






第二问
问题二:请根据气象学或物候学的知识,建立杏花、油菜花、杜鹃花、樱花、牡丹中2-3种代表性花卉在2026年的开放时间、花期等预报模型,预判春花何时开,为赏花加一道“科技保险”。
问题注意:
摘要第三段有提到从南到北的花期开放时间并不是统一的,评委老师并不会要求我们对每个城市做预测因为难度很大,问题三、问题四都提到给城市做攻略和做报告,也就是说问题二、三、四是一个连锁题,我们需要在问题二就要决定我们要预测分析的城市,之后才接连分析后面的问题,故我们随机选择“西安”(可以自己选择别的城市)作为我们的预测城市。
问题解答:
第二问问的是预判春花何时开,为赏花加一道“科技保险”。这道题的重点是建立数学模型去预测花期,也就是说“预测”“合理”是这道题的关键点,而选择两种花去预测在时间和效率上是比较有性价比,模型可以选择线性模型多元线性回归和逐步回归去预测两种花期,花期的变量可以参考小编下方所列或者自己选择就好,之后验证模型性能,最后计算真实值与预测值误差就好。
- 选择模型:
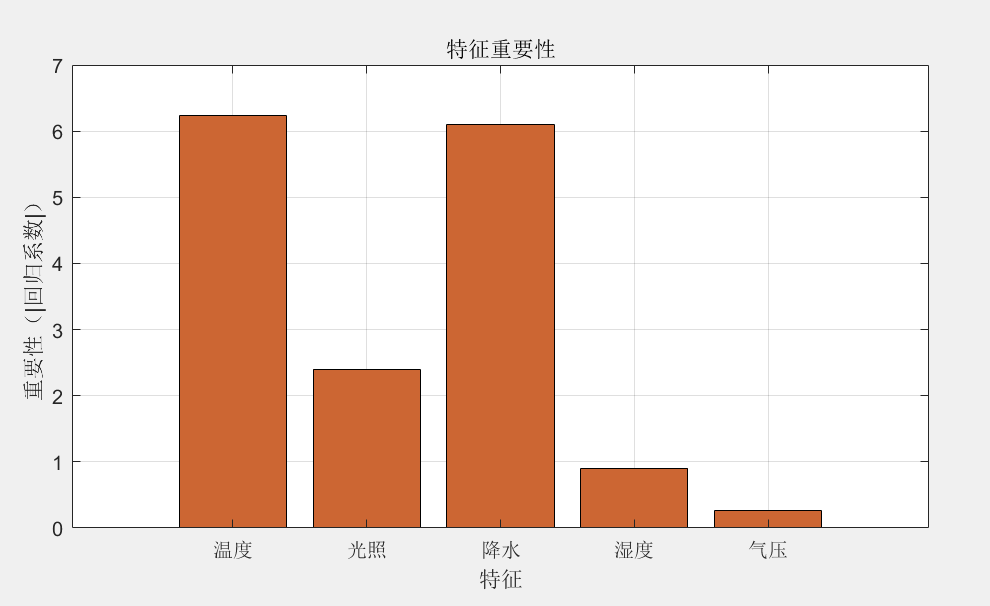
选择花卉:咱选杏花和油菜花当代表花卉。它们在清明时节比较常见。收集花期资料:去学术论文数据库里搜,像知网、万方这些,找杏花和油菜花的花期观测资料。也可以看看权威的农业、气象网站,说不定也有相关信息。要是有条件。