






大型语言模型 (LLM) 正在变革人工智能,使计算机能够生成和理解类似人类的文本,使其成为各行各业不可或缺的人才。全球 LLM 市场正在快速扩张,预计到 2030 年,其规模将从2023 年的15.9 亿美元增长至 2598 亿美元,这主要得益于自动化内容创作的需求、人工智能的进步以及对更佳人机沟通的需求。
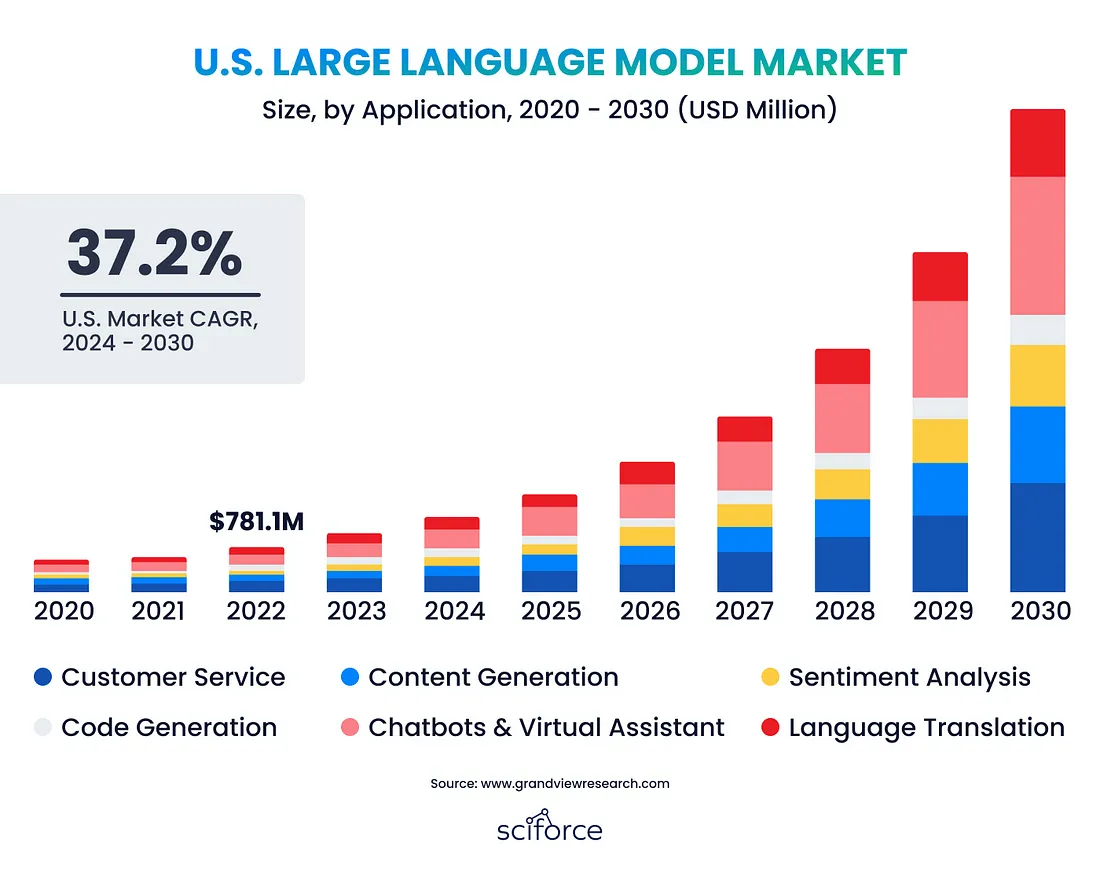
这种增长源于对自动化内容创作、人工智能 (AI) 和自然语言处理 (NLP) 进步、人机交互改进以及海量数据集的需求。随着企业寻求对数据和定制化控制权,私人法学硕士 (LLM) 正日益受到青睐。它们提供量身定制的解决方案,减少对外部提供商的依赖,并增强数据隐私。本指南将帮助您构建自己的私人法学硕士 (LLM),无论您是法学硕士 (LLM) 新手还是希望拓展专业知识,都能获得宝贵的见解。
什么是大型语言模型?
