






导入必要的包
import tensorflow as tf
import pandas as pd
import random
import pathlib
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
#导入模型包
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Flatten, Dropout, Conv2D, MaxPooling2D, BatchNormalization
from tensorflow.keras import layers, models
#导入优化器包
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.callbacks import ModelCheckpoint, TensorBoard # 添加TensorBoard导入
#导入解压工具包
import zipfile
import os1.加载数据
1.1解压数据集与查看数据
zip_file_path = '/data/bigfiles/flower_photos.zip'
extract_to_path = 'extracted_files' #解压路径
os.makedirs(extract_to_path, exist_ok=True) # 创建目标目录(如果不存在)
with zipfile.ZipFile(zip_file_path, 'r') as zip_ref: # 解压文件
zip_ref.extractall(extract_to_path)
print(f"文件已解压到: {extract_to_path}")文件已解压到: extracted_files
# 列出目录中的所有文件和子目录
extract_to_path = 'extracted_files/flower_photos/roses'
files = os.listdir(extract_to_path)
# 打印文件列表
print("解压后的文件列表:")
for file in files:
print(file)解压后的文件列表: 10090824183_d02c613f10_m.jpg 102501987_3cdb8e5394_n.jpg
......
1.2数据预处理
确定数据集的数据类型、数据尺寸、标签、是否划分训练集与测试集等
def dataset(data_path, image_size=(32,32)):
data_path = pathlib.Path(data_path)
all_image_paths = list(data_path.glob('*/*'))
all_image_paths = [str(path) for path in all_image_paths]
random.shuffle(all_image_paths)
image_count = len(all_image_paths)
print('数据量大小:', image_count )
label_names = sorted(item.name for item in data_path.glob('*/') if item.is_dir())
print('分类名:', label_names)
label_to_index = dict((name, index) for index, name in enumerate(label_names))
print('标签:', label_to_index)
all_image_labels = np.array([label_to_index[pathlib.Path(path).parent.name] for path in all_image_paths])
all_image_data = []
for path in all_image_paths:
img = Image.open(path)
img = img.resize(image_size)
img = np.array(img)/255.0
all_image_data.append(img)
all_image_data = np.array(all_image_data)
# 补充数据划分代码
train_images, test_images, train_labels, test_labels = train_test_split(
all_image_data, all_image_labels, test_size=0.2, random_state=42
)
return train_images, test_images, train_labels, test_labels, label_names
# 获取数据和标签信息
data_path = 'extracted_files/flower_photos'
train_images, test_images, train_labels, test_labels, label_names = dataset(data_path)
input_shape = (32,32,3)
classes = len(label_names)
class_dict = {i: name for i, name in enumerate(label_names)}数据量大小: 1340
分类名: ['roses', 'sunflowers']
标签: {'roses': 0, 'sunflowers': 1}
2.构建模型
def myCNN(input_shape, classes):
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=input_shape))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(classes, activation='softmax')) # 修正输出层
model.summary()
return model
2.1构建LeNet模型
from tensorflow.keras import layers, Model
class LeNet(Model): # 修正类名和继承自Model
def __init__(self, classes=2): # 添加classes参数
super(LeNet, self).__init__() # 修正super调用
# 定义各层
self.conv1 = layers.Conv2D(6, (5,5), activation='relu') # 修正Conv20为Conv2D
self.pool1 = layers.AveragePooling2D((2,2))
self.conv2 = layers.Conv2D(16, (5,5), activation='relu')
self.pool2 = layers.AveragePooling2D((2,2))
self.flatten = layers.Flatten() # 修正flatten为Flatten
self.dense1 = layers.Dense(120, activation='relu')
self.dense2 = layers.Dense(84, activation='relu')
self.dense3 = layers.Dense(classes, activation='softmax') # 使用参数设置输出单元
def call(self, inputs):
# 定义前向传播
x = self.conv1(inputs)
x = self.pool1(x)
x = self.conv2(x) # 修正inputs为x,保持数据流
x = self.pool2(x)
x = self.flatten(x)
x = self.dense1(x)
x = self.dense2(x)
return self.dense3(x) # 返回最后一层的输出
# 使用示例
input_shape = (32, 32, 3) # 假设输入尺寸
classes = 5 # 分类数
# 创建模型实例
model = LeNet(classes=classes)
