






【导读】
时间序列分析作为机器学习领域的关键部分,在众多实际场景中发挥着重要作用,从天气预报到金融市场预测,从医疗健康监测到工业生产优化,其应用广泛且意义重大。近年来,这一领域研究成果丰硕,在模型改进、跨领域应用和工具开发等方面均取得显著进展。
对于渴望在时间序列领域发表论文的同学而言,深入学习前沿研究成果十分必要。本文精心盘点了时间序列领域的最新顶会论文,并且所有论文代码均可复现,方便研究者深入探究。
希望这些介绍能为同学们带来启发,助力大家在时间序列领域的研究与论文创作,推动该领域的进一步发展。
点击【AI十八式】的主页,获取更多优质资源!
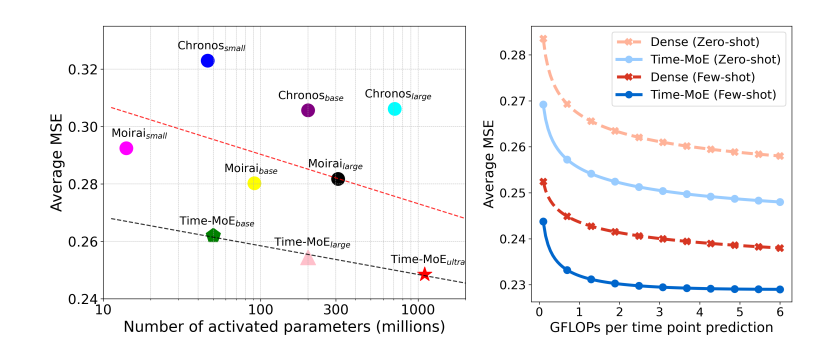
MOE Performance overview
【论文1:Transformer方向】
SAMformer: Unlocking the Potential of Transformers in Time Series Forecasting with Sharpness-Aware Minimization and Channel-Wise Attention
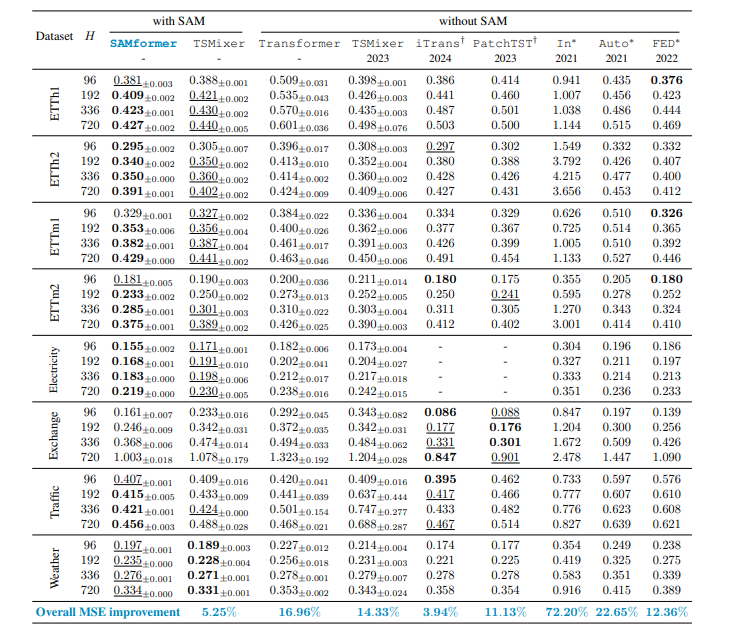
Performance comparison between our model (SAMformer) and baselines for multivariate long-term forecasting with different horizons H
1.研究方法

Architecture of the network used in SAMformer and Transformer
论文提出 SAMformer 模型用于时间序列预测。先通过研究简单线性预测问题,发现 transformer 存在的问题,在此基础上构建一个浅而轻量的 transformer 模型,并采用锐度感知最小化(SAM)进行优化,同时融入可逆实例归一化(RevIN)和通道注意力机制,以提升模型性能。