气象数据:还是从美国国家海洋和大气管理局(NOAA)和天气网这俩地方,收集花卉所在地区的气温、光照、降水、日照时长这些气象数据。这些数据对花期影响可大。
注意:花期收集需要花费大量的时间,各个地方的花期不同搜集难度较大,推荐去搜集当地的政府发出的信息或者文献资料。
- 数据预处理:
①处理缺失值:和第一问一样,用均值、中位数或者 K 近邻算法来补缺失的花期或者气象数据。比如花期记录里有缺失,就用其他年份同一地区的花期平均值补上。处理异常值:用Z-score方法或者孤立森林算法找出异常的数据点。要是某一年的花期特别早或者特别晚,和其他年份差太多,就看看是不是数据记录错了,是的话就修正或者删掉。数据标准化:把气象数据标准化,让不同的气象要素在一个可比的范围内。用公式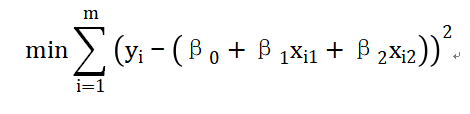
,x 是原始数据,μ是均值,σ是标准差。
- 建立花期预报模型
①杏花花期模型:考虑到杏花花期和前期气温关系大,我们选择基于气温累积效应的线性回归模型。确定变量:设杏花始花期是 Y,前期 n 天的平均气温是 X1,气温日较差是 X2 等。模型公式:Y=β0+β1X1+β2X2+ϵ。这里 β0是截距项,β1、β2 是回归系数,ϵ是误差项。参数估计:用最小二乘法来估计参数。目标是让观测值和模型预测值的误差平方和最小。公式: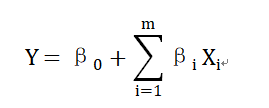
