






- 实验名称
机器学习多分类算法项目实践
- 实验目的
- 掌握机器学习算法使用的一般流程;
- 能够使用合适的方法对数据集进行预处理;
- 能够正确调用机器学习算法,实现多分类任务;
- 能够通过绘制混淆矩阵及计算准确度、精确度、召回率等,评估算法性能。
- 实验内容
本实验使用红酒品类分类数据,让学生能够自主的根据所学内容,对该数据集进行数据的预处理、特征的筛选,然后调用合适的机器学习算法对数据进行训练、预测,最后使用准确度、精确度、召回率、混淆矩阵等模型性能评价方法对算法性能进行评估。
- 实验器材
装有pycharm、anaconda软件的计算机一台
五、实验步骤及结果分析
(1)读取数据集,并对数据进行正确预处理,处理成机器学习算法能够调用的形式。
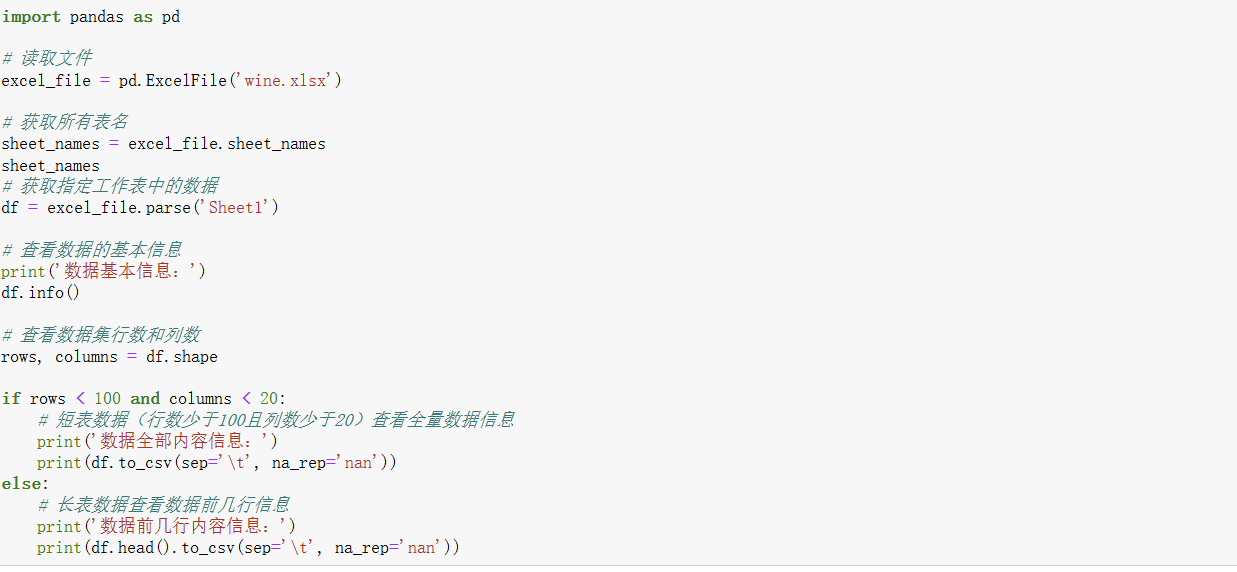
导入pandas库,用于数据处理和分析,使用pd.Excelfile函数读取wine.xlsx文件。最后将文件内的数据赋值给df,此时df是一个包含葡萄酒数据的DataFrame对象。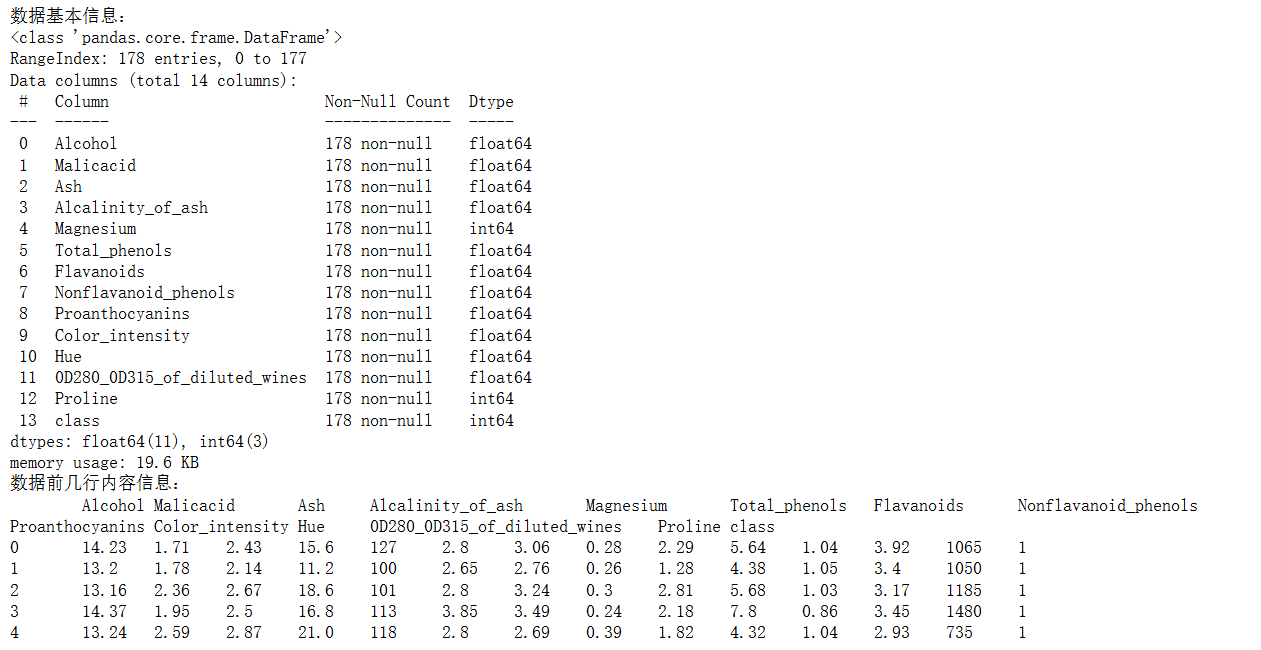
