







AI圈最狗血的爱情故事莫过于Google和OpenAI的狙击战了!
当今日OpenAI准备开直播宣布全量开放GPT-4o图像生成能力时,Google抢先一步,发布了Gemini 2.5 Pro Experimental。
这款模型可不是为了应付OpenAI急匆匆就推出一个模型来凑数的,它的各项能力全部拉满了。
Google 的CEO更是表示Gemini 2.5 Pro Experimental是至今为止最智能的模型,事实也的确如此。
Gemini 2.5 Pro Experimental有太多第一的成绩了,在这里就不给大家一一念。
给大家分享几个我个人比较关心的几个成绩单。
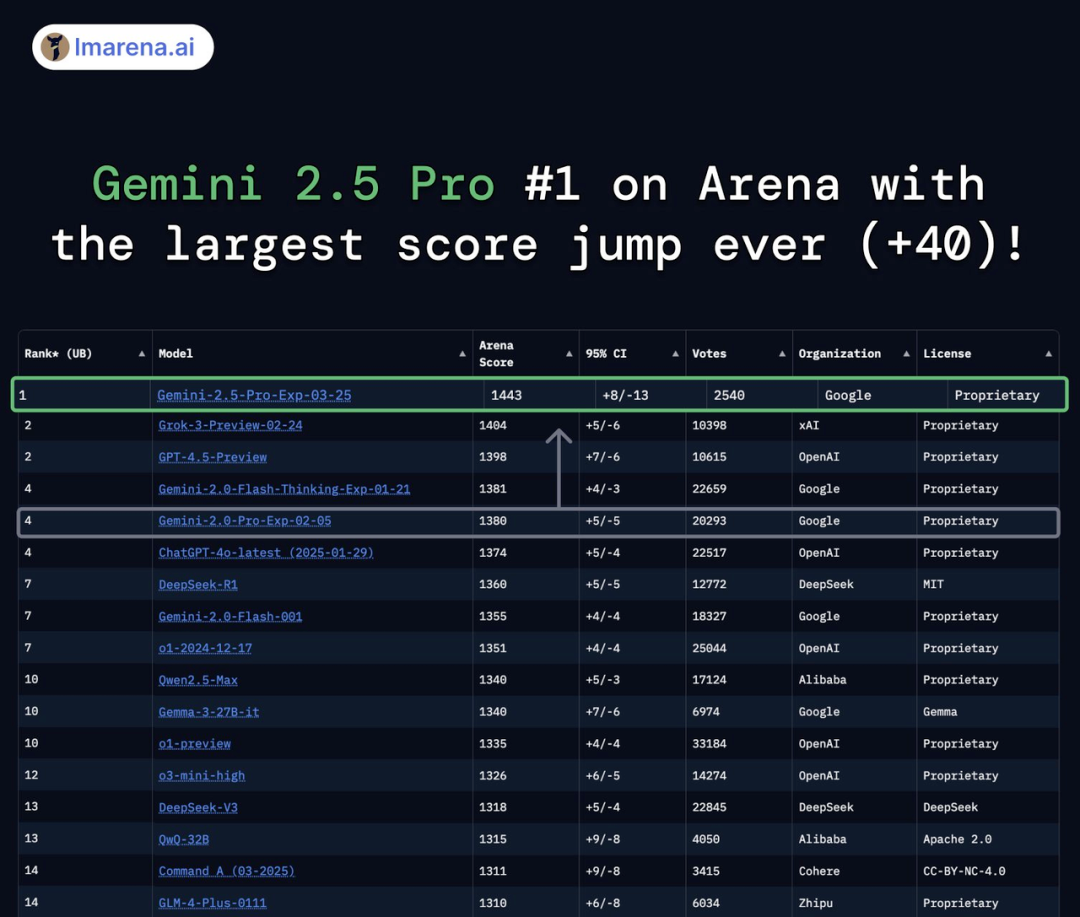
在最新的Arena排行榜中,Gemini 2.5 Pro以绝对的优势拿下第一,而且创下了历史最大分数飞跃,比Grok-3/GPT-4.5整整高出了40分!
