








使用影刀开发小红书数据采集的朋友应该会遇到这样一个问题,使用懒加载指令时常会报出找不到指定ID元素的错误,即使按照影刀社区提供的解决方法处理也有概率报错
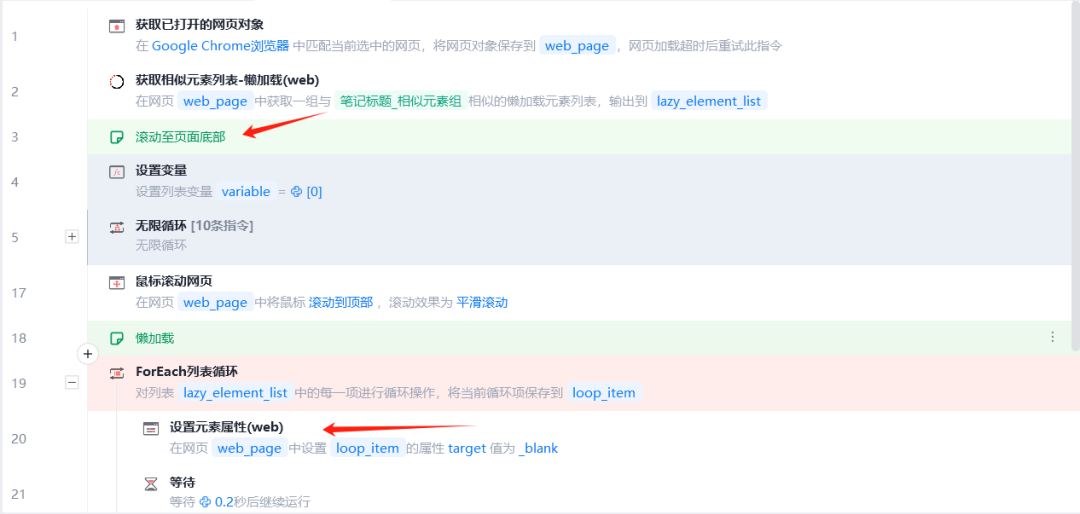
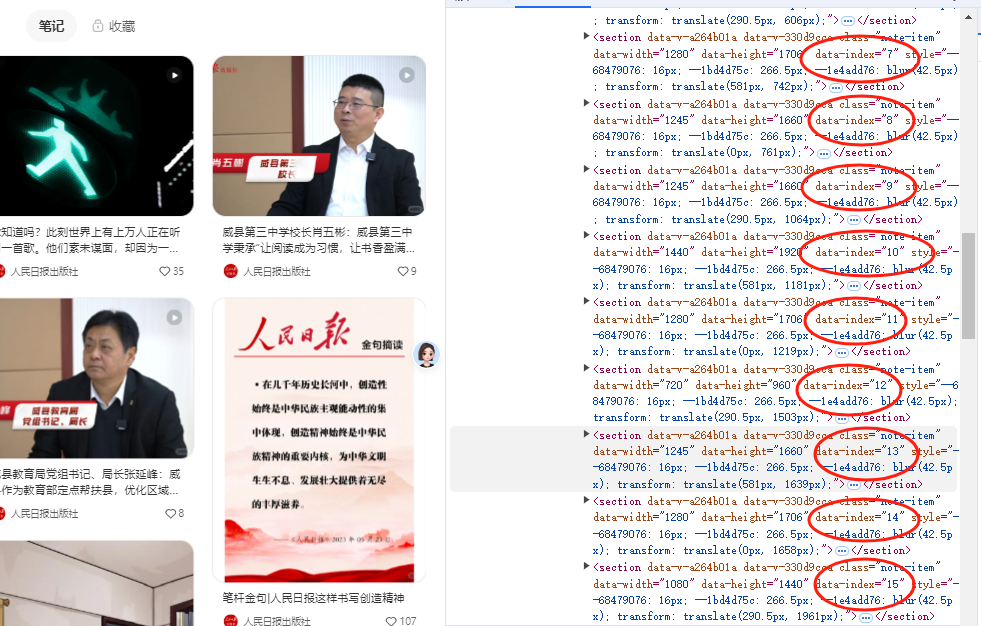
打开F12检查会发现,明明页面已经加载了三百多个元素,而捕获到的只有24个。
原来小红书用的不是懒加载技术,而是虚拟列表

我的解决方式如下,通过无限循环加字典实现
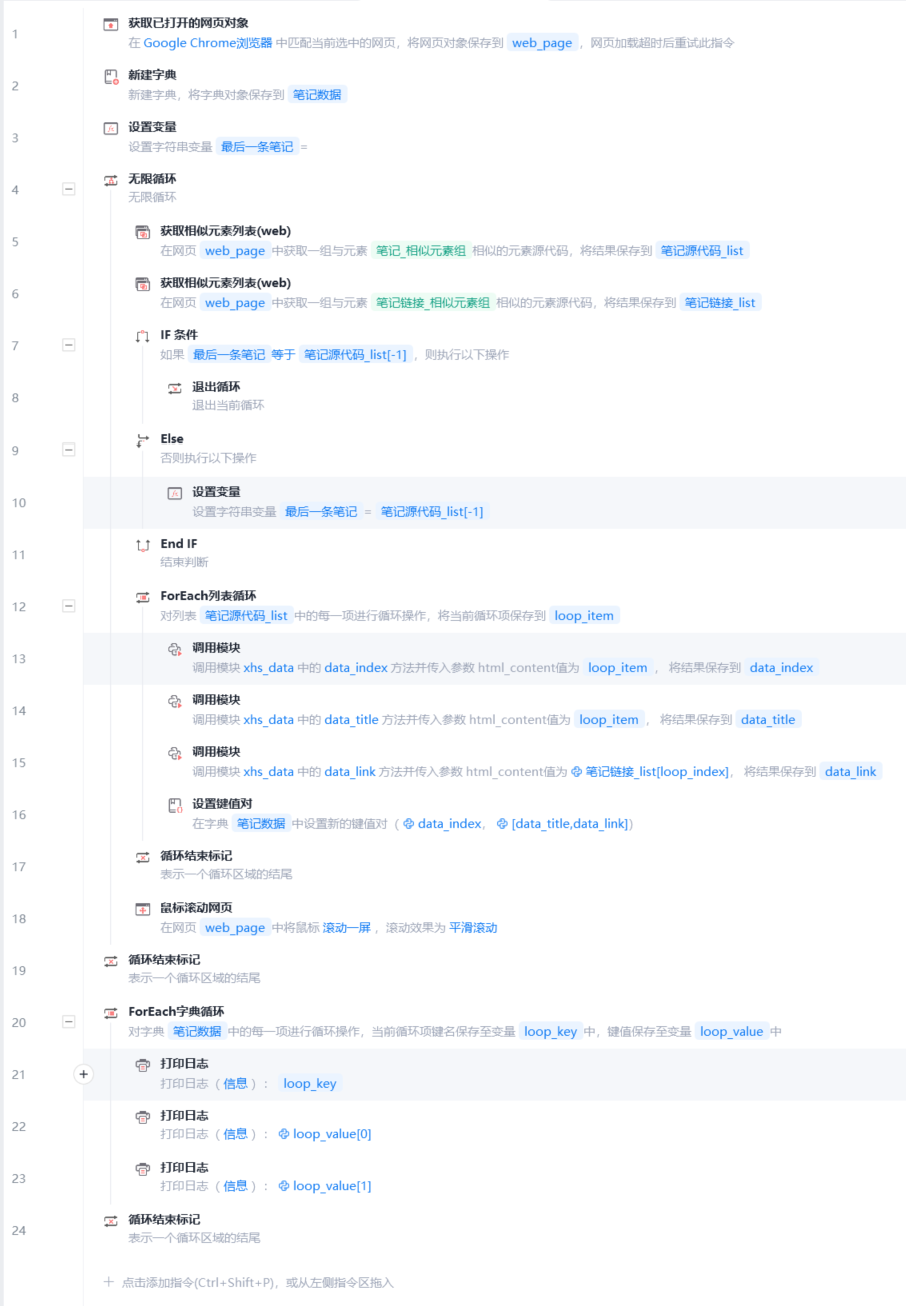
具体方法说明如下
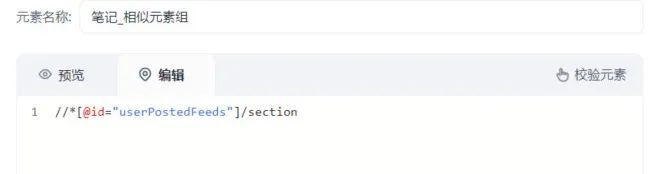
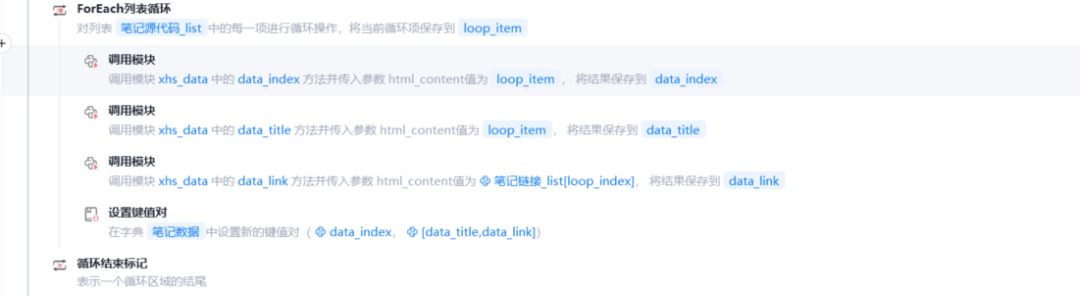
由于每次循环都会获取一次相似元素列表,而相似元素列表中又有可能有重复数据,所以我选择用data-index属性作为键名,确保唯一性,(标题可能会存在一样的标题笔记,所以不以标题作为键名)
