







一、实验目的
(1)掌握程序语言的词法结构;
(2)掌握状态转换图的使用;
(3)掌握设计词法分析程序的一般方法;
(4)学会熟练调试程序;
(5)掌握用状态转换图描述程序词法结构的一般方法,并在此基础上完成简版C语言子集词法分析程序的设计和调试运行。
二、实验内容
教材P12-2.2:一个简单的词法分析器示例
三、实验思路
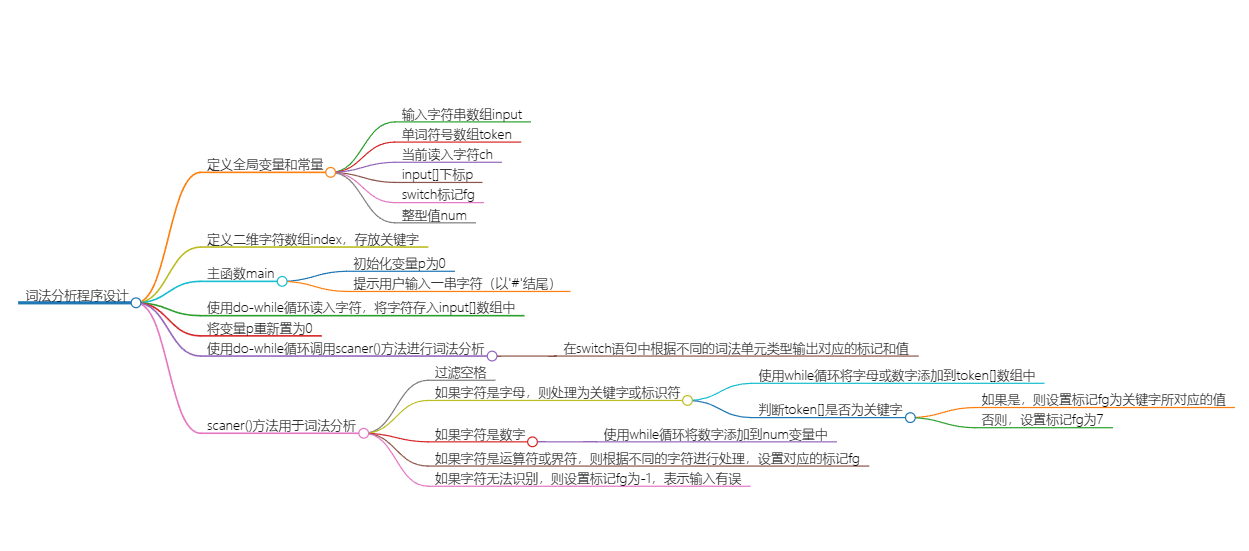
我开始定义了一些全局变量和常量,包括输入字符串数组input、单词符号数组token、当前读入字符ch、input[]下标p、switch标记fg和整型值num,然后再定义了一个二维字符数组index,用于存放关键字。在主函数main中,先初始化变量p为0,并提示用户输入一串字符(以'#'结尾);使用do-while循环读入字符,将字符存入input[]数组中;将变量p重新置为0,然后使用do-while循环调用scaner()方法进行词法分析;在switch语句中,根据不同的词法单元类型,输出对应的标记和值;scaner()方法用于词法分析,最开始需要过滤空格。
如果字符是字母,则处理为关键字或标识符,使用while循环将字母或数字添加到token[]数组中,然后判断token[]是否为关键字,如果是则设置标记fg为关键字所对应的值,否则设置标记fg为7;如果字符是数字,则使用while循环将数字添加到num变量;如果字符是运算符或界符,则根据不同的字符进行处理,设置对应的标记fg;如果字符无法识别,则设置标记fg为-1,表示输入有误。
四、编码设计
#include<stdio.h>
#include<string.h>
char input[200]; //存放输入字符串
char token[5]; //存放构成单词符号的字符串
char ch; //存放当前读入字符
int p; //input[]下标
int fg; //switch标记
int num; //存放整型值
// 二维字符数组,存放关键字
char index[7][7]={"while","if","else","switch","case"};
// 词法分析方法申明
void scaner();
int main()
{
p=0;
printf("请输入一串字符(以 '#'结尾):\n");
// 循环读入字符
do {
ch=getchar();
input[p++] = ch;
} while( ch!='#' );
p=0;
do {
scaner();
switch( fg )
{
case 8:printf("( %d,%d ) \n ", fg,num);break;
case -1:printf("输入有误\n"); break;
default:printf("( %d,%s ) ", fg, token);
}
} while( fg != 0 );
return 0;
}
/*词法分析*/
void scaner()
{
int m=0; //token[]下标
int n;
//过滤空格
ch=input[p++];
while(ch==' ') ch=input[p++];
//关键字(标识符)处理流程
if(( ch<='z' && ch>='a' )||( ch<='Z' && ch>='A' ))
{
while(( ch<='z' && ch>='a' )||( ch<='Z' && ch>='A' )||( ch<='9' && ch>='0' ))
{
token[m++] = ch;
ch = input[p++];
}
p--;
token[m++] = '\0';
fg = 7;
for( n=0; n<6; n++ )
{
if(strcmp(token, index[n])==0)// strcmp()比较两个字符串,相等返回0