2.论文创新点
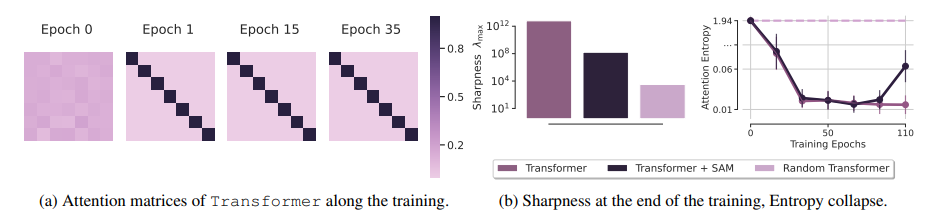
Transformer’s loss landscape analysis for linear regression
-
优化训练策略:针对transformer在时间序列预测中训练不稳定、易陷入局部最优的问题,采用锐度感知最小化(SAM)方法优化模型训练,使模型收敛到更平坦的局部最小值,提升泛化能力,解决了传统transformer训练中的难题。
-
独特模型设计:提出的SAMformer模型结合了可逆实例归一化(RevIN)和通道注意力机制。RevIN能减少训练和测试数据分布差异,通道注意力机制确保特征排列不变性,降低时间和内存复杂度,在提高模型性能的同时增强了模型的可解释性。
-
性能优势显著:在多个公开的多元时间序列数据集上进行实验,SAMformer在预测准确性上超越了当前的先进方法,与大型基础模型MOIRAI表现相当,但参数数量显著更少。同时,该模型对随机初始化具有鲁棒性,计算效率高,且对预测 horizon 具有良好的适应性。
论文链接:https://arxiv.org/abs/2402.10198
【论文2图神经网络方向】
Biased Temporal Convolution Graph Network for Time Series Forecasting with Missing Values
1.研究方法
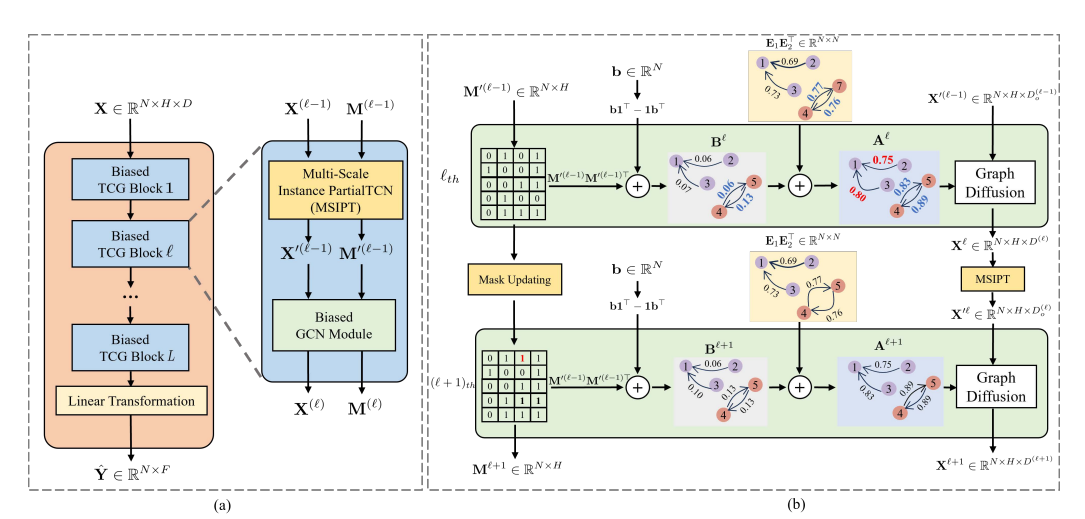
(a) The framework of our proposed BiTGraph, and (b) the illustration of the Biased GCN module.