m是样本数量,yi是第 ii个样本的观测花期,xi1、xi2 是对应的自变量值。
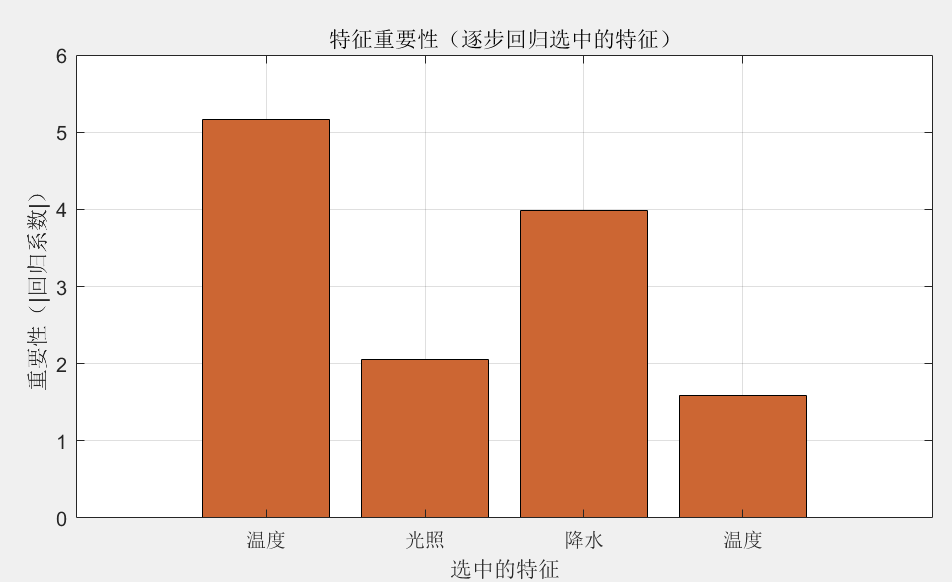
②油菜花花期模型:油菜花花期受多种气象因子影响,用多元线性回归结合逐步回归法。确定变量:设油菜花花期是 Y,不同的气象因子像气温、光照、降水等是 X1、X2等。逐步回归公式:
从一个空模型开始,每次加一个变量或者删一个变量,直到找到最优的变量组合。比如先只放一个最相关的气象因子,看看模型效果,再慢慢加其他因子,不合适的就删掉。
- 模型训练与验证
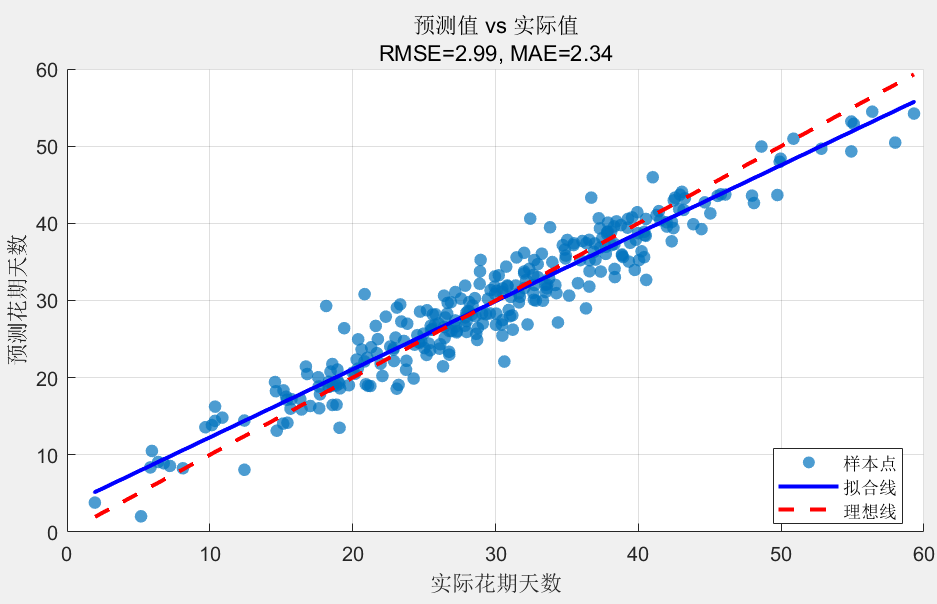