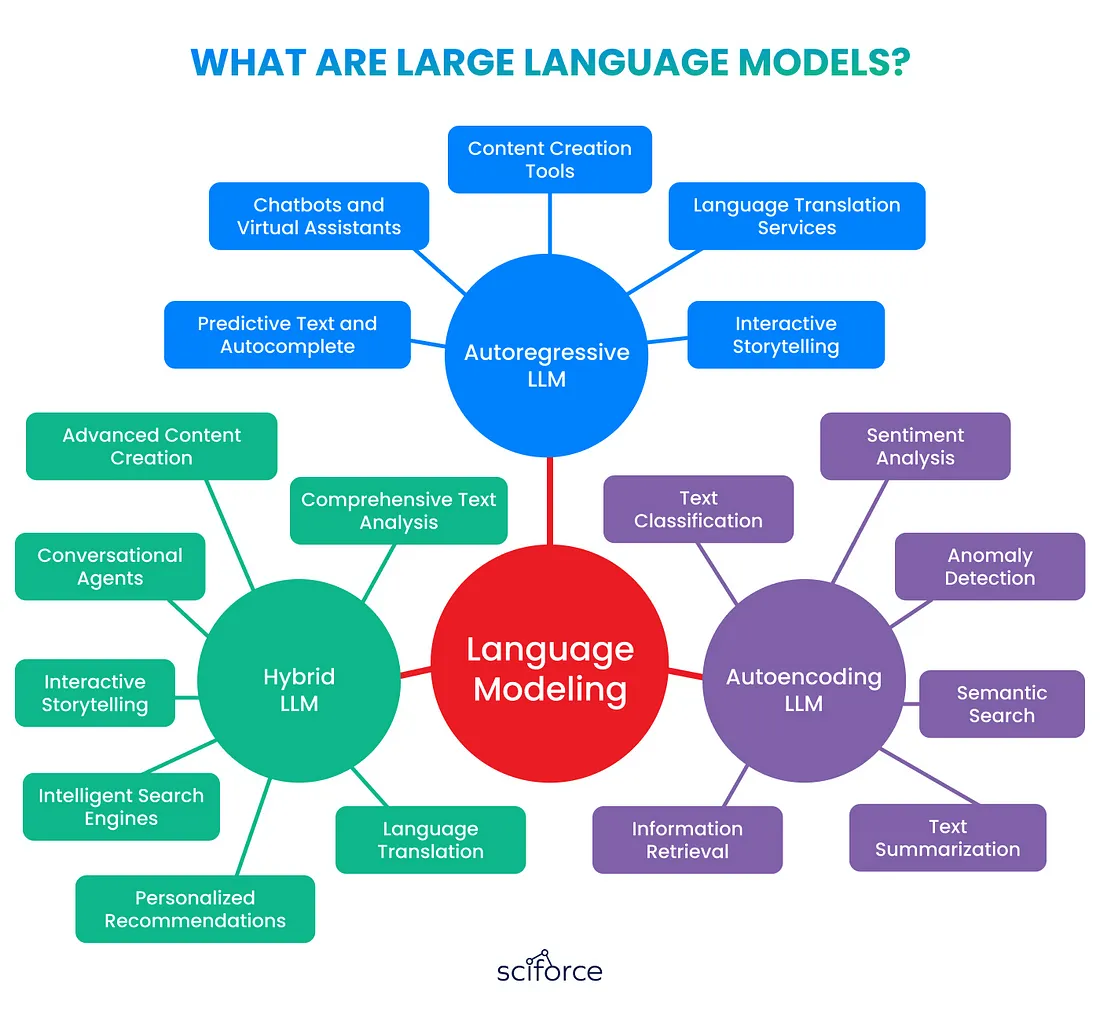
大型语言模型 (LLM) 是先进的 AI 系统,它使用复杂的神经网络(例如 Transformer)处理海量数据,从而生成类似人类的文本。它们可以创建内容、翻译语言、回答问题并参与对话,这使其在客户服务和数据分析等各行各业都具有巨大的价值。
- 自回归法学硕士根据前面的单词预测句子中的下一个单词,使其成为文本生成等任务的理想选择。
- 自动编码法学硕士 (LLM)专注于编码和重建文本,在情感分析和信息检索等任务中表现出色。
- 混合法学硕士 (LLM)结合了两种方法的优势,为复杂的应用提供了多种解决方案。
法学硕士(LLM)通过处理来自各种来源的海量文本来学习语言规则,就像阅读大量书籍有助于理解语言一样。经过训练后,他们能够运用所学知识撰写内容、回答问题并参与对话。
例如,法学硕士可以根据阅读太空冒险故事的知识创作一个关于太空的故事,或者通过回忆生物学文本中的信息来解释光合作用。
建立私人法学硕士学位
法学硕士 (LLM) 的数据管理
近期的 LLM 模型(例如 Llama 3 和 GPT-4)均基于海量数据集进行训练——Llama 3拥有 15 万亿个 token,GPT-4拥有 6.5 万亿个 token。这些数据集来自各种环境,包括社交媒体(140 万亿个token)和私人数据,规模从数百 TB 到数 PB 不等。这种广泛的训练确保模型能够深入理解语言,涵盖各种模式、词汇和语境。