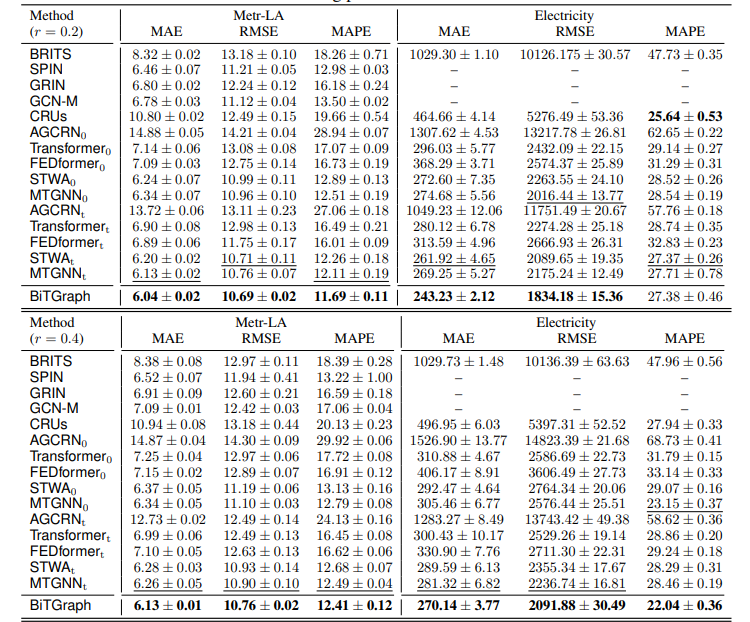
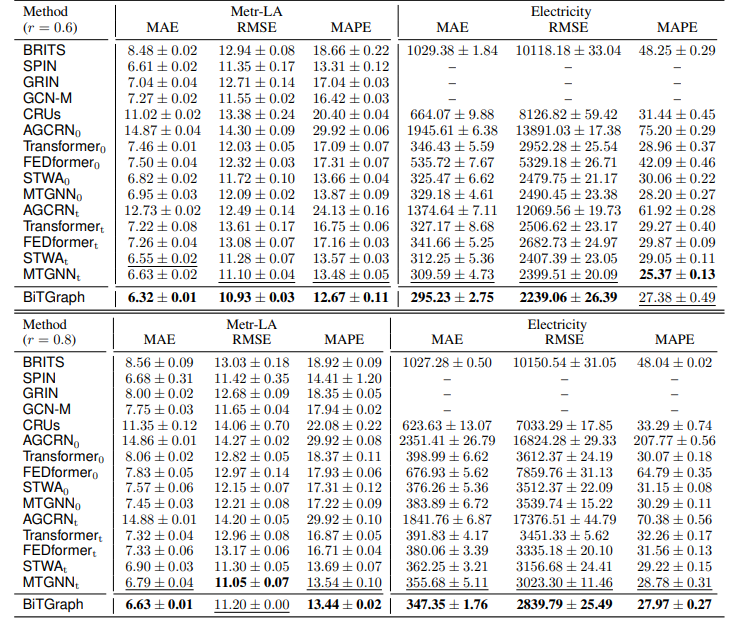
论文提出 Biased Temporal Convolution Graph Network(BiTGraph)用于含缺失值的时间序列预测。模型由多个 Biased TCGBlock 堆叠构成,每个 Block 包含 Multi-Scale Instance PartialTCN 和 Biased GCN 模块。前者对每个时间序列进行多尺度局部时间卷积,捕捉被缺失值破坏的时间依赖关系;后者通过构建有偏图探索空间结构,两个模块协同工作,逐步更新缺失模式以提升预测性能。
2.论文创新点
-
考虑缺失模式:在模型设计中明确考虑缺失值,通过在两个核心模块中注入偏差来处理不同的缺失模式,打破了传统方法中预测与插补分离的局限,减少误差积累,提升模型在缺失值场景下的预测能力。
-
独特模块设计:Multi-Scale Instance PartialTCN模块将时间依赖建模与空间关联建模解耦,采用多尺度策略有效处理不同时间尺度的缺失模式;Biased GCN模块通过构建有偏图,在图结构学习中融入缺失值信息,更好地传播节点间信息,增强对空间结构的捕捉。
-
性能优势显著:在五个真实世界基准数据集上,BiTGraph在不同缺失率场景下相比现有方法有显著提升,最高可达9.93%。消融实验验证了其模块的有效性,且模型复杂度较低,在内存使用和参数数量上表现出色。
论文链接:https://openreview.net/forum?id=O9nZCwdGcG
【论文3基础模型方向】
MOMENT: A Family of Open Time-series Foundation Models
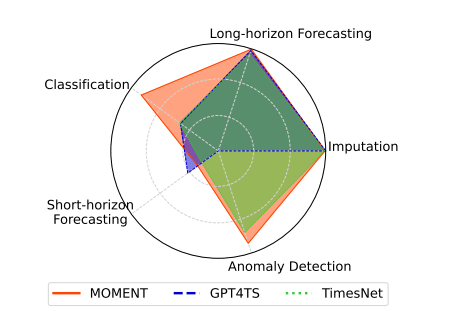
. MOMENT can solve multiple time series analysis tasks well (App. F).
