






📌 为什么要自己写脚本?
很多人都遇到过这种情况:想找一部电影、电视剧或者动漫,结果到处都是“要充值”“片源失效”“广告重重”。
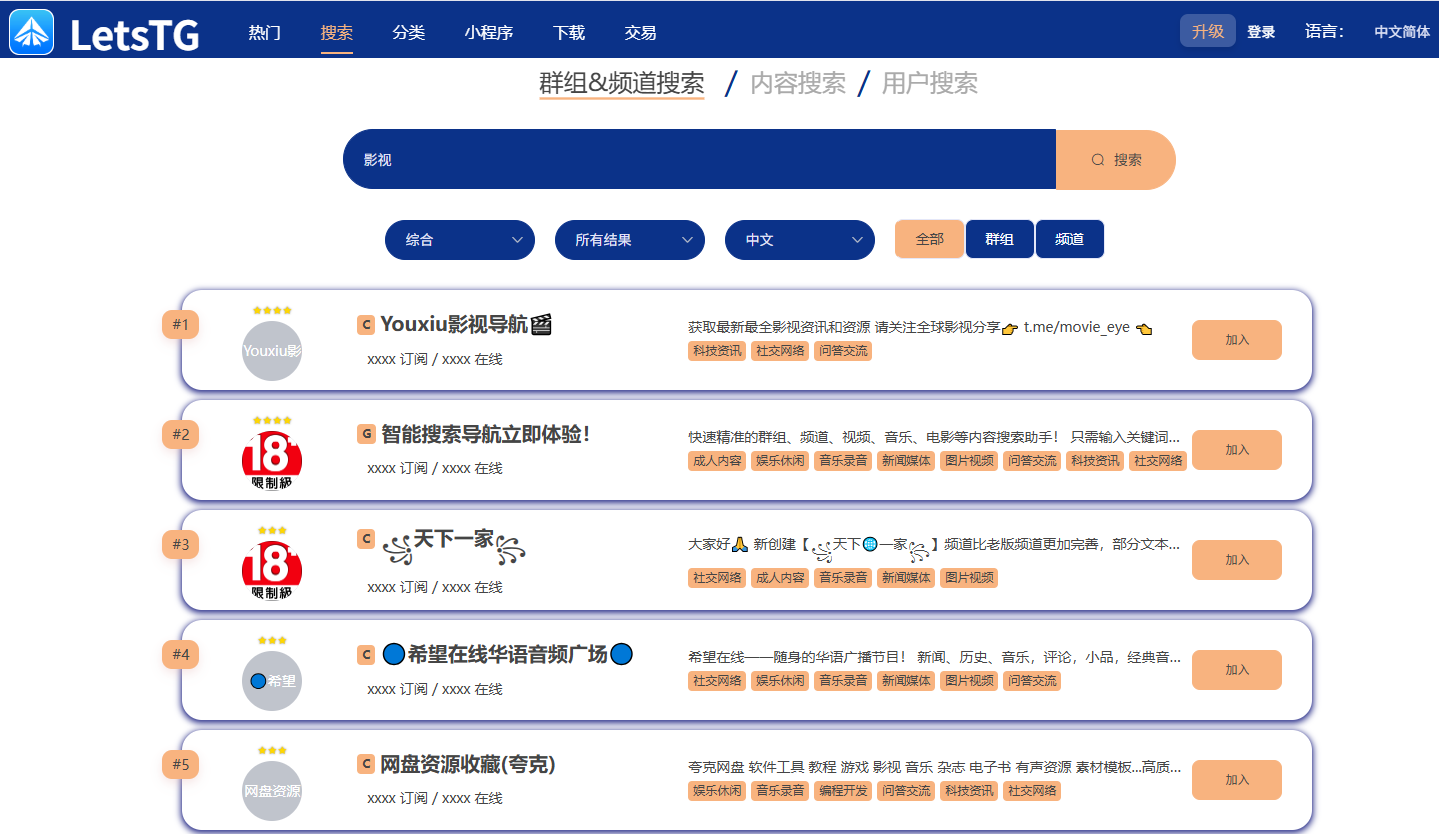
其实,Telegram 上有很多影视资源分享频道和群组,但普通搜索功能很难找到中文内容。于是我尝试写了一个 Python 脚本,自动通过机器人接口搜索群/频道,快速收集影视资源。
这里我用到的就是 @letstgbot —— 它不是影视资源站,而是一个安全的中文群/频道搜索机器人,通过它能定位到公开的影视分享社区。这样一来,既避免了乱七八糟的虚假网站,又能更高效地找到资源。
🔎 搜索逻辑
你输入一个关键词(比如 “电影”/“韩剧”/“动漫”)
脚本会自动把关键词发给 @letstgbot
从机器人返回的消息里提取群/频道链接
把结果保存到本地 JSON/SQLite,甚至还能生成 HTML 导航页
🐍 Python 全脚本(影视搜索版)
# -*- coding: utf-8 -*- """ 2025 免费影视搜索脚本 通过 @letstgbot 搜索 Telegram 中文影视群/频道 功能: 1. 关键词搜索(电影、电视剧、动漫等) 2. 提取群组/频道链接 3. 保存 JSON / SQLite 4. 导出 HTML 导航页 """ import asyncio, os, re, json, sqlite3 from datetime import datetime from telethon import TelegramClient, events # ========== 配置 ========== API_ID = int(os.getenv("API_ID", "123456")) # 替换成你的 API_ID API_HASH = os.getenv("API_HASH", "your_api_hash") # 替换成你的 API_HASH BOT = "letstgbot" # 官方搜索机器人 DB_FILE = "movies.db" JSON_FILE = "movies.json" # ========== 初始化 ========== client = TelegramClient("movie_session", API_ID, API_HASH) def init_db(): conn = sqlite3.connect(DB_FILE) c = conn.cursor() c.execute("""CREATE TABLE IF NOT EXISTS movies ( id INTEGER PRIMARY KEY AUTOINCREMENT, keyword TEXT, link TEXT UNIQUE, created_at TEXT )""") conn.commit() conn.close() def save_to_db(keyword, links): conn = sqlite3.connect(DB_FILE) c = conn.cursor() for link in links: try: c.execute("INSERT OR IGNORE INTO movies (keyword, link, created_at) VALUES (?, ?, ?)", (keyword, link, datetime.now().isoformat())) except Exception as e: print("DB error:", e) conn.commit() conn.close() def save_to_json(keyword, links): data = {"keyword": keyword, "results": links, "time": datetime.now().isoformat()} if not os.path.exists(JSON_FILE): with open(JSON_FILE, "w", encoding="utf-8") as f: json.dump([data], f, ensure_ascii=False, indent=2) else: with