(2)将数据集以 7:3 的比例划分成训练数据集和测试数据集

从sklearn.model_selection模块导入rtain_test_split函数,用于划分数据集,使用df.drop('class', axis=1)将class列从df中删除,剩余的列作为特征变量,赋值给X,使用df['class']选取class列作为目标变量,赋值给y,使用train_test_split函数将特征变量X和目标变量y按照 7:3 的比例划分为训练集和测试集。其中,test_size=0.3表示测试集占比 30%,random_state=42用于设置随机种子,保证每次划分结果的一致性。划分后的训练集特征变量、测试集特征变量、训练集目标变量和测试集目标变量分别赋值给X_train、X_test、y_train和y_test。
(3)调用 KNN、决策树、支持向量机、逻辑回归四个机器学习算法,对数据进行训练及预测。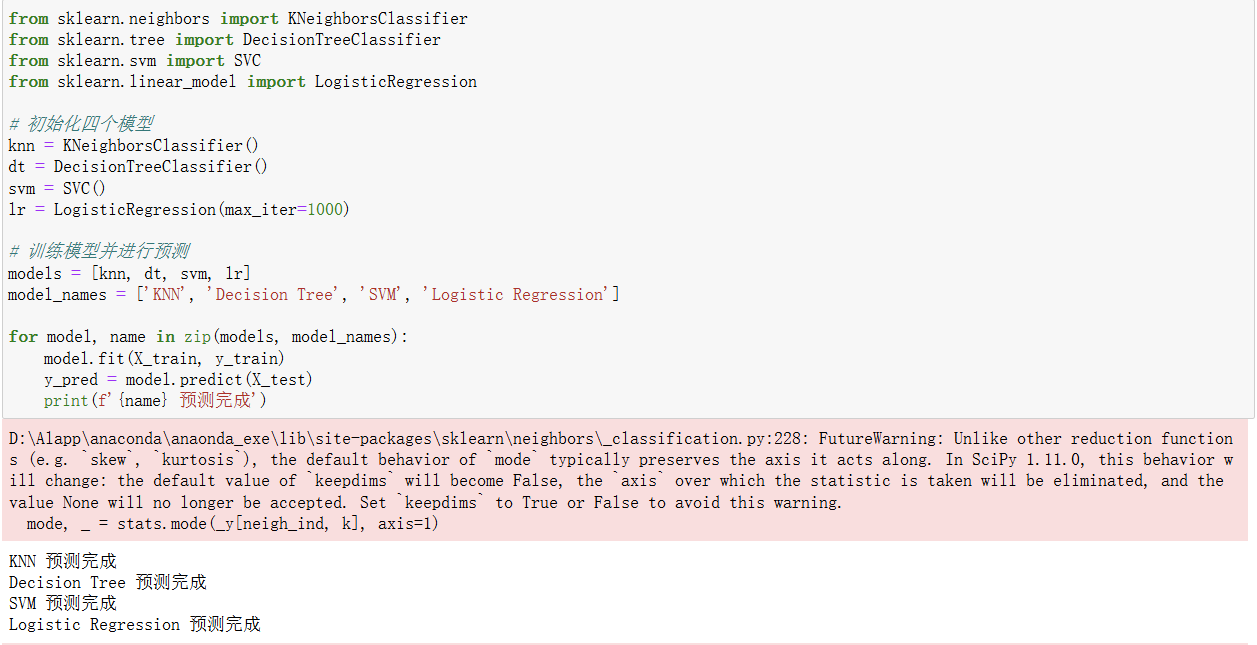