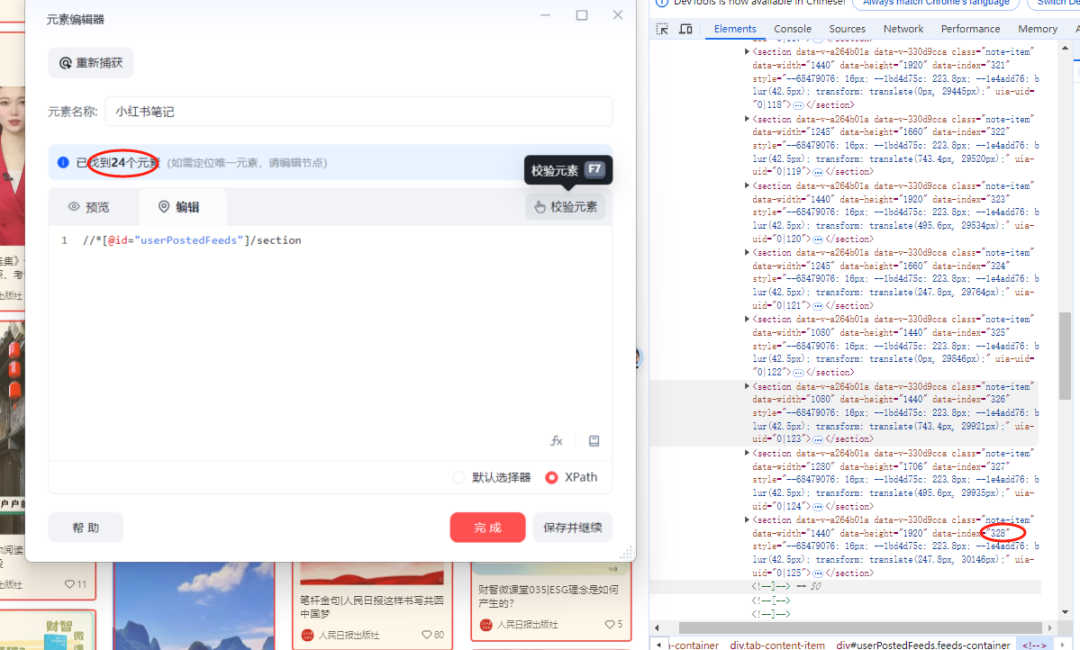
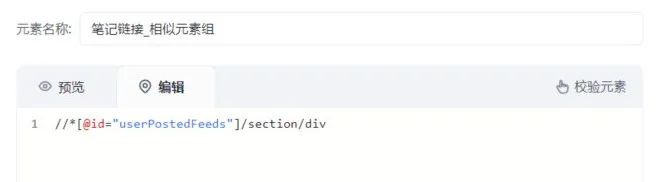
又因为,笔记链接在“//*[@id="userPostedFeeds"]/section”获取不到,所以应该多捕获一个元素列表“//*[@id="userPostedFeeds"]/section/div”
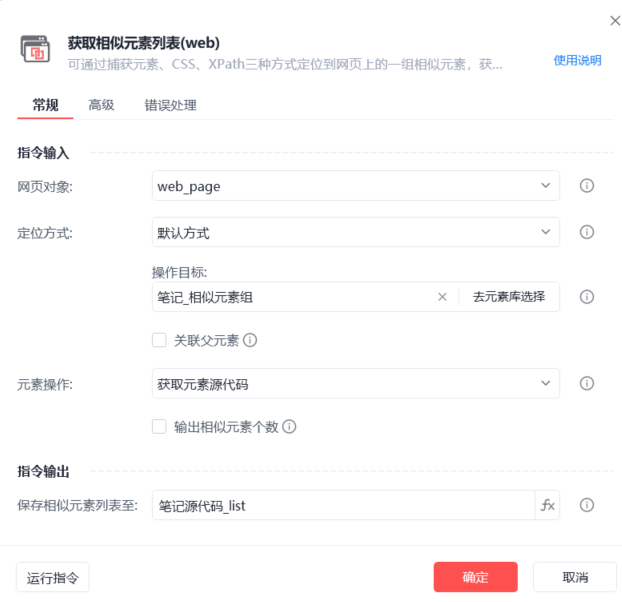
这里直接获取他们的源代码,调用Python模块对源代码进行清洗
Python代码如下
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
from bs4 import BeautifulSoup
def data_index(html_content: str):
soup = BeautifulSoup(html_content, 'html.parser')# 使用BeautifulSoup解析HTML
