






import re
import os
import time
from bs4 import BeautifulSoup
from DrissionPage import ChromiumPage, ChromiumOptions
import subprocess
# 编码和清晰度映射表
codec_mapping = {
'f321004': ('H264', '1080'),
'f321003': ('H264', '720'),
'f321002': ('H264', '480'),
'f322016': ('HEVC', '4K'),
'f322064': ('HEVC', '1080'),
'f322063': ('HEVC', '720'),
'f322062': ('HEVC', '480')
}
# 获取脚本所在目录
script_dir = os.path.dirname(os.path.abspath(__file__))
download_dir = os.path.join(script_dir, 'txdownload')
if not os.path.exists(download_dir):
os.makedirs(download_dir)
target_url = input("请输入当前腾讯视频播放页地址(例如:https://v.qq.com/x/cover/mzcxxxxxxx/xxxxx.html): ").strip()
co = ChromiumOptions()
co.headless(False)
page = ChromiumPage(addr_or_opts=co)
page.listen.start()
print(f"[+] 正在访问: {target_url}")
page.get(target_url)
downloaded_titles = set()
is_downloaded = False
last_base_url = None
current_episode = None
waiting_for_first_ts = False # 等待第一个TS文件的标志
get_all_blacks_detected = False # 新增:是否已检测到GetAllBlacks请求
def get_page_title():
html = page.html
soup = BeautifulSoup(html, 'html.parser')
title_tag = soup.find('title')
if title_tag:
raw_title = title_tag.text.strip()
parts = raw_title.split('_', 2)
return f"{parts[0]}_{parts[1]}" if len(parts) >= 2 else parts[0]
return "未命名视频"
def get_current_episode():
html = page.html
soup = BeautifulSoup(html, 'html.parser')
# 更全面的集数选择器,适应腾讯视频的不同页面布局
episode_selectors = [
'div.episode-list a.current', # 常见选择器1
'div.mod_episode li.current', # 常见选择器2
'div.episode-item.active', # 常见选择器3
'a.episode-item.current' # 常见选择器4
]
for selector in episode_selectors:
episode_element = soup.select_one(selector)
if episode_element:
return episode_element.get('title', '').strip() or episode_element.text.strip()
return None
def process_ts_url(ts_url):
match = re.search(r'/(\d+_)?(gzc[^/]+\.f\d{6})\.', ts_url)
if not match:
return None
filename_part = match.group(2)
code = filename_part.split('.')[-1]
if code not in codec_mapping:
return None
codec, resolution = codec_mapping[code]
protocol = ts_url.split('://')[0]
domain_part = ts_url.split('//')[1].split('/')[0]
path_parts = ts_url.split('//')[1].split('/')[1:-1]
m3u8_url = f"{protocol}://{domain_part}/{'/'.join(path_parts)}/{filename_part}.ts.m3u8?ver=4"
return m3u8_url, codec, resolution
def get_base_url():
url = page.url
return url.rsplit('.', 1)[0] if url.endswith('.html') else url
try:
print("已进入自动监听模式,将持续捕获符合条件的ts文件...")
print("请在浏览器中手动点击播放按钮,开始视频加载...")
while True:
current_base_url = get_base_url()
new_episode = get_current_episode()
if last_base_url is None:
last_base_url = current_base_url
if current_episode is None:
current_episode = new_episode
# 检查是否切换了集数
if new_episode and new_episode != current_episode:
print(f"[!] 检测到集数已切换")
current_episode = new_episode
is_downloaded = False
last_base_url = current_base_url
waiting_for_first_ts = True # 开始等待第一个TS文件
get_all_blacks_detected = False # 重置GetAllBlacks检测标志
print("[+] 等待新集数的GetAllBlacks请求和第一个TS文件...")
continue
if is_downloaded:
if current_base_url != last_base_url:
print("[!] 检测到播放页已更换,等待5秒缓冲加载...")
time.sleep(5)
last_base_url = current_base_url
current_episode = get_current_episode()
is_downloaded = False
waiting_for_first_ts = True
get_all_blacks_detected = False
else:
print("[!] 当前视频已下载,请切换新播放页或退出程序。")
time.sleep(3)
continue
# 开始监听网络请求
for packet in page.listen.steps():
# 如果正在等待第一个TS文件
if waiting_for_first_ts:
# 先检测GetAllBlacks请求
if 'GetAllBlacks' in packet.url and not get_all_blacks_detected:
print("[+] 已检测到集数切换后的GetAllBlacks请求,等待第一个TS文件...")
