







仅供学习参考
以美剧天堂为例,链接:https://www.mjtta.cc/p/822380/263/0
F12打开开发者工具,进度条拖至尾部,可以看到
ts文件最小为0000000,链接为:https://p.bvvvvvvv7f.com/video/youshuo/HD/0000000.ts
ts文件最大为0003169,链接为:https://p.bvvvvvvv7f.com/video/youshuo/HD/0003169.ts
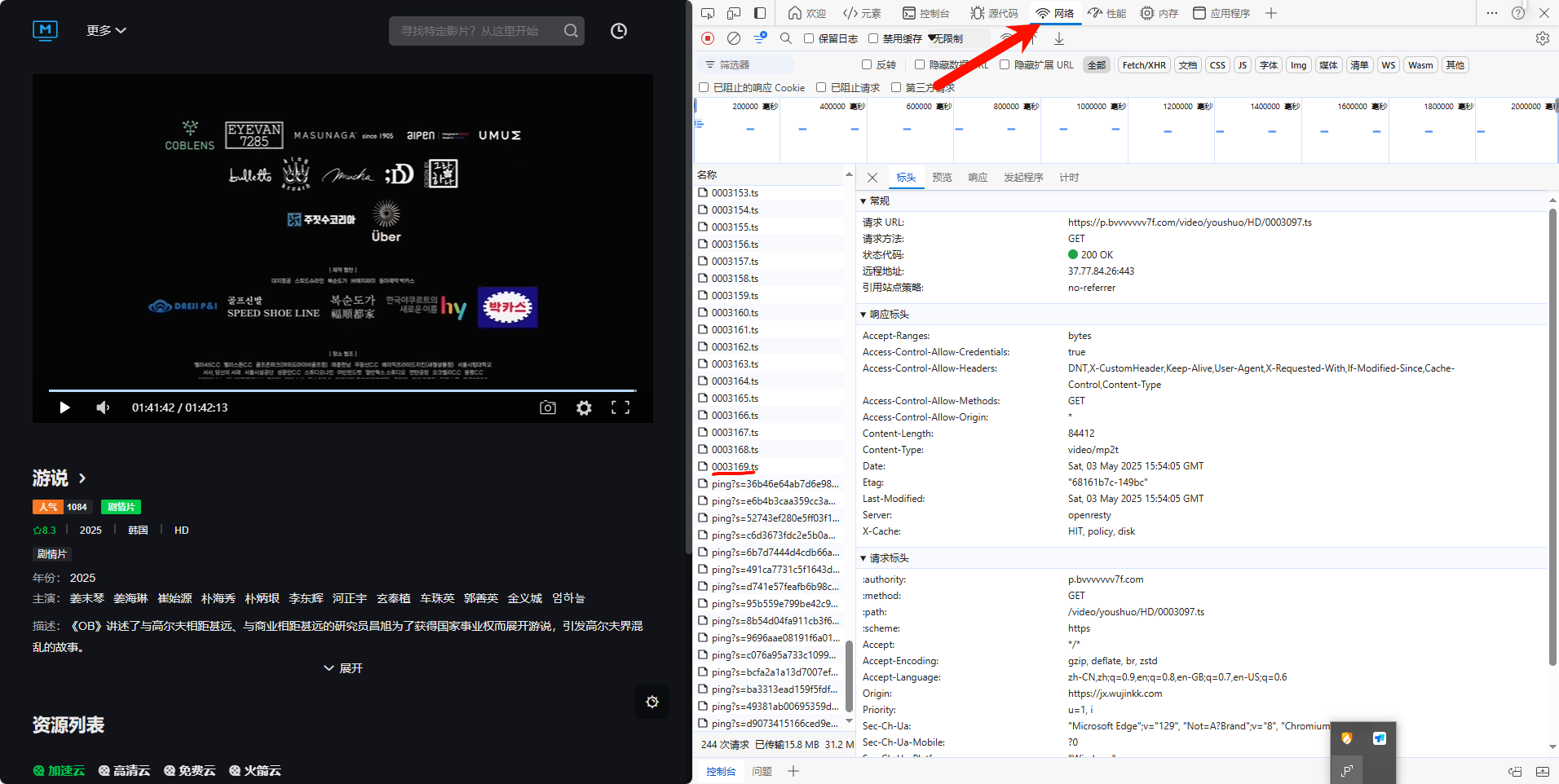
所以我们只需构建一个循环,依次requests请求下载文件即可
import requests
header = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0",
"accept-language":"zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6"
}
for i in range(0,3169):
cid = str(i).zfill(7)
url = f'https://p.bvvvvvvv7f.com/video/youshuo/HD/{cid}.ts'
resp = requests.get(url,headers=header)
f = open(f"游说/video{cid}.ts",mode="wb")
f.write(resp.content)
f.close()
resp.close()
print(url,"over")
print('over')考虑到下载内容较多,可以用异步协程处理
import asyncio
import aiohttp
import aiofiles
import os
header = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0",
"accept-language":"zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6"
}
async def down(cid):
down_url = f'https://p.bvvvvvvv7f.com/video/youshuo/HD/{cid}.ts'
async with aiohttp.ClientSession() as Session:
async with Session.get(down_url,headers = header) as down_resp:
async with aiofiles.open(f"游说/video{cid}.ts",mode="wb") as f:
content = await down_resp.read() # 读取全部字节数据
await f.write(content)
print(down_url,',over')
#检验文件是否已存在,对未下载文件,进行下载处理
async def file():
tasks = []
for i in range(3169):
cid = str(i).zfill(7)
file_path = f"游说/video{cid}.ts"
if not os.path.isfile(file_path):
tasks.append(asyncio.create_task(down(cid)))
print(f"缺少文件: {file_path},已加入下载队伍")
if len(tasks) != 0:
await asyncio.wait(tasks)
else:
print('已全部下载')
if __name__ == '__main__':
asyncio.run(file())如遇到反爬机制,可分段下载,如0-1000,1000-2000等
运行结果:
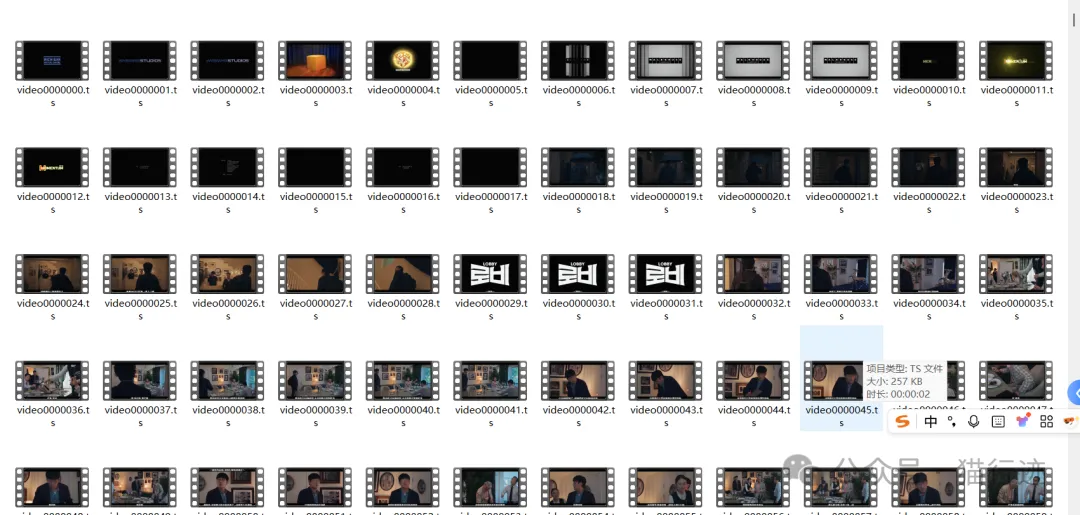
将ts文件合并为mp4
def ts_to_mp4(ts_dir, output_mp4):
script_dir = os.path.dirname(os.path.abspath(__file__))
with open(os.path.join(script_dir, output_mp4), 'wb') as out_f:
for i in range(3169):
cid = str(i).zfill(7)
ts_file = os.path.join(script_dir, ts_dir, f"video{cid}.ts")
if os.path.exists(ts_file):
with open(ts_file, 'rb') as in_f:
out_f.write(in_f.read())
else:
print(f"文件缺失 {ts_file}")
print('合并完成')
if __name__ == '__main__':
asyncio.run(file())
ts_to_mp4("游说", "游说.mp4")或者使用subprocess
import os
import subprocess
def merge_ts_to_mp4(ts_dir, output_mp4):
#生成文件路径列表
ts_files = []
for i in range(928):
cid = str(i)
if len(str(i)) == 1:
cid = '00' + f'{i}'
elif len(str(i)) == 2:
cid = '0' + f'{i}'
ts_file = f"{ts_dir}/video{cid}.ts"
ts_files.append(ts_file)
# 创建临时文件列表
with open("filelist.txt", "w", encoding="utf-8") as f:
for file in ts_files:
f.write(f"file '{os.path.abspath(file)}'\n") # 使用绝对路径避免路径错误
# FFmpeg合并命令
command = [
"ffmpeg",
"-f", "concat",
"-safe", "0",
"-i", "filelist.txt",
"-c:v", "copy", # 复制视频流
"-c:a", "copy", # 复制音频流
"-bsf:a", "aac_adtstoasc", # 修复AAC流问题
output_mp4
]
try:
subprocess.run(command, check=True)
print(f"合并成功:{output_mp4}")
except subprocess.CalledProcessError as e:
print(f"合并失败:{e}")
finally:
if os.path.exists("filelist.txt"):
os.remove("filelist.txt") # 清理临时文件
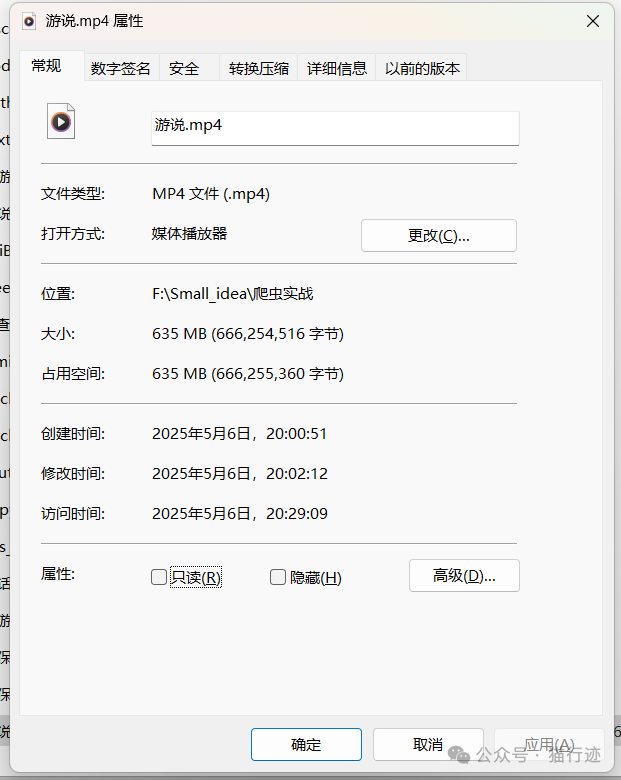
merge_ts_to_mp4("游说", "游说.mp4")运行结果:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