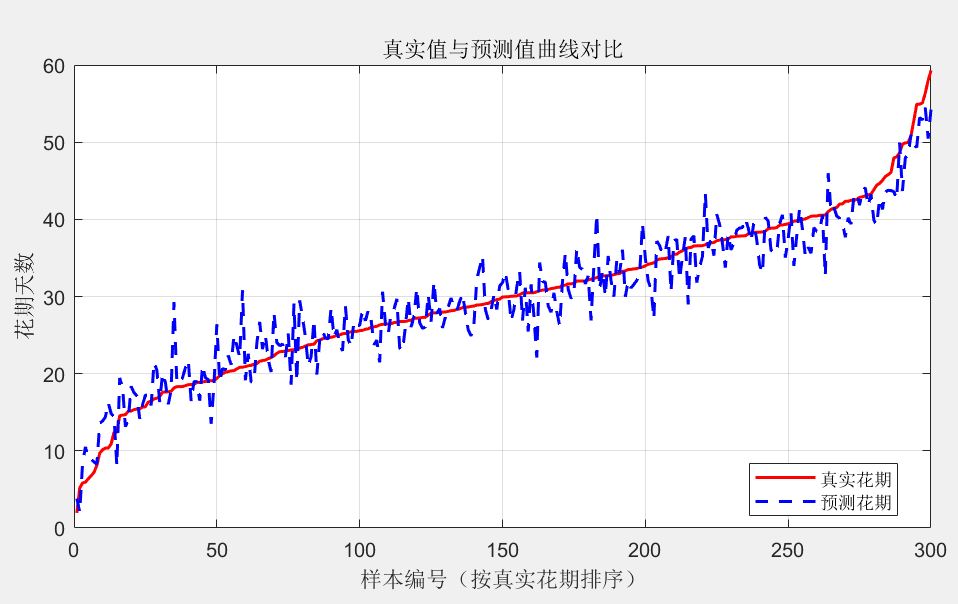
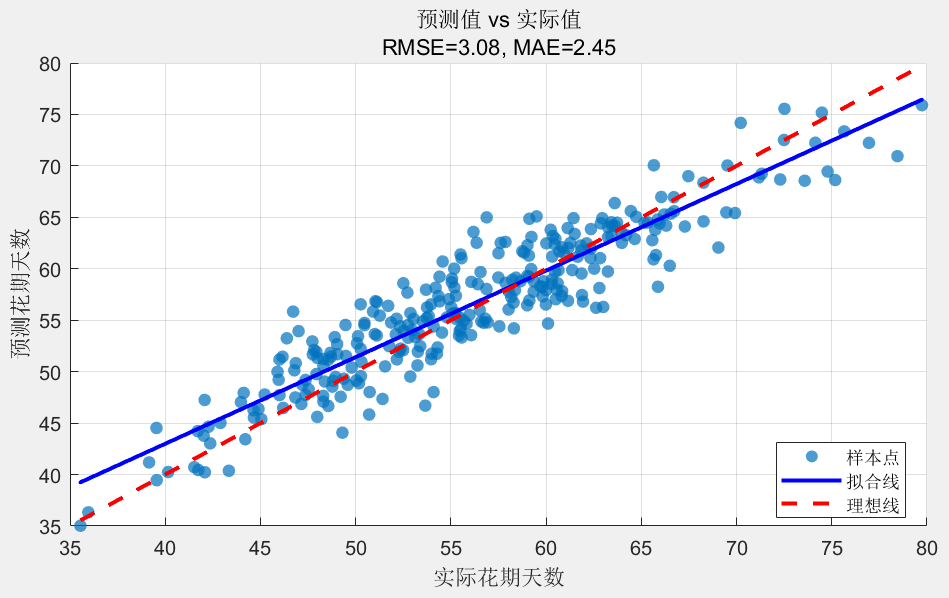
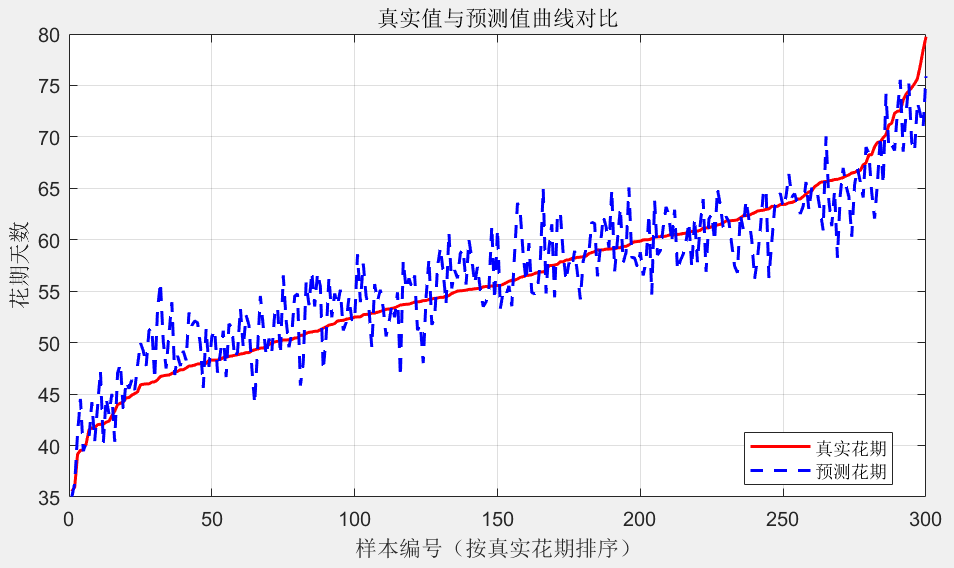
①划分数据集:把收集好的数据按 7:3 分成训练集和测试集。70% 的数据用来训练模型,让模型学习规律;30%的数据用来测试,看看模型学得咋样。模型训练:用训练集的数据来估计模型的参数。对于杏花花期模型,用最小二乘法算出 β0、β1、β2这些系数;对于油菜花花期模型,用逐步回归法确定最优的变量组合和系数。模型验证:用测试集的数据来验证模型的性能。常用的评估指标有均方根误差(RMSE)和平均绝对误差(MAE)。均方根误差:
②平均绝对误差:MAE如果误差大,说明模型不好,得调整模型结构或者增加数据量。
杏花花期模型
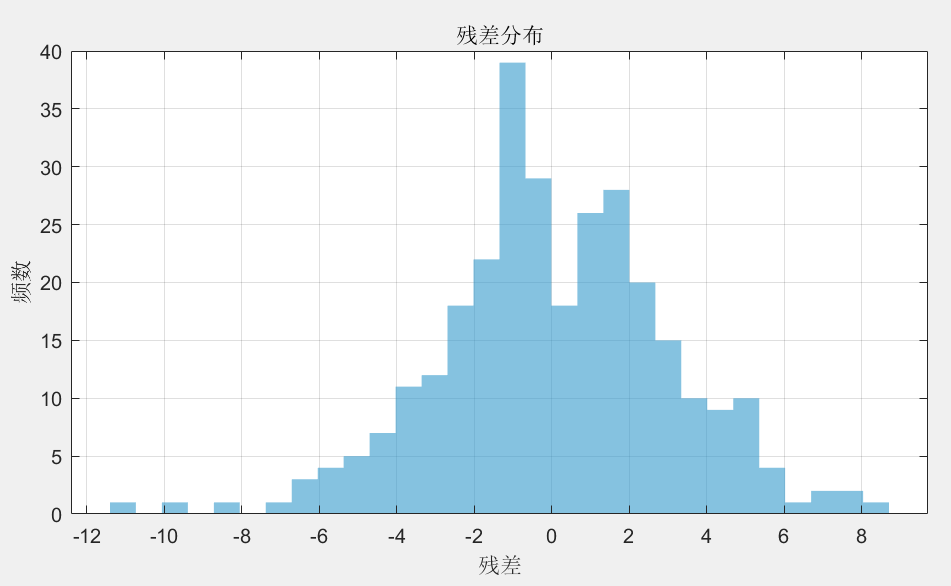
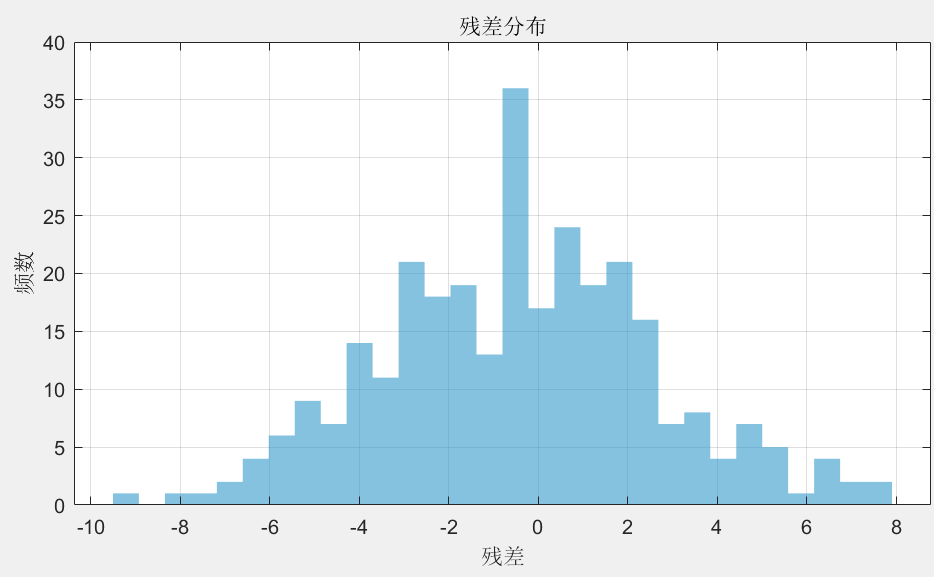
油菜花花期模型
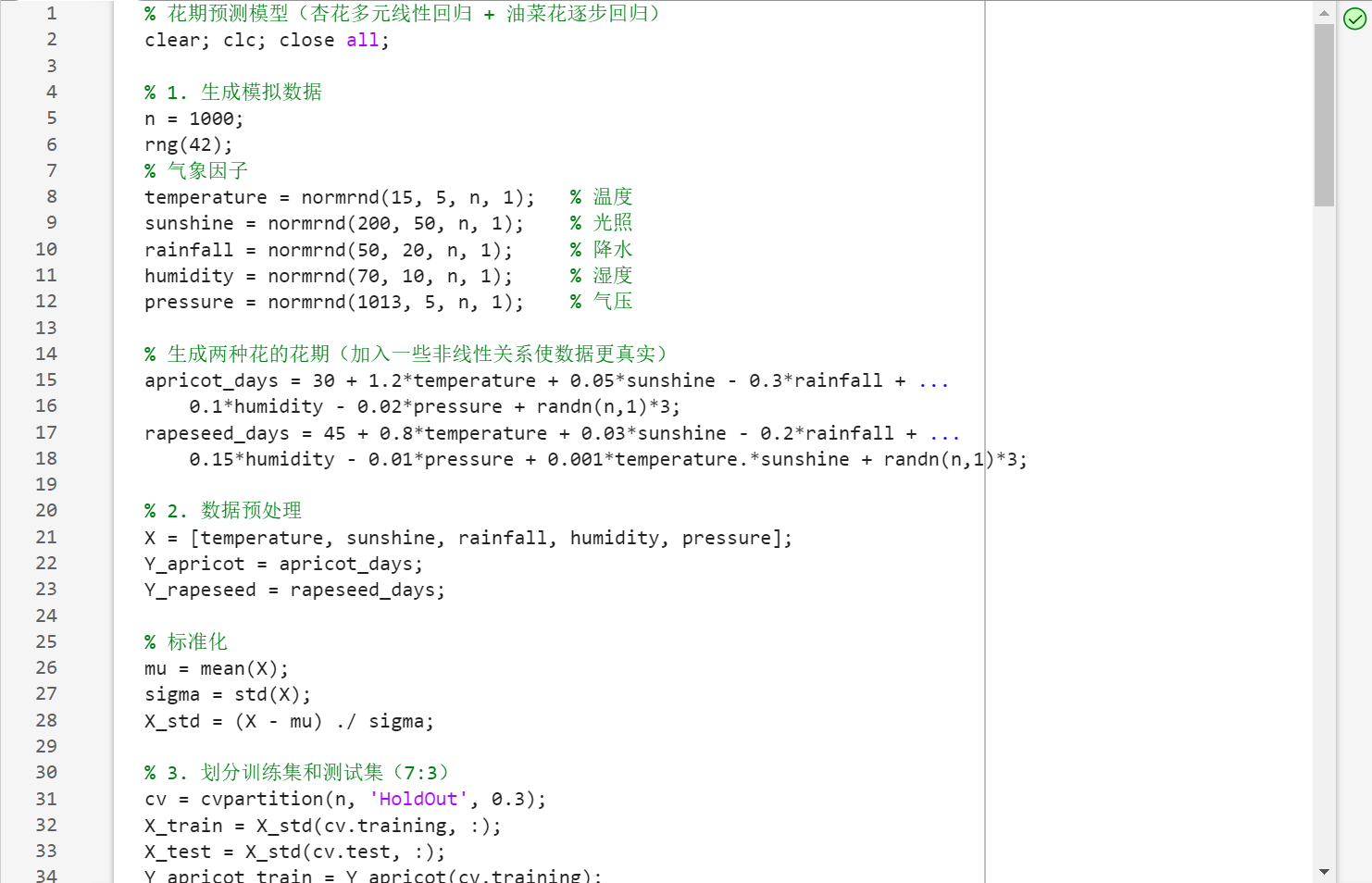
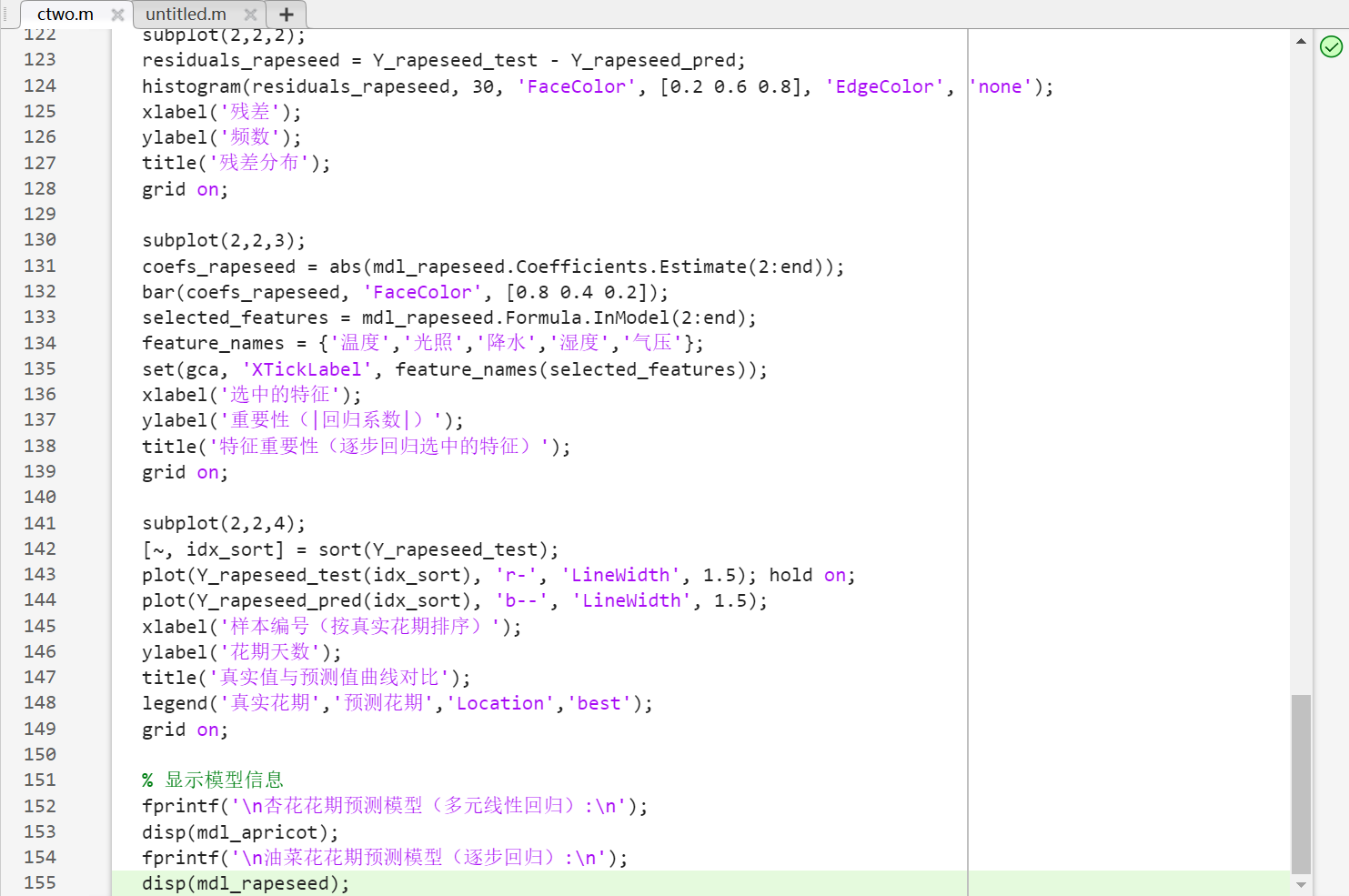
- 代码(部分)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









