







引言
在人工智能领域,自然语言处理(Natural Language Processing, NLP)和机器学习(Machine Learning, ML)是两大支柱技术。无论是聊天机器人、情感分析,还是机器翻译,其底层都离不开对语言数据的建模与学习。而机器学习的核心范式——监督学习与无监督学习,则是推动这些应用落地的关键。本文将深入探讨这两种学习方式的原理、差异及其在NLP中的典型应用,帮助读者构建系统的知识框架。
第一部分:机器学习基础
1.1 什么是机器学习?
机器学习是让计算机通过数据自动发现规律,并利用这些规律进行预测或决策的技术。其核心思想是“从数据中学习”,而非依赖硬编码的规则。例如:
-
传统编程:手动编写规则判断邮件是否为垃圾邮件(如包含“免费”“点击链接”等关键词)。
-
机器学习:通过大量标注数据(垃圾邮件/正常邮件)训练模型,使其自动识别垃圾邮件的特征。
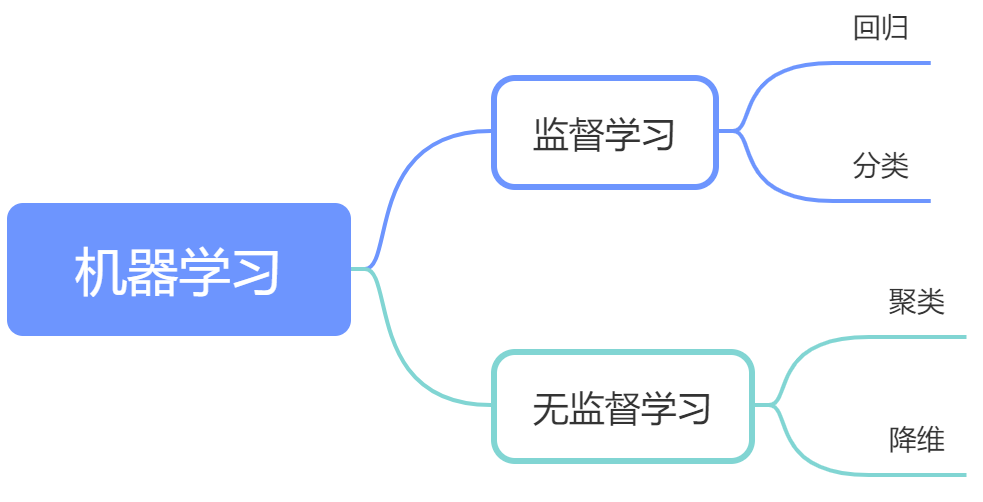
1.2 监督学习 vs. 无监督学习
根据数据是否有标签(Label),机器学习可分为两类:
-
监督学习:数据包含输入特征和对应的标签(正确答案),模型通过学习特征与标签的关系进行预测。
-
无监督学习:数据仅包含输入特征,模型自主发现数据中的潜在模式(如聚类、降维)。
两者的区别可类比为“有参考答案的学习”和“自主探索的学习”。
第二部分:监督学习详解
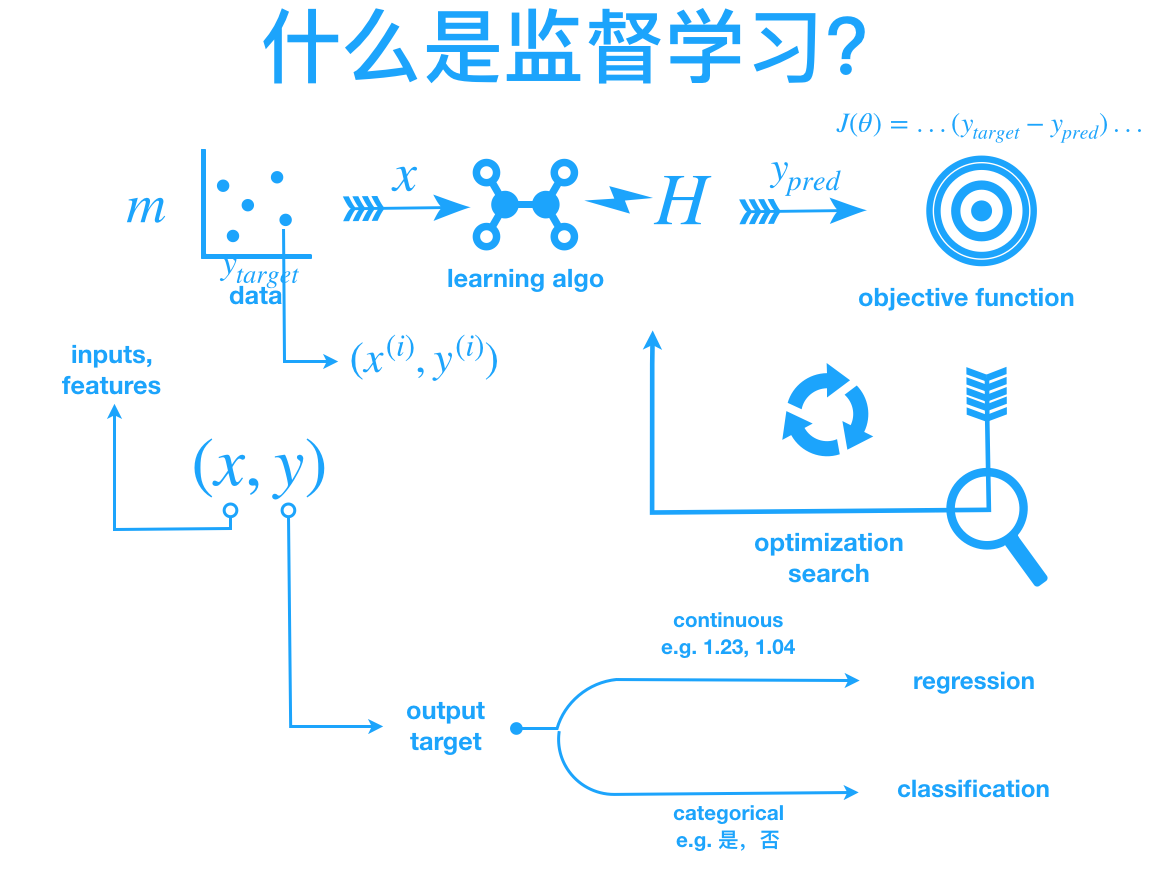
2.1 监督学习的基本流程
-
数据准备:收集带有标签的数据集(如“文本+情感标签”)。
-
特征工程:将原始数据转换为模型可理解的数值特征(如词袋模型、TF-IDF)。
-
模型训练:选择算法(如逻辑回归、神经网络)拟合特征与标签的关系。
-
评估与优化:使用验证集评估模型性能(准确率、F1值),调整超参数。
-
预测:对新数据(如用户评论)进行分类或回归。
2.2 监督学习的核心算法
-
分类任务:逻辑回归、支持向量机(SVM)、决策树、随机森林。
-
回归任务:线性回归、梯度提升树(GBDT)。
-
深度学习:卷积神经网络(CNN)、循环神经网络(RNN)、Transformer。
2.3 NLP中的监督学习应用
-
文本分类:新闻主题分类、垃圾邮件检测。
-
情感分析:判断评论的正负面情绪(如“这部电影很棒” → 正面)。
-
命名实体识别(NER):从文本中提取人名、地点、机构名。
-
机器翻译:基于平行语料库(如中英文对照句子)训练翻译模型。
案例:情感分析实战
使用Python的Scikit-learn库,通过以下步骤实现:
-
加载标注数据集(如IMDB影评)。
-
使用TF-IDF将文本转换为向量。
-
训练逻辑回归模型。
-
预测新评论的情感
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.linear_model import LogisticRegression # 示例代码 vectorizer = TfidfVectorizer() X_train = vectorizer.fit_transform(train_texts) model = LogisticRegression() model.fit(X_train, train_labels)