导入KNeighborsClassifier、DecisionTreeClassifier、SVC、LogisticRegression。在分别创建了 KNN、决策树、支持向量机和逻辑回归四个模型的实例。对于LogisticRegression,设置了max_iter=1000,这是为了指定最大迭代次数,防止算法在无法收敛时陷入无限循环。
将四个模型实例存储在列表models中,同时将对应的模型名称存储在列表model_names中。
使用zip函数将models和model_names进行配对,通过for循环依次对每个模型进行操作。
model.fit(X_train, y_train):使用训练集的特征变量X_train和目标变量y_train对当前模型进行训练,让模型学习数据中的模式和规律。
model.predict(X_test):使用训练好的模型对测试集的特征变量X_test进行预测,得到预测结果y_pred。
print(f'{name} 预测完成'):打印出当前模型的名称和预测完成的信息,方便用户了解每个模型的执行进度。
(4)分别对不同机器学习算法预测的结果绘制混淆矩阵和分类报告矩阵
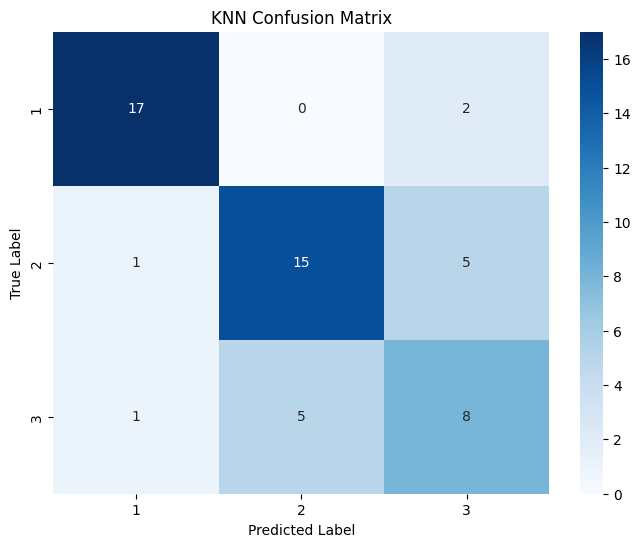
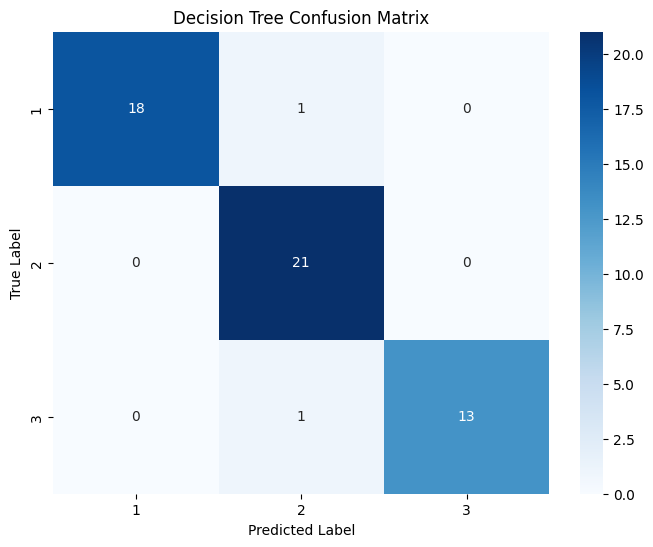