# 构建模型(需要指定输入形状)
model.build(input_shape=(None,) + input_shape)
model.summary()
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练示例(需要实际数据)
# history = model.fit(train_images, train_labels, epochs=10, validation_data=(val_images, val_labels))Model: "le_net" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_6 (Conv2D) multiple 456 _________________________________________________________________ average_pooling2d (AveragePo multiple 0 _________________________________________________________________ conv2d_7 (Conv2D) multiple 2416 _________________________________________________________________ average_pooling2d_1 (Average multiple 0 _________________________________________________________________ flatten_2 (Flatten) multiple 0 _________________________________________________________________ dense_4 (Dense) multiple 48120 _________________________________________________________________ dense_5 (Dense) multiple 10164 _________________________________________________________________ dense_6 (Dense) multiple 425 ================================================================= Total params: 61,581 Trainable params: 61,581 Non-trainable params: 0
2.2构建AlexNet模型
from tensorflow.keras import models, layers
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
def AlexNet(input_shape, classes):
"""
简化的AlexNet顺序模型
参数:
input_shape -- 输入图像的形状 (height, width, channels)
classes -- 分类数量
返回:
Keras Sequential模型
"""
model = models.Sequential()
# 第一卷积层
model.add(Conv2D(32, (3,3), strides=(1,1), activation='relu', input_shape=input_shape))
model.add(MaxPooling2D((2,2), strides=(2,2)))
# 第二卷积层
model.add(Conv2D(64, (3,3), padding='same', activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
# 连续三个卷积层
model.add(Conv2D(96, (3,3), padding='same', activation='relu'))
model.add(Conv2D(96, (3,3), padding='same', activation='relu'))
model.add(Conv2D(64, (3,3), padding='same', activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
# 展平层
model.add(Flatten())
# 全连接层(建议在大型数据集上取消Dropout注释)
model.add(Dense(1024, activation='relu'))
# model.add(Dropout(0.5)) # 防止过拟合
model.add(Dense(512, activation='relu'))
# model.add(Dropout(0.5)) # 防止过拟合
# 输出层
model.add(Dense(classes, activation='softmax'))
model.summary()
return model
# 使用示例
input_shape = (32, 32, 3) # 输入图像尺寸
classes = 5 # 假设有5个花卉类别
# 初始化模型
model = AlexNet(input_shape, classes)
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型 (需要传入训练数据)
# history = model.fit(train_images, train_labels, epochs=10, validation_data=(val_images, val_labels))Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_8 (Conv2D) (None, 30, 30, 32) 896 _________________________________________________________________ max_pooling2d_4 (MaxPooling2 (None, 15, 15, 32) 0 _________________________________________________________________ conv2d_9 (Conv2D) (None, 15, 15, 64) 18496 _________________________________________________________________ max_pooling2d_5 (MaxPooling2 (None, 7, 7, 64) 0 _________________________________________________________________ conv2d_10 (Conv2D) (None, 7, 7, 96) 55392 _________________________________________________________________ conv2d_11 (Conv2D) (None, 7, 7, 96) 83040 _________________________________________________________________ conv2d_12 (Conv2D) (None, 7, 7, 64) 55360 _________________________________________________________________ max_pooling2d_6 (MaxPooling2 (None, 3, 3, 64) 0 _________________________________________________________________ flatten_3 (Flatten) (None, 576) 0 _________________________________________________________________ dense_7 (Dense) (None, 1024) 590848 _________________________________________________________________ dense_8 (Dense) (None, 512) 524800 _________________________________________________________________ dense_9 (Dense) (None, 5) 2565 ================================================================= Total params: 1,331,397 Trainable params: 1,331,397 Non-trainable params: 0
2.3构建VGG模型