element = soup.find(attrs={"data-index": True})# 查找所有带有data-index属性的元素
data_index = element.get("data-index")# 提取data-index属性值
return data_index
def data_title(html_content: str):
soup = BeautifulSoup(html_content, 'html.parser')
element = soup.find('span', {'data-v-51ec0135': ''})#查找标题元素
data_title = element.text.strip()
return data_title
def data_link(html_content: str):
soup = BeautifulSoup(html_content, 'html.parser')
a_tag = soup.find('a', class_=['cover', 'mask', 'ld'])# 查找指定class的a标签
if a_tag and a_tag.has_attr('href'):# 获取href属性值
link = a_tag['href']
return f'https://www.xiaohongshu.com{link}'
return None
def main(args):
pass记得导入bs4库
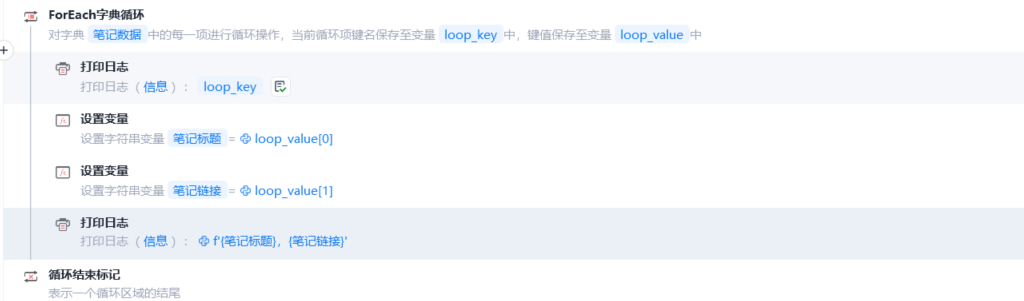
循环字典,打印输出
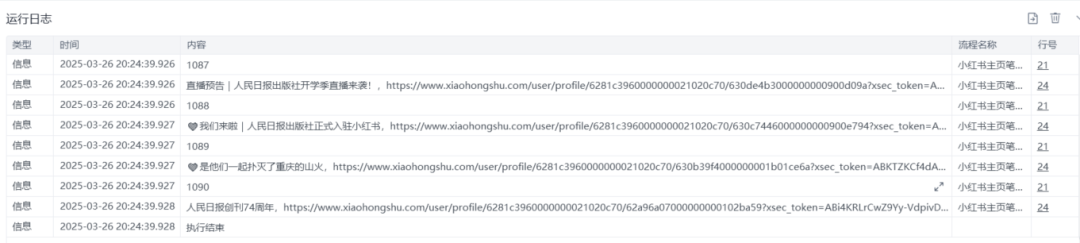
共采集1090个笔记,没有报错完美解决
相关链接:
影刀RPA | 如何批量下载小红书笔记视频/图片素材?一文教会你快速采集!


















 549
549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