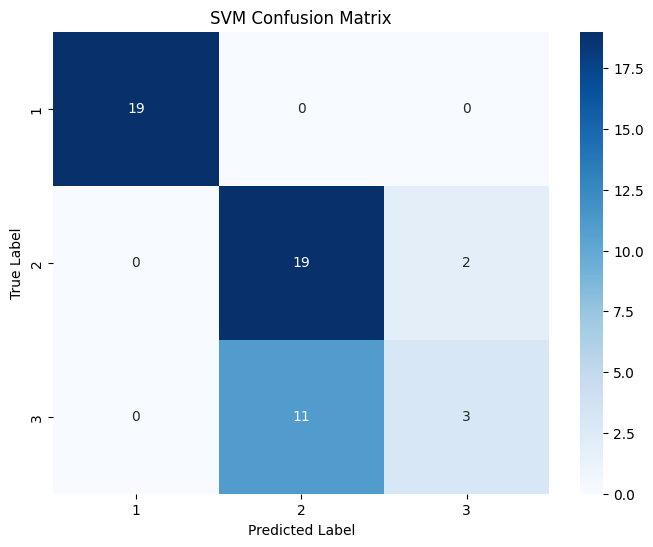
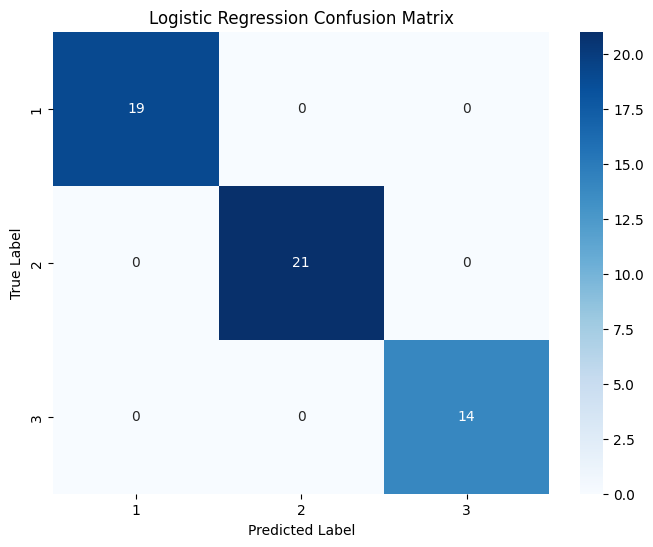
4 个混淆矩阵对比显示:逻辑回归在各类别预测中均无错分,表现最佳;决策树除将 1 个类别 3 样本错分到类别 2 外,对类别 1 和 2 预测准确;SVM 对类别 1 预测良好,但将大量类别 3 样本错分到类别 2;KNN 在各类别均存在较多错分情况,对类别区分能力相对较弱。
六、实验过程问题总结
(1)问题 1:特征未标准化导致模型性能偏差
问题描述:KNN 和 SVM 表现显著差于逻辑回归,尤其是 KNN 错分较多
问题1解决方案:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 对KNN/SVM使用标准化后的数据
knn.fit(X_train_scaled, y_train)
svm.fit(X_train_scaled, y_train)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