- 网络数据:FineWeb(未完全去重以获得更好的性能,全部为英文)、Common Crawl(55%非英文)
- 代码:来自所有主要代码托管平台的公开可用代码
- 学术文本:安娜档案、谷歌学术、谷歌专利
- 图书:Google 图书、安娜的档案
- 法院文件:RECAP 档案(美国)、开放法律数据(德国)
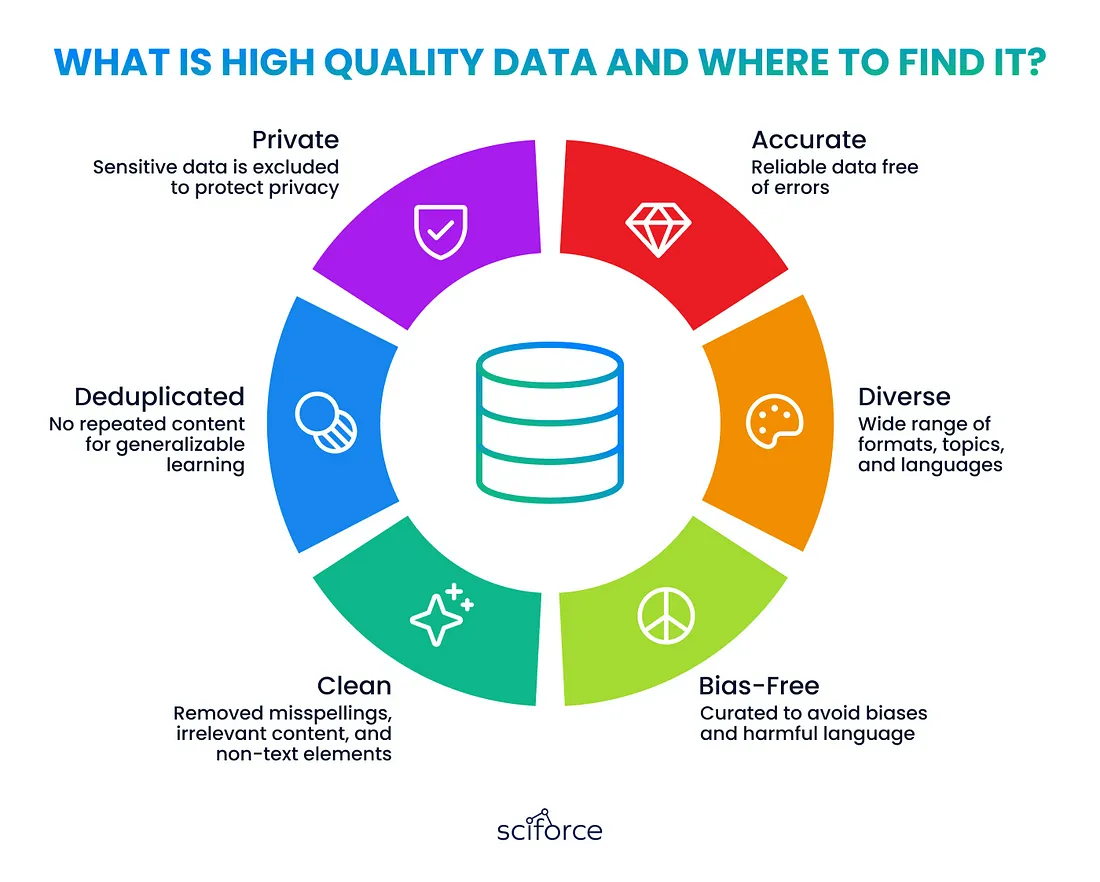
数据预处理
在为 LLM 整理数据时,清理和结构化之后的关键步骤包括使用标记化、嵌入和注意机制将数据转换为模型可以学习的格式:
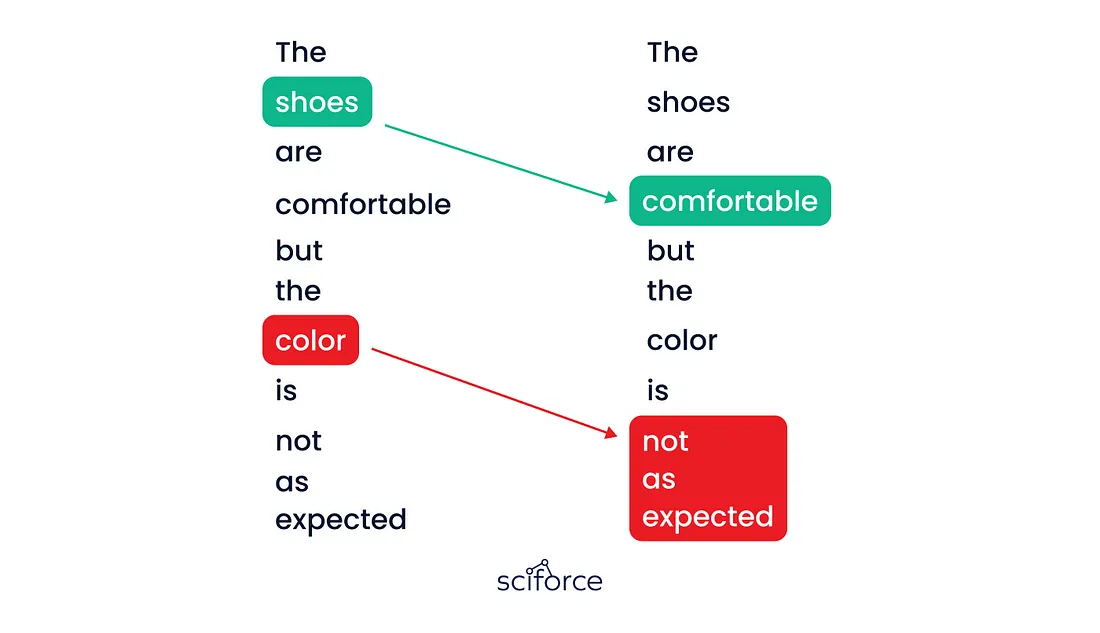
- 标记化将文本分解成更小的部分,例如单词或字符,从而使模型能够有效地处理和理解每个部分。

- 嵌入将客户评论转换为捕捉情感和意义的数字向量,帮助模型分析反馈并改进建议。
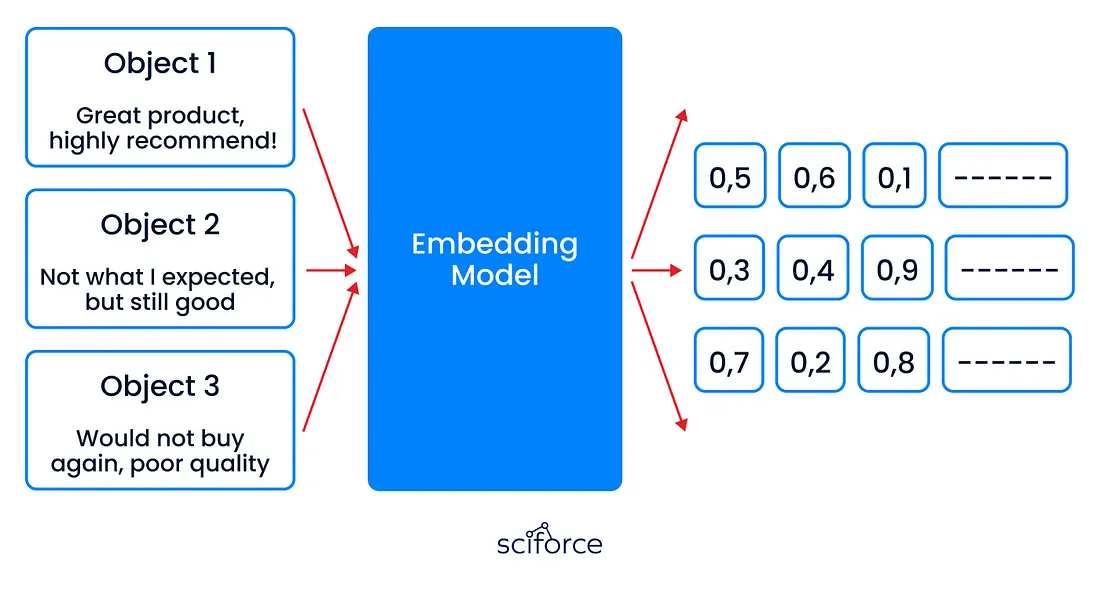
- 注意力集中在句子的最重要部分,确保模型准确掌握关键情绪,例如区分产品质量和服务问题。
LLM培训循环
数据输入和准备
- 数据提取:从各种来源收集和加载数据。
