






引言
作为Java开发者,Map是我们日常开发中使用最频繁的数据结构之一。但你是否真正理解各种Map实现类的底层原理?能否根据场景选择最优的Map实现?本文将深入剖析Java Map体系的核心技术点,结合源码分析、性能对比和实战案例,带你全面掌握Map的精髓。
一、Java Map体系全景图
1.1 Map接口核心实现类关系
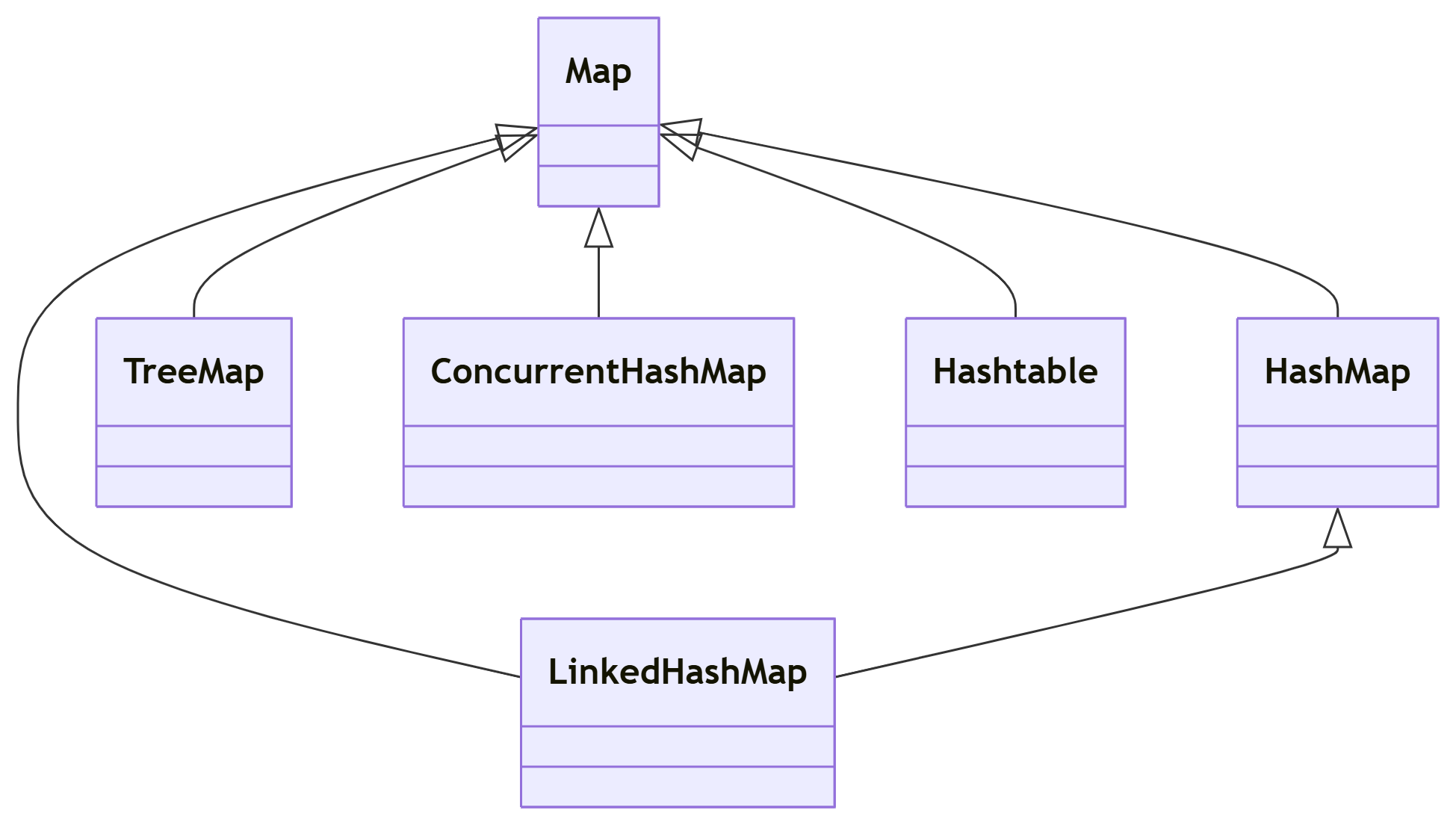
1.2 各实现类关键特性对比
| 实现类 | 数据结构 | 线程安全 | 是否有序 | 允许null | 时间复杂度 | JDK版本 |
|---|---|---|---|---|---|---|
| HashMap | 数组+链表/红黑树 | 否 | 无序 | Key/Value均可 | O(1)~O(log n) | 1.2+ |
| LinkedHashMap | 链表+哈希表 | 否 | 插入/访问顺序 | 同HashMap | O(1)~O(log n) | 1.4+ |
| TreeMap | 红黑树 | 否 | Key自然序 | Key不可 | O(log n) | 1.2+ |
| ConcurrentHashMap | 分段数组+链表/红黑树 | 是 | 无序 | Key/Value不可 | O(1)~O(log n) | 1.5+ |
| Hashtable | 数组+链表 | 是 | 无序 | Key/Value不可 | O(1) | 1.0+ |
二、HashMap深度解析
2.1 核心源码剖析(JDK8+)
// 关键字段
transient Node<K,V>[] table; // 哈希桶数组
transient int size; // 实际元素数量
int threshold; // 扩容阈值
final float loadFactor; // 负载因子(默认0.75)
// Node节点结构
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next; // 链表结构
}
// 树化节点
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // 红黑树父节点
TreeNode<K,V> left; // 左子树
TreeNode<K,V> right; // 右子树
TreeNode<K,V> prev; // 前驱节点
boolean red; // 颜色标记
}2.2 哈希扰动函数设计
static final int hash(Object key) {
int h;
// 关键点:高16位异或低16位,增加随机性
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}2.3 扩容机制详解
final Node<K,V>[] resize() {
// 旧容量翻倍
int newCap = oldCap << 1;
// 重新计算元素位置
if ((e.hash & oldCap) == 0) { // 保持原索引
newTab[j] = loHead;
} else { // 原索引+oldCap
newTab[j + oldCap] = hiHead;
}
}三、高级特性与性能优化
3.1 初始化容量优化公式
// 预期元素数量为expectedSize时,最优初始容量计算
static int optimalInitialCapacity(int expectedSize) {
if (expectedSize < 3) {
return expectedSize + 1;
}
return (int) ((float) expectedSize / 0.75f + 1.0f);
}
// 使用示例:预期存储1000个元素
Map<String, Object> map = new HashMap<>(optimalInitialCapacity(1000));3.2 树化与反树化阈值
| 操作 | 阈值 | 触发条件 |
|---|---|---|
| 树化 | 8 | 单个桶的链表长度≥8且table.length≥64 |
| 反树化 | 6 | 扩容时发现树节点数≤6 |
3.3 不同场景下的Map选择策略
// 场景1:高并发读写
Map<K,V> concurrentMap = new ConcurrentHashMap<>();
// 场景2:需要保持插入顺序
Map<K,V> orderedMap = new LinkedHashMap<>();
// 场景3:需要Key排序
Map<K,V> sortedMap = new TreeMap<>(Comparator.naturalOrder());
// 场景4:固定大小LRU缓存
Map<K,V> lruCache = new LinkedHashMap<>(16, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return size() > MAX_ENTRIES;