# 函数式模型VGG
def VGG(input_shape, classes):
input = Input(shape=input_shape)
# Block 1
x = Conv2D(32, (3,3), strides=(1,1), padding='same', activation='relu', name='conv1')(input)
x = Conv2D(32, (3,3), strides=(1,1), padding='same', activation='relu', name='conv2')(x)
x = MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='valid', name='pool1')(x)
# Block 2
x = Conv2D(64, (3,3), strides=(1,1), padding='same', activation='relu', name='conv3')(x)
x = Conv2D(64, (3,3), strides=(1,1), padding='same', activation='relu', name='conv4')(x)
x = MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='valid', name='pool2')(x)
# Block 3
x = Conv2D(128, (3,3), strides=(1,1), padding='same', activation='relu', name='conv5')(x)
x = Conv2D(128, (3,3), strides=(1,1), padding='same', activation='relu', name='conv6')(x)
x = Conv2D(128, (3,3), strides=(1,1), padding='same', activation='relu', name='conv7')(x)
x = MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='valid', name='pool3')(x)
# Fully connected layers
x = Flatten()(x)
x = Dense(256, activation='relu', name='fc1')(x)
x = Dropout(0.5)(x)
x = Dense(256, activation='relu', name='fc2')(x)
x = Dropout(0.5)(x)
x = Dense(classes, activation='softmax', name='fc_predictions')(x)
model = Model(inputs=input, outputs=x, name='VGG')
model.summary()
return model
# 在模型构建部分使用VGG模型
model = VGG(input_shape, classes) # 替换原来的myCNN
# 编译模型
learning_rate = 0.001
sgd = SGD(learning_rate=learning_rate, momentum=0.9)
model.compile(loss='sparse_categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy'])
# 训练模型
num_epochs = 20
history = model.fit(
train_images, train_labels,
epochs=num_epochs,
validation_data=(test_images, test_labels),
callbacks=[checkpoint, tensorboard]
)Model: "VGG" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 32, 32, 3)] 0 _________________________________________________________________
......
import matplotlib.pyplot as plt
def plot_training_history(history):
"""
绘制训练过程中的loss和accuracy曲线
参数:
history -- 由model.fit()返回的训练历史对象
"""
# 提取训练和验证的loss和accuracy数据
train_loss = history.history['loss']
val_loss = history.history['val_loss']
train_acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
# 创建画布
plt.figure(figsize=(12, 5))
# 绘制loss曲线
plt.subplot(1, 2, 1)
plt.plot(train_loss, label='Train Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
# 绘制accuracy曲线
plt.subplot(1, 2, 2)
plt.plot(train_acc, label='Train Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
plt.show()
# 在模型训练后调用绘图函数
plot_training_history(history) # 使用训练返回的history对象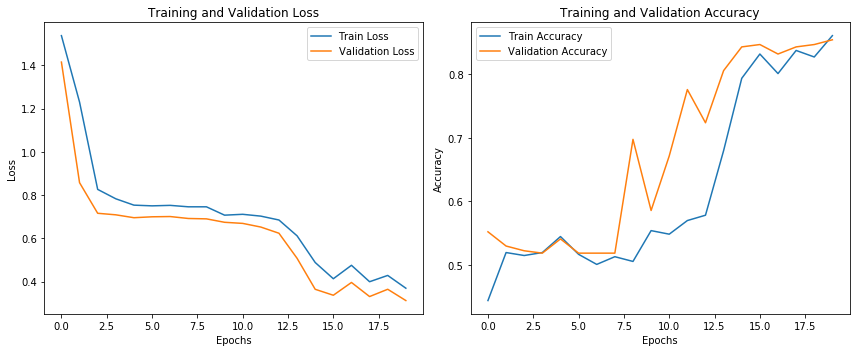
3.模型编译
#“请完善'?'处代码,选择模型”
model = myCNN(input_shape, classes) # 选择模型
#“请完善'?'处代码,选择学习率”
learning_rate = 0.001
sgd = SGD(learning_rate=learning_rate, momentum=0.9)
#“请完善此处代码,设置模型编译,loss='sparse_categorical_crossentropy', optimizer=sgd, metrics=['accuracy']”
# 编译模型
model.compile(loss='sparse_categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy'])Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 30, 30, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 15, 15, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 13, 13, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 6, 6, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 4, 4, 64) 36928 _________________________________________________________________ flatten (Flatten) (None, 1024) 0 _________________________________________________________________ dense (Dense) (None, 64) 65600 _________________________________________________________________ dense_1 (Dense) (None, 2) 130 ================================================================= Total params: 122,050 Trainable params: 122,050 Non-trainable params: 0