{
fg = n+1;
break;
}
}
}
//数字处理流程
else if(( ch<='9' && ch>='0' ))
{
num=0;
while(( ch<='9' && ch>='0' ))
{
num = num*10+ch-'0';
ch = input[p++];
}
p--;
fg = 8;
}
//运算符界符处理流程
else
switch(ch)
{
case '<':
{
token[m++]=ch;
ch=input[p++];
if(ch=='>') //产生<>
{
fg=14;
token[m++]=ch;
}
else if(ch=='=') //产生<=
{
fg=15;
token[m++]=ch;
}
else
{
fg=13;
p--;
}
token[m++] = '\0';
break;
}
case '>':
{
token[m++]=ch;
ch=input[p++];
if(ch=='=') //产生>=
{
fg=17;
token[m++]=ch;
}
else //产生>
{
fg=16;
p--;
}
token[m++] = '\0';
break;
}
case '+': fg=9; token[0]=ch; token[1]='\0'; break;
case '-': fg=10; token[0]=ch; token[1]='\0'; break;
case '*': fg=11; token[0]=ch; token[1]='\0'; break;
case '/': fg=12; token[0]=ch; token[1]='\0'; break;
case '=': fg=18; token[0]=ch; token[1]='\0'; break;
case ';': fg=19; token[0]=ch; token[1]='\0'; break;
case '(': fg=20; token[0]=ch; token[1]='\0'; break;
case ')': fg=21; token[0]=ch; token[1]='\0'; break;
case '#': fg=0; token[0]=ch; token[1]='\0'; break;
default: fg=-1;
}
}五、实验结果
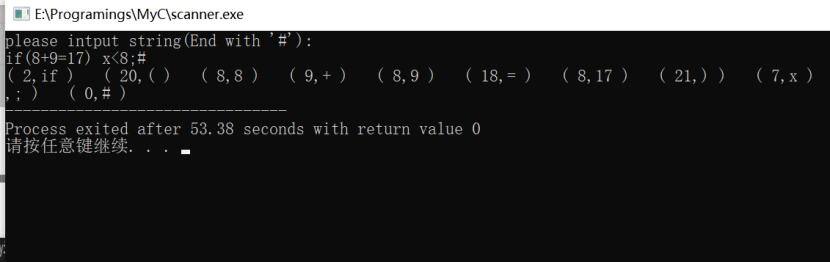
六、实验总结
通过这次实验,我学习了程序语言的词法结构和设计词法分析程序的一般方法,我也了解了词法分析器的基本原理和实现过程,并掌握使用状态转换图描述程序词法结构的方法,在实验中,我根据实验内容和给出的实验代码完成了一个简版C语言子集的词法分析程序的设计和调试运行,我按照课本上的示例,通过状态转换图的方式构建了词法分析器的状态转换表,并根据输入的字符进行相应的状态转换,在每个状态转换后,根据当前状态和输入字符的类型,输出对应的词法单元和值。
但是在调试程序中,我发现了自己的不足之处,在处理标识符时,我没有考虑到标识符的长度限制,导致可能出现溢出的情况,此外,在处理数字时,也没有对超过整型范围的数字进行错误处理;经过分析和改正,我对程序进行了修复,并重新测试了程序的运行。最终,我成功地完成了一个简版C语言子集的词法分析程序,并能够正确地输出各个词法单元和对应的值。
这次实验,我不仅加深了对程序语言词法结构和词法分析器的理解,还提高了调试程序的能力,这让我意识到在编写程序时,需要仔细考虑各种可能的输入情况,并进行相应的错误处理,我也明白了设计一个完善的词法分析程序需要考虑更多的细节和特殊情况。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