1.研究方法
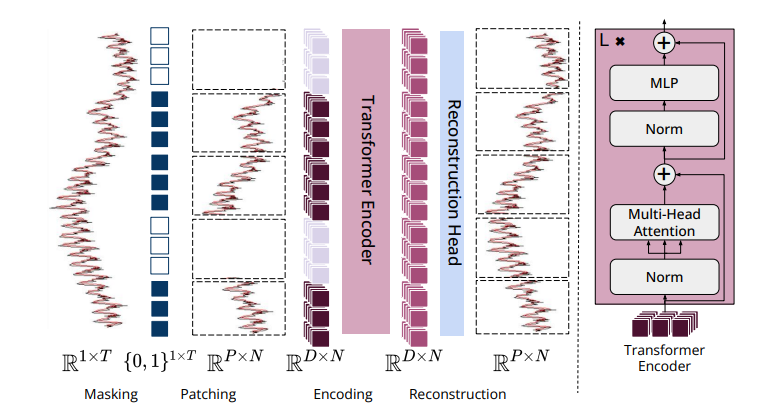
Overview of MOMENT
论文提出的MOMENT首先收集大量公共时间序列数据构建 Time Series Pile 数据集,解决预训练数据不足的问题。然后基于 Transformer 架构,采用掩码时间序列预测任务对 MOMENT 模型进行预训练,通过特殊的嵌入和架构设计处理时间序列特性。最后,将预训练模型在多个下游任务中进行微调,如长短期预测、分类、异常检测和插补等,以适应不同的时间序列分析需求。
2.论文创新点
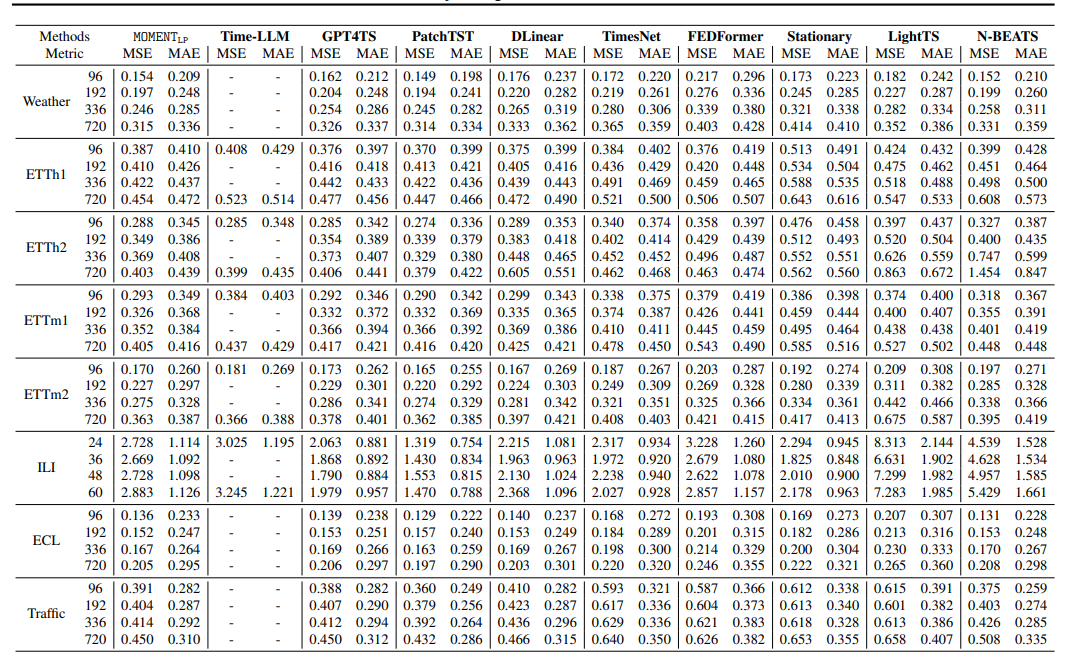
Long-term forecasting performance measured using Mean Squared Error (MSE) and Mean Absolute Error (MAE).