4.模型训练
num_epochs = 20
#“请完善此处代码,使用fit方法完成模型训练”
# 创建回调
checkpoint = ModelCheckpoint(
'extracted_files/ckpt/cp-{epoch:04d}.ckpt',
save_weights_only=True,
verbose=1,
save_freq='epoch'
)
tensorboard = TensorBoard(log_dir='extracted_files/logs')
# 训练模型
history = model.fit(
train_images, train_labels,
epochs=num_epochs,
validation_data=(test_images, test_labels),
callbacks=[checkpoint, tensorboard]
)Epoch 1/20 34/34 [==============================] - 2s 54ms/step - loss: 0.6862 - accuracy: 0.5392 - val_loss: 0.6732 - val_accuracy: 0.6157 ...... Epoch 00020: saving model to extracted_files/ckpt/cp-0020.ckpt
5.模型评估
#“请完善此处代码,使用evaluate方法完成模型评估”
test_loss, test_acc = model.evaluate(test_images, test_labels) # 评估模型
print('准确率{0:.2f}%'.format(test_acc*100))9/9 [==============================] - 0s 4ms/step - loss: 0.2619 - accuracy: 0.8731 准确率87.31%
#设置权重保存路径
ckpt_dir = 'extracted_files/ckpt'
if not os.path.exists(ckpt_dir):
os.makedirs(ckpt_dir)
check_path = 'extracted_files/ckpt/cp-{epoch:04d}.ckpt'
checkpoint = ModelCheckpoint(check_path, save_weights_only=True, verbose=1, save_freq='epoch')
log_dir = os.path.join('extracted_files/logs')
if not os.path.exists(log_dir):
os.mkdir(log_dir)
tensorboard = TensorBoard(log_dir = log_dir)6.单张图片预测
data_path_1 = '/data/bigfiles/predict_1.jpg'
img_1 = Image.open(data_path_1)
plt.imshow(img_1)
plt.axis('off')
plt.show
data_path_2 = '/data/bigfiles/predict_2.jpg'
img_2 = Image.open(data_path_2)
plt.imshow(img_2)
plt.axis('off')
plt.show<function matplotlib.pyplot.show(*args, **kw)>

class_dict = {0:'roses',1:'sunflowers'}
class Predict():
def __init__(self):
#“请完善'?'处代码,选择模型”
self.network = myCNN(input_shape, classes) # 初始化模型
self.network.load_weights('extracted_files/ckpt/cp-0020.ckpt')
self.class_dict = class_dict
def predict(self, image_path):
img = Image.open(image_path)
img = img.resize((32,32), resample = Image.BILINEAR)
x = np.expand_dims(np.array(img)/255.0, axis=0)
#“请完善'?'处代码,模型预测”
y = self.network.predict(x) # 执行预测
class_index = np.argmax(y[0])
class_name = self.class_dict[class_index]
print(y[0],'预测结果:',class_name)
return class_name
if __name__ == '__main__':
pre = Predict()
pre.predict('/data/bigfiles/predict_1.jpg')
pre.predict('/data/bigfiles/predict_2.jpg')Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_3 (Conv2D) (None, 30, 30, 32) 896 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 15, 15, 32) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 13, 13, 64) 18496 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 6, 6, 64) 0 _________________________________________________________________ conv2d_5 (Conv2D) (None, 4, 4, 64) 36928 _________________________________________________________________ flatten_1 (Flatten) (None, 1024) 0 _________________________________________________________________ dense_2 (Dense) (None, 64) 65600 _________________________________________________________________ dense_3 (Dense) (None, 2) 130 ================================================================= Total params: 122,050 Trainable params: 122,050 Non-trainable params: 0 _________________________________________________________________ [0.03079483 0.96920514] 预测结果: sunflowers [0.9230295 0.07697055] 预测结果: roses


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