open(JSON_FILE, "r", encoding="utf-8") as f: old = json.load(f) old.append(data) with open(JSON_FILE, "w", encoding="utf-8") as f: json.dump(old, f, ensure_ascii=False, indent=2) # 导出 HTML 导航页 def export_html(): conn = sqlite3.connect(DB_FILE) c = conn.cursor() c.execute("SELECT keyword, link, created_at FROM movies ORDER BY created_at DESC") rows = c.fetchall() conn.close() html = "<html><head><meta charset='utf-8'><title>影视资源导航</title></head><body>" html += "<h1>Telegram 免费影视群/频道导航</h1><ul>" for kw, link, ts in rows: html += f"<li>[{kw}] <a href='https://{link}' target='_blank'>{link}</a> ({ts})</li>" html += "</ul></body></html>" with open("movies.html", "w", encoding="utf-8") as f: f.write(html) print("已导出 movies.html") # 搜索逻辑 async def search(keyword="电影", timeout=10): await client.start() bot = await client.get_entity(BOT) await client.send_message(bot, keyword) results = [] @client.on(events.NewMessage(from_users=bot)) async def handler(event): text = event.raw_text links = re.findall(r"(t.me/\S+)", text) results.extend(links) await asyncio.sleep(timeout) results = list(set(results)) print(f"\n关键词:{keyword} 共找到 {len(results)} 条结果") for i, link in enumerate(results, 1): print(f"{i}. {link}") save_to_db(keyword, results) save_to_json(keyword, results) return results # 批量搜索 async def batch_search(keywords): for kw in keywords: await search(kw) await asyncio.sleep(3) export_html() if __name__ == "__main__": init_db() keywords = ["电影", "电视剧", "动漫", "综艺", "美剧", "韩剧"] with client: client.loop.run_until_complete(batch_search(keywords))
⚡ 使用方法
安装依赖:
pip install telethon配置
API_ID&API_HASH
获取方式:登录 my.telegram.org → API Development运行脚本:
python movie_search.py结果存储:
movies.db→ SQLite 数据库
movies.json→ JSON 文件
movies.html→ 静态网页(可直接打开浏览器浏览导航)

















 1549
1549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