-
构建大规模数据集:创建Time Series Pile,包含来自多个领域的大量时间序列数据,为模型预训练提供丰富数据,解决了时间序列领域缺乏大规模统一数据集的问题,推动多数据集预训练的发展。
-
设计通用基础模型:提出MOMENT系列开源基础模型,以Transformer为架构,通过掩码时间序列预测任务预训练,具备处理多种时间序列分析任务的能力,在零样本或少量样本场景下表现良好,且可通过微调提升性能。
-
拓展评估基准:在已有工作基础上从多维度扩展实验基准,涵盖多种时间序列任务、更多数据集和评估指标,并专注于有限监督场景,更全面准确地评估模型性能,为时间序列基础模型的评估提供了更完善的标准。
-
探索模型特性:对MOMENT模型进行深入研究,发现其能捕捉时间序列的多种特征,模型规模扩大有助于提升性能,且在跨模态序列学习任务中表现良好,还发现随机初始化权重可使模型达到更低训练损失。
论文链接:https://arxiv.org/pdf/2402.03885
【论文4因果发现方向】
CUTS+: High-dimensional Causal Discovery from Irregular Time-series
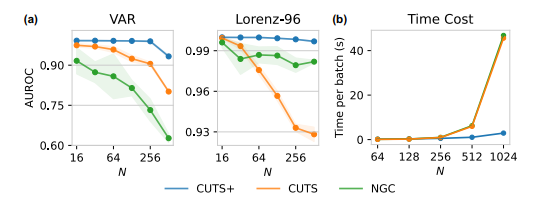
Experiments on scalability of the models.
1.研究方法
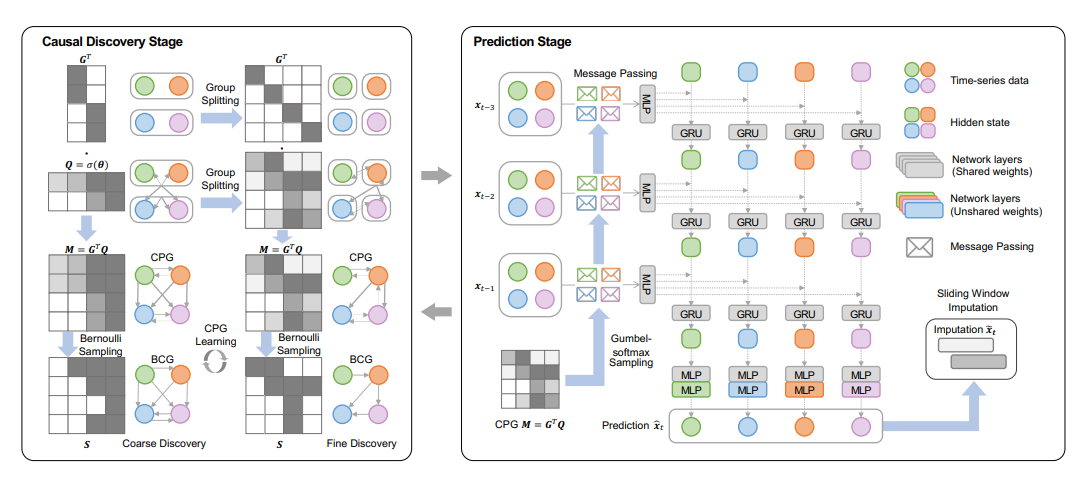
The architecture of CUTS+ with two alternating stages, both boosted for high-dimensional causal discovery.