}
};四、并发场景下的Map实战
4.1 ConcurrentHashMap分段锁优化
// JDK8前的分段锁设计
static final class Segment<K,V> extends ReentrantLock {
transient volatile HashEntry<K,V>[] table;
}
// JDK8+的CAS优化
final V putVal(K key, V value, boolean onlyIfAbsent) {
if ((tab = table) == null) tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
// ...
}4.2 多线程Map性能对比测试
// 测试代码框架
public class MapPerformanceTest {
public static void main(String[] args) throws InterruptedException {
testMap(new HashMap<>(), "HashMap(非线程安全)");
testMap(Collections.synchronizedMap(new HashMap<>()), "SynchronizedMap");
testMap(new ConcurrentHashMap<>(), "ConcurrentHashMap");
}
static void testMap(Map<String, Integer> map, String name) {
// 并发测试逻辑...
}
}测试结果示例(8线程,100万次操作):
| Map实现 | 耗时(ms) | 吞吐量(ops/s) | 线程安全 |
|---|---|---|---|
| HashMap | 失败 | N/A | 否 |
| SynchronizedMap | 1245 | 8032 | 是 |
| ConcurrentHashMap | 678 | 14749 | 是 |
五、常见问题与解决方案
5.1 HashMap内存泄漏问题
问题场景:
public class Key {
private String id;
// 未实现equals/hashCode
}
Map<Key, String> map = new HashMap<>();
Key k1 = new Key("1001");
map.put(k1, "value1");
k1.setId("1002"); // 修改hashCode依赖字段
map.get(k1); // 返回null,但元素仍存在于map中解决方案:
-
保证Key对象不可变
-
正确实现equals和hashCode方法
5.2 重哈希导致的CPU飙升
问题现象:
-
大Map扩容时出现CPU 100%
-
服务响应变慢
优化方案:
// 1. 预分配足够容量
Map<String, Object> bigMap = new HashMap<>(1_000_000);
// 2. 使用Guava的不可变Map(避免扩容)
Map<String, Object> immutableMap = ImmutableMap.copyOf(sourceMap);六、前沿技术拓展
6.1 Java17的改进Map实现
// 新工厂方法创建不可变Map
Map<String, Integer> map = Map.of(
"one", 1,
"two", 2,
"three", 3
);
// 快速创建可修改Map
Map<String, Integer> modifiable = new HashMap<>(
Map.ofEntries(
Map.entry("one", 1),
Map.entry("two", 2)
)
);6.2 第三方优秀Map实现
-
Google Guava:
// 多值Map Multimap<String, Integer> multimap = ArrayListMultimap.create(); // 双向Map BiMap<String, Integer> biMap = HashBiMap.create(); -
Eclipse Collections:
// 原始类型特化Map IntObjectMap<String> intMap = IntObjectHashMap.newWithKeysValues(1, "one", 2, "two");
结语
通过本文的深度剖析,我们应该掌握:
-
各种Map实现类的底层数据结构与特性差异
-
HashMap的核心优化点(哈希扰动、树化、扩容)
-
高并发场景下的正确Map选型
-
实际开发中的性能优化技巧
记住:没有最好的Map实现,只有最适合场景的选择。建议在关键业务代码中,通过基准测试验证不同Map实现的性能表现。

















 1056
1056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









