






目前,小波变换已成为多领域数据处理与分析的关键技术方向。通过将小波变换应用于大语言模型训练以及构建新型小波变换体系等不同场景,能够有效挖掘数据中的深层特征与规律。
最新研究显示,梯度小波变换(GWT)能够降低大语言模型训练内存需求,突破传统方法的局限,充分利用小波变换在多尺度分析、特征提取与降噪等方面的优势,极大提升在复杂任务和不同数据类型下的处理能力。
我整理了10篇关于【小波变换】的相关论文,感兴趣的欢迎di~
突破内存限制:梯度小波变换助力大语言模型训练
文章解析:
文章针对大语言模型训练内存瓶颈问题,提出梯度小波变换(GWT)方法。通过对梯度进行小波变换降低优化器状态内存需求,将其与多种优化器结合,在预训练和微调任务实验中,证明该方法能减少内存使用、提升训练性能。
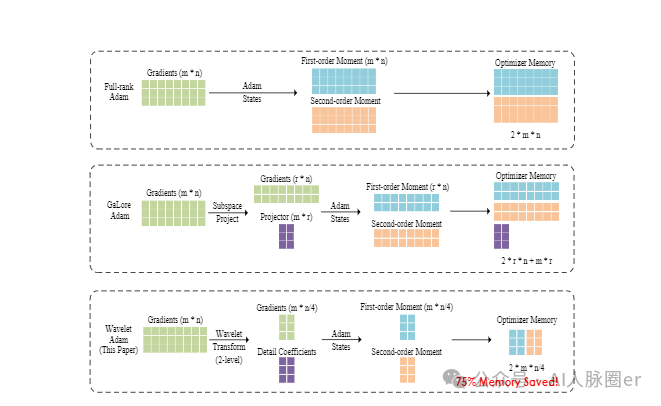
创新点:
1.首次将小波变换应用于大语言模型训练的梯度处理,有效降低优化器状态内存占用,突破传统低秩训练方法的局限。
2.设计通用框架,使GWT可与多种内存密集型优化器无缝集成,如Adam、Adafactor等,适用性广泛。
3.实验证明GWT在预训练和微调任务中性能优异,在减少内存使用的同时,训练速度和效果优于或与全秩方法相当。
研究方法:
1.理论上,将离散Haar小波变换应用于梯度,构建GWT与优化器结合的更新规则,形成统一框架。
2.在C4数据集上预训练LLaMA模型、GLUE基准上微调RoBERTa-base模型,对比GWT与其他方法的内存使用、训练速度和模型性能。
3.采用特定网络架构和超参数设置,使用BF-16格式减少内存,在多GPU环境下用PyTorch进行实验,保证可重复性。
研究结论:
1.GWT能显著减少优化器内存使用,在LLaMA 1B预训练中,相比全秩方法,优化器内存成本最多降低67% 。
2.该方法在不同任务和模型中表现出色,预训练LLaMA模型时收敛更快,微调RoBERTa-base模型也有竞争力。
3.GWT为大语言模型内存高效训练提供新方向,未来可在理论基础、小波变换优化及其他领域应用等方面进一步探索。
WaveNet-SF:一种基于空间 - 频域小波变换的视网膜疾病检测混合网络
文章解析:
文章提出WaveNet-SF框架用于视网膜疾病检测,利用小波变换分解OCT图像,通过多尺度小波空间注意力模块和高频特征补偿块提升检测效果。在多个数据集上实验,证明该框架性能卓越,能有效应对OCT图像分析的挑战。
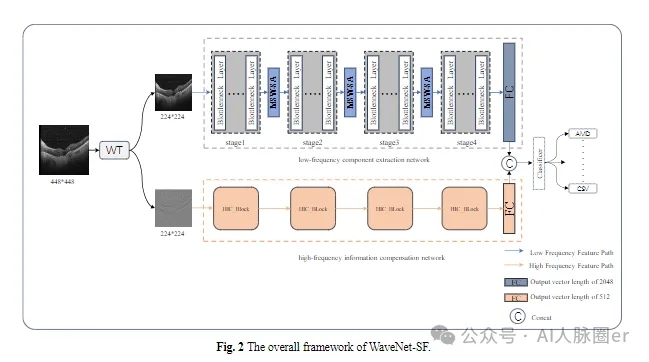
创新点:
1.设计双分支网络架构,分别从OCT图像的低频和高频分量中提取特征,融合空间和频域信息提升分类性能。
2.开发多尺度小波空间注意力模块,利用多尺度感受野更好地捕捉图像空间信息,聚焦病变区域。
3.引入高频特征补偿块,提取边缘信息,增强模型对细微病变的分类能力,提升在噪声环境下的性能。
研究方法:
1.构建包含小波变换块、低频特征提取网络和高频特征补偿网络的整体架构,对OCT图像进行特征提取和分类。
2.使用OCT-C8和OCT2017数据集,以准确率、精确率等为评估指标,对比其他先进模型验证性能。
3.进行消融实验,分析各组件对模型性能的影响,还通过引入噪声评估模型的鲁棒性。
研究结论:
1.WaveNet-SF在OCT-C8和OCT2017数据集上分别取得97.82%和99.58%的准确率,超越现有方法。
2.消融实验表明各组件有效,多尺度小波空间注意力模块和高频特征补偿块能提升模型性能和鲁棒性。
3.该框架为眼科医生的诊断任务提供了有力支持,在视网膜疾病检测领域具有重要应用价值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









