






OpenAI 推出的 GPT-Image-1 标志着生成式 AI 正式跨入全模态时代。这个突破性模型不仅让文字与图像实现双向理解,更通过 API 生态构建起产业联动的桥梁。本文将从技术突破、应用革新与未来图景三个维度,揭示这场生产力革命的深层逻辑。
一、技术内核:四大维度重构创作范式
1. 语义黑洞吞噬者
模型对"在哥特式城堡顶楼,穿洛丽塔裙的机械姬凝望雨夜霓虹"这类复杂描述展现出惊人的解析力,能精准识别主体特征(机械姬)、场景要素(哥特城堡)、氛围符号(雨夜霓虹)及风格指向(赛博朋克美学),实现思维导图式创作。
2. 像素级外科手术刀
当用户上传设计草图并标注"将维多利亚式裙撑改为量子光效材质",模型能在保持人体结构合理性的前提下,对服装进行亚毫米级改造,甚至自动补全光影反射逻辑,展现超越传统PS的智能编辑能力。
3. 文字渲染革命者
生成"蒸汽朋克主题咖啡店促销海报"时,模型不仅准确呈现齿轮与黄铜元素,更能将促销文案"第二杯半价"以符合蒸汽朋克美学的机械字体自然融入场景,解决困扰行业多年的图文割裂难题。
4. 风格变形金刚
从《权游》级别的史诗级战场到宫崎骏风格的天空之城,模型通过风格向量解耦技术实现画风切换。测试中生成《戴珍珠耳环的少女》赛博格版本时,在保留原画光影精髓的同时,机械义眼与仿生皮肤呈现令人惊叹的艺术平衡。
二、应用生态:从对话彩蛋到产业基座
ChatGPT 的场景试炼场
在对话界面输入"帮我的宠物狗设计成星际海盗,要有机械义肢和全息眼罩",5秒内即可获得4K画质的概念图。这种低门槛交互虽便利,但专业工具的缺失让高阶创作受限——用户无法像Midjourney那样通过--chaos参数控制画面随机性。
API 引发的产业地震
-
Adobe生态进化论:Firefly插件中新增"语义蒙版"功能,设计师框选裙摆后输入"转换为流体金属质感",系统自动计算物理特性生成动态效果
-
Figma 生产力跃迁:UI设计师输入"生成Material Design风格的健身APP首页,突出运动数据可视化",模型直接输出分层PSD文件,设计周期压缩70%
-
ComfyUI 的无限可能:开发者将Stable Diffusion节点与GPT-Image-1串联,构建出"文字→概念图→3D模型→虚幻引擎场景"的全自动管线,游戏原型开发效率提升10倍
三、未来演进:多模态奇点临近
GPT-Image-2 的五大进化方向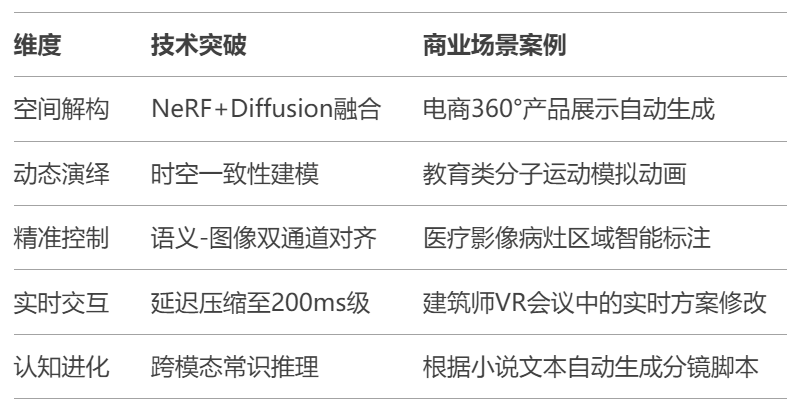
创作者的人机共生时代
当GPT-Image-2实现10毫秒级响应时,设计师的思维流将直接转化为视觉流——想象在AR眼镜中用手势勾勒创意轮廓,AI实时填充细节并给出风格建议,这种神经耦合式创作将重新定义"灵感"本身。
从GPT-Image-1到即将到来的多模态宇宙,我们正站在人机协同的奇点。当图像生成API调用成本降至每千次1美元时,95%的基础设计工作将实现自动化。这不是对人类创造力的替代,而是一场解放:让创作者从技术桎梏中解脱,真正回归价值创造的本质。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