论文提出CUTS+ 基于 Granger 因果关系,采用两阶段训练策略。在因果发现阶段,运用粗到细发现(C2FD)技术,将时间序列分组以降低初始阶段需学习的参数数量,随着训练推进逐步细化分组优化因果图;在预测阶段,利用基于消息传递的图神经网络(MPGNN)对数据进行预测和缺失值插补,以减少网络参数冗余,提升模型在高维时间序列数据上的处理能力。
2.论文创新点
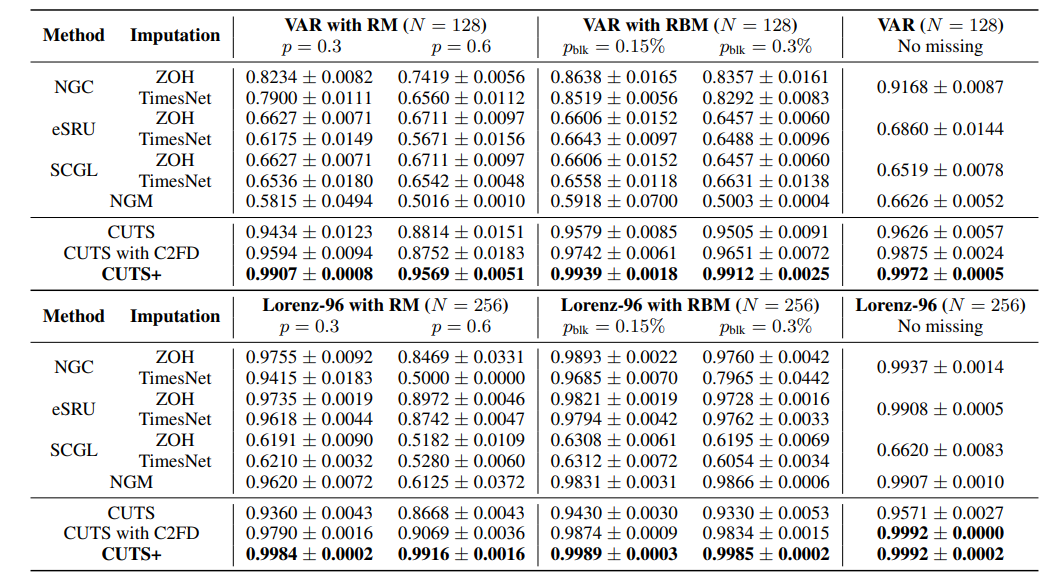
Performance comparison of CUTS+ with NGC, eSRU, NGM, SCGL, and CUTS combined with ZOH and TimesNet for imputation.
-
提出C2FD技术:创新地引入粗到细发现(C2FD)技术,先对时间序列进行粗分组,大幅减少初始阶段优化的参数数量,再逐步细分,利用前期学习结果作为后续优化的初始猜测,有效解决高维数据下因果图过大难以学习的问题,提升因果发现效率和准确性。
-
设计MPGNN:设计基于消息传递的图神经网络(MPGNN),通过在门控循环单元(GRUs)中添加消息传递层,减少参数数量,避免使用高度冗余的组件式神经网络,降低过拟合风险,提高模型在高维时间序列数据上的可扩展性。
-
提升综合性能:相比之前的方法,CUTS+在模拟、准真实和真实数据集上均显著提高了因果发现性能,尤其是在处理高维数据和不同类型的不规则采样数据时,同时降低了时间成本,在高维时间序列因果发现任务上展现出明显优势。
论文链接:https://arxiv.org/abs/2305.05890


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