第三部分:无监督学习详解
3.1 无监督学习的核心任务
-
聚类(Clustering):将数据分组,使同一组内数据相似度高(如K-means、层次聚类)。
-
降维(Dimensionality Reduction):压缩数据维度,保留主要信息(如PCA、t-SNE)。
-
关联规则挖掘:发现数据中的频繁项集(如“购买牛奶的用户也常买面包”)。
3.2 无监督学习的优势与挑战
-
优势:无需标注数据,适合探索性分析;能发现隐藏模式。
-
挑战:结果难以量化评估;对噪声敏感。
3.3 NLP中的无监督学习应用
-
主题建模:通过LDA(Latent Dirichlet Allocation)从文档集合中提取主题。
-
词嵌入(Word Embedding):Word2Vec、GloVe将词语映射为低维向量,捕捉语义关系。
-
文本摘要:基于聚类或图算法提取关键句子。
-
异常检测:识别社交媒体中的异常言论。
案例:使用Word2Vec发现词语关联
通过无监督训练词向量,模型可自动学习语义相似性:
from gensim.models import Word2Vec
sentences = [["自然", "语言", "处理"], ["机器学习", "深度学习"]]
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1)
print(model.wv.most_similar("语言", topn=3))
# 输出:[('处理', 0.92), ('自然', 0.88), ('深度学习', 0.75)]第四部分:监督与无监督学习的结合
4.1 半监督学习
-
场景:少量标注数据 + 大量未标注数据。
-
应用:利用无监督学习预训练(如语言模型),再用监督学习微调(Fine-tuning)。
案例:BERT预训练(掩码语言模型) + 下游任务微调(如问答系统)。
4.2 自监督学习
-
本质是无监督学习的一种,通过设计代理任务(Pretext Task)生成标签。
案例:预测句子中被遮蔽的词语(Masked Language Model)。
第五部分:如何选择学习范式?
| 维度 | 监督学习 | 无监督学习 |
|---|---|---|
| 数据要求 | 需大量标注数据 | 无需标注数据 |
| 典型任务 | 分类、回归 | 聚类、降维 |
| 结果可解释性 | 高(如决策树规则) | 低(需人工分析聚类结果) |
| NLP应用场景 | 情感分析、机器翻译 | 主题建模、词向量训练 |
结语
监督学习与无监督学习是机器学习的“双翼”,在NLP中各有不可替代的价值。随着预训练模型(如GPT-4)的兴起,两者界限逐渐模糊——模型先在无标注数据上预训练,再通过监督学习适应具体任务。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