- 数据清理:消除噪音、处理缺失数据并编辑敏感信息。
- 规范化:标准化文本,处理分类数据,并确保数据的一致性。
- 分块:将大文本分成可管理的块,同时保留上下文。
- 标记化:将文本块转换为标记以供模型处理。
- 数据加载:高效加载和调整数据以优化训练,必要时使用并行加载。
损失计算
- 计算损失:使用损失函数将预测与真实标签进行比较,将差异转换为“损失”或“错误”值。
- 绩效指标:损失越大,准确率越差;损失越低,表明与实际目标越吻合。
超参数调整
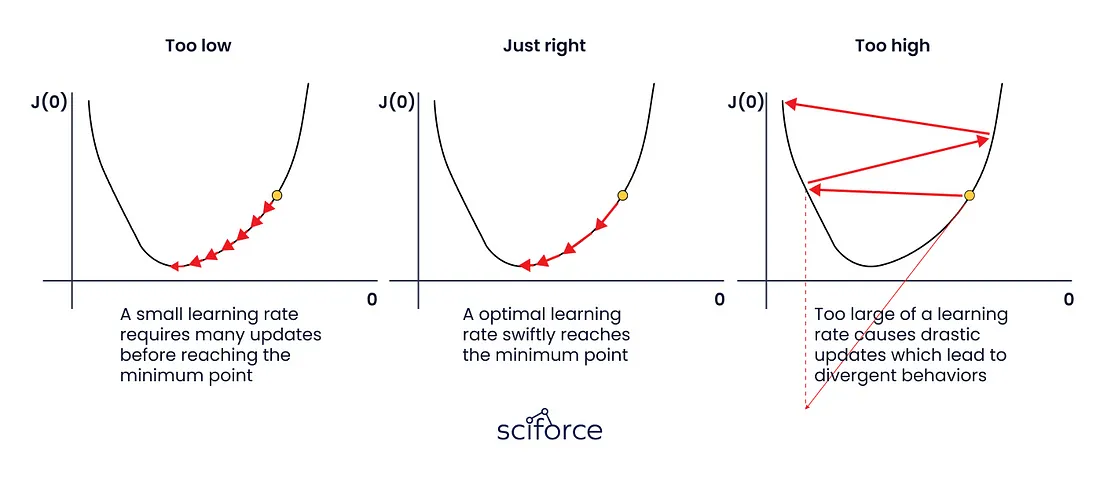
- 学习率:控制训练期间的权重更新大小——太高可能会导致不稳定;太低会减慢训练速度。
- 批次大小:每次迭代的样本数——较大的批次可以稳定训练,但需要更多的内存;较小的批次会引入可变性,但资源密集度较低。
并行化和资源管理
- 数据并行化:将数据集拆分到多个 GPU 上,以便更快地处理。
- 模型并行化:将模型划分到各个 GPU 上,以处理大型模型。
- 梯度检查点:通过选择性地存储中间结果来减少训练期间的内存使用量。
迭代和时期
- 迭代:处理批量数据,每次更新权重。
- Epochs:完整遍历数据集,每次遍历都会改进模型的参数。
- 监控:跟踪每个时期后的损失和准确度等指标,以指导调整并防止过度拟合。
评估你的法学硕士学位
评估法学硕士(LLM)的培训后表现至关重要,以确保其符合要求的标准。常用的行业标准基准包括:
- MMLU(大规模多任务语言理解):评估广泛学科的自然语言理解和推理能力。
- GPQA(通用问答):测试模型处理跨领域的多样化、复杂问题的能力。
- 数学:通过解决多步骤问题来衡量模型的数学推理能力。
- HumanEval:通过评估模型生成准确、实用的代码的能力来评估编码能力。
对于从零开始构建法学硕士 (LLM) 的人来说,像Arena这样的平台提供了动态的、用户驱动的评估,允许用户比较模型。OpenAI 和 Anthropic 等公司定期发布 GPT 和 Claude 等模型的基准测试结果,展示 LLM 功能的进步。
在针对特定任务对 LLM 进行微调时,指标应与应用目标保持一致。例如,在医疗环境中,可以优先考虑疾病描述与代码匹配的准确性。
结论
构建私有 LLM 是一个充满挑战却又回报丰厚的过程,它能够提供无与伦比的定制化、数据安全性和性能。通过整理数据、选择合适的架构并微调模型,您可以根据自身需求打造一个强大的工具。
LLM大模型相关资料+资料包↓(或看我个人简介处)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