get_all_blacks_detected = True
continue
# 只有已经检测到GetAllBlacks请求后,才处理第一个TS文件
if get_all_blacks_detected and '.ts' in packet.url and 'gzc' in packet.url:
print("[+] 检测到新集数的第一个TS文件请求")
waiting_for_first_ts = False
get_all_blacks_detected = False
# 继续处理这个TS文件
else:
continue
else:
# 正常模式下只处理TS文件
if not ('.ts' in packet.url and 'gzc' in packet.url):
continue
result = process_ts_url(packet.url)
if not result:
continue
m3u8_url, codec, resolution = result
current_title = get_page_title()
if current_episode:
current_title = f"{current_title}_{current_episode}"
print(f"[TS 文件请求]: {packet.url}")
print(f"[M3U8 链接生成]: {m3u8_url}")
print(f" ├─ 编码格式: {codec}")
print(f" └─ 清晰度: {resolution}")
if current_title in downloaded_titles:
print(f"[!] 标题 '{current_title}' 已下载过,停止监听...")
is_downloaded = True
break
choice = input(f"[?] 是否下载 '{current_title}'?(y/n): ").strip().lower()
if choice == 'y':
command = [
'N_m3u8DL-RE.exe',
m3u8_url,
'--save-name', current_title,
'--tmp-dir', download_dir,
'--save-dir', download_dir
]
print("[+] 正在调用N_m3u8DL-RE下载器...")
try:
subprocess.run(command, check=True)
print("[+] 视频下载完成!")
downloaded_titles.add(current_title)
is_downloaded = True
except subprocess.CalledProcessError as e:
print(f"[-] 下载失败: {e}")
elif choice == 'n':
print("[!] 已跳过该视频。")
is_downloaded = True
else:
print("[!] 输入无效,跳过本次操作。")
is_downloaded = True
time.sleep(1)
except KeyboardInterrupt:
print("\n用户中断监听。")
finally:
page.quit() print("[+] 浏览器已关闭。")成品示意图
基于ts改造m3u8原理进行监听ts文件的请求地址并修改成M3U8地址,后调用m3u8DL-RE下载器进行下载:原理如下
TS分片请求
https://defaultts.tc.qq.com/vipts.tc.qq.com/A1V3juazeTbzm0BnbB3yuBWzRPq6N_Xea19LacsVUXrQ/B_-zZfQ0GV5vY5IDrVDPNMQV3Ogj2422QtEwqDuljZ-V8m1EQ8Fz6MOJflt66DEl3utoWhXuni2lEa0UPqYzEjXOui4HKqLNk41Mbfszl3vJrd8fzaK9biyWyembtmTMP4exoA9ovWzgnKTvwo-rkq0w/svp_50112/b0xGpQp9lzQSM81mIIiD8KSR9bcJjHUbvooSEzE50F2TKOdBhywHN4u6mLtZBKBBplMhwETT0Ev0s7toJTiZ4bkBfbYmmuPNdcsP1lwdkjZR0xAVwu_yyUEYkNFDvlQiJ5Nf44-O6GfGkgHxeG_1CEkV5jUm9jpiyOaJWpjkDzR7wELeoHp29zNIKLTdhGd_UZbs_nkk_sXsQnKeXYyPMEd4bRoTPWnwszKo33CKl3c/019_gzc_1000102_0b5324breaadjaaiw2h2tzt4hv6dcliqgfsa.f322016.1.ts.index=19&start=215160&end=227080&brs=128842604&bre=135090595&ver=4&token=7e0ffa514c48c7422108f392092f781b
改:
https://defaultts.tc.qq.com/vipts.tc.qq.com/A1V3juazeTbzm0BnbB3yuBWzRPq6N_Xea19LacsVUXrQ/B_-zZfQ0GV5vY5IDrVDPNMQV3Ogj2422QtEwqDuljZ-V8m1EQ8Fz6MOJflt66DEl3utoWhXuni2lEa0UPqYzEjXOui4HKqLNk41Mbfszl3vJrd8fzaK9biyWyembtmTMP4exoA9ovWzgnKTvwo-rkq0w/svp_50112/b0xGpQp9lzQSM81mIIiD8KSR9bcJjHUbvooSEzE50F2TKOdBhywHN4u6mLtZBKBBplMhwETT0Ev0s7toJTiZ4bkBfbYmmuPNdcsP1lwdkjZR0xAVwu_yyUEYkNFDvlQiJ5Nf44-O6GfGkgHxeG_1CEkV5jUm9jpiyOaJWpjkDzR7wELeoHp29zNIKLTdhGd_UZbs_nkk_sXsQnKeXYyPMEd4bRoTPWnwszKo33CKl3c/gzc_1000102_0b5324breaadjaaiw2h2tzt4hv6dcliqgfsa.f322016.ts.m3u8?ver=4
红色部分为要修改的,亲测有效。0x0_gzc这种开头的TS分片
运行环境:Win10、Win11(win7用户可自行搞python环境自己打包,把N_m3u8DL-RE.exe和ffmpeg.exe置于脚本相同目录下)
该软件基于谷歌进行监听
需先安装谷歌浏览器!!!(尽量最新,测试环境 谷歌正式版136.0.7103.114)
注:超前,付费,加密视频均不支持!!!!
