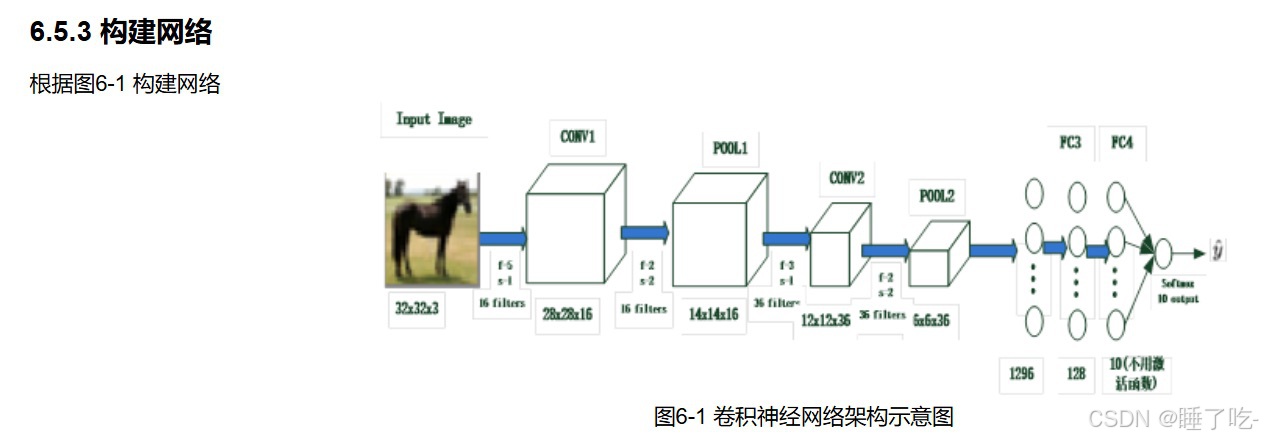
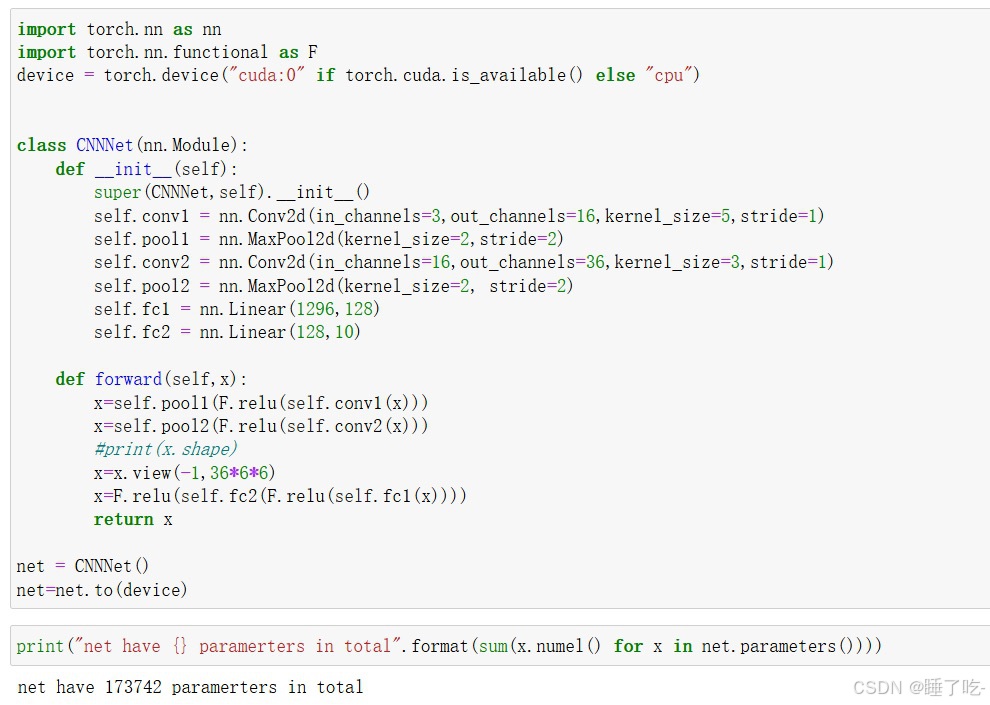
构建网络


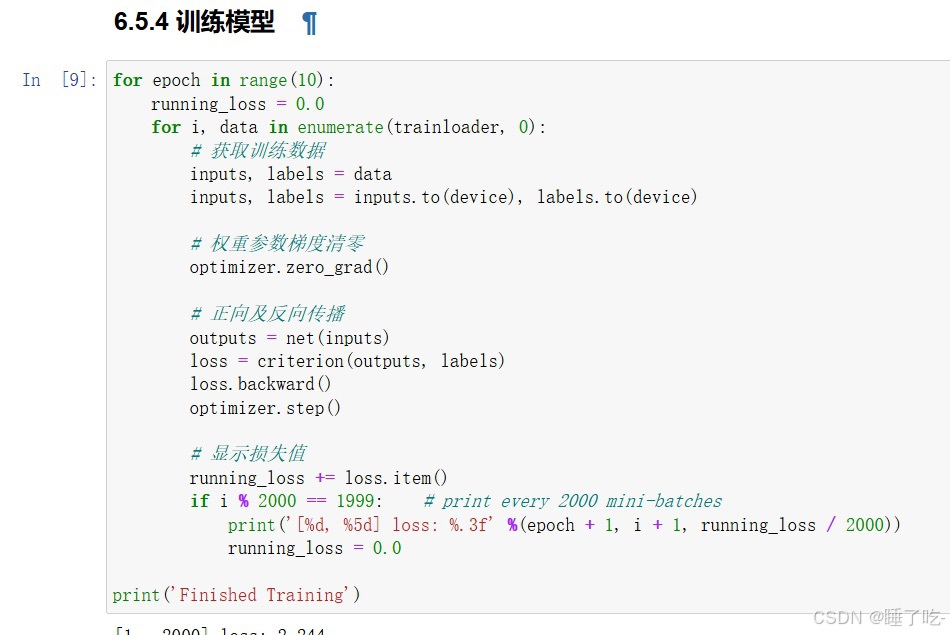
训练模型

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