已修复2.0切换集数下载重复问题,内附下载教程
下载前奏:
第一次先在浏览器上登录账号,选择最高清晰度,关闭浏览器和程序
第二次再重新打开,粘贴某个集数的视频链接
可以对该页面的所有相关视频进行监听下载!
视频自动保存在txdownload文件夹里
tx_2.1.exe为本体环境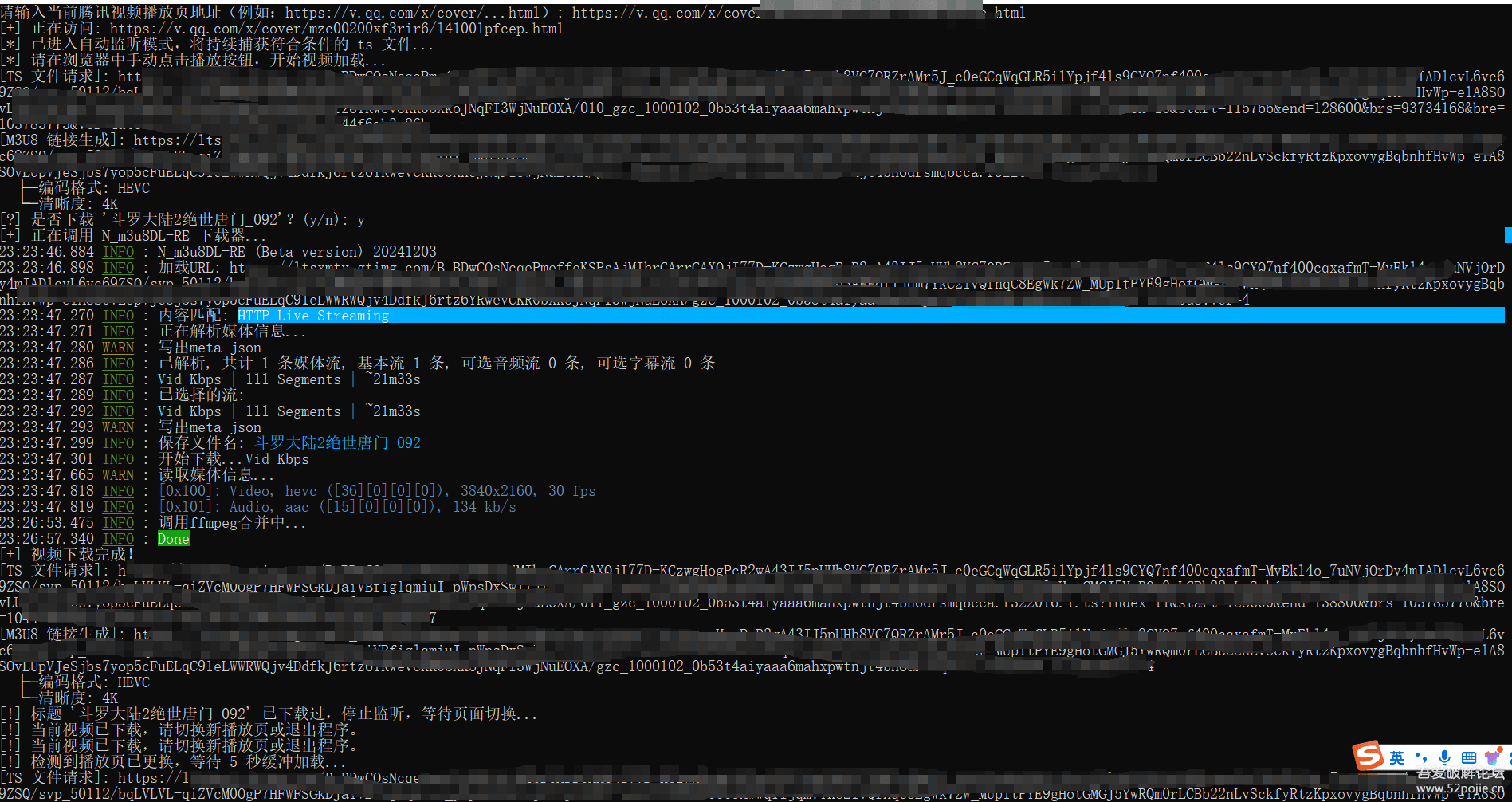
下载链接:夸克网盘分享

















 1218
1218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