可能还有很多小伙伴不了解Arena这个排行榜,给大家简单科普一下。
Arena 是一个由 LMSYS Org 创建的 AI 大语言模型排行榜,主要用于评估和比较不同 AI 聊天机器人的性能。
借鉴了国际象棋中的 Elo 评分机制,用户对不同模型回答同一问题的表现进行投票,获胜的模型会获得相应的分数,分数越高,模型表现越好。
换句话说,它的评分机制是采用匿名投票的方式,哪个模型回答的效果更好,它的排名就更高。
如上图所示:Gemini 2.5 Pro Experimental是现阶段的第一!
同时在网页开发领域,它也取得有史以来最好的最好成绩,超越Claude 3.5、DeepSeek R1等模型,获得网页开发竞技场(WebDev Arena)第二名的成绩。
和其他编程排行榜动不动就超越Claude 3.7,这个成绩就显得非常真实。
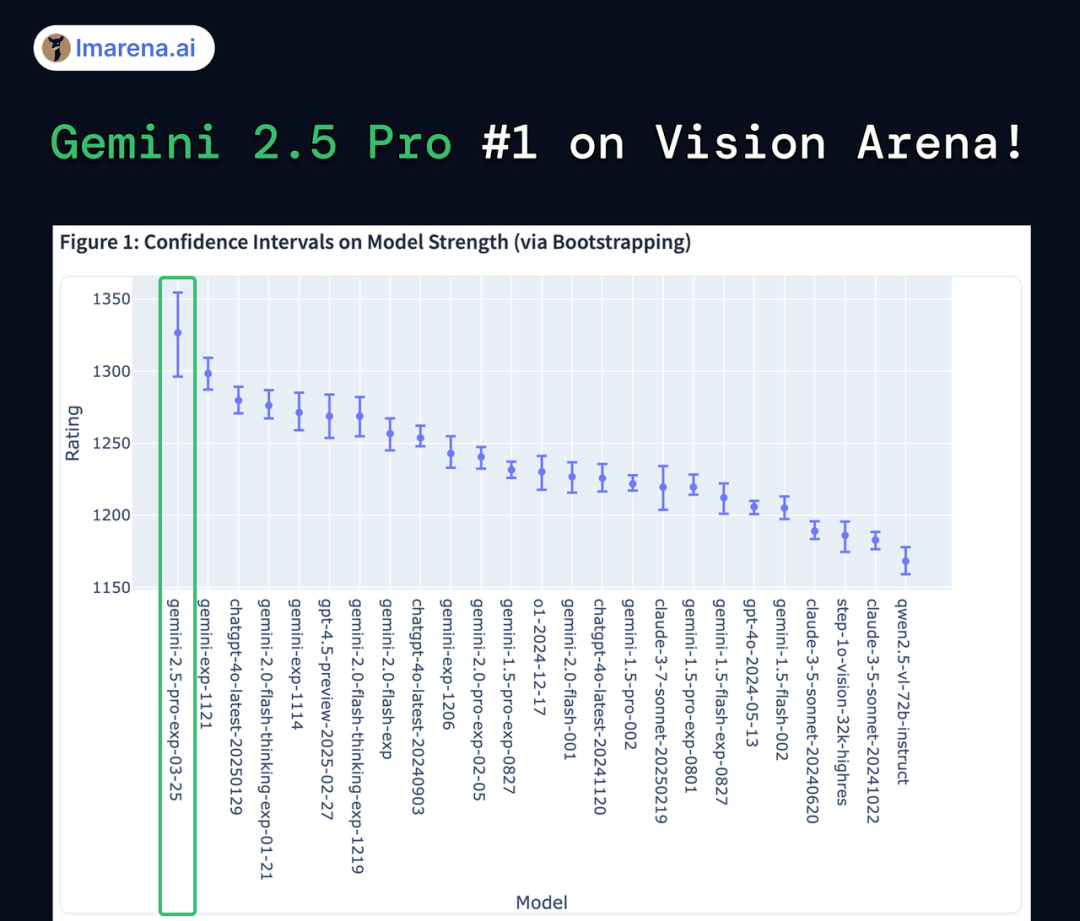
此外,Gemini 2.5 Pro Experimental还是一个多模态模型,并成功登顶了视觉竞技场(Vision Arena)排行榜榜首!
目前,Gemini 2.5 Pro已在Google AI Studio和Gemini应用中,向Gemini Advanced用户开放,并将很快在Vertex AI上推出。
附上免费使用地址:https://aistudio.google.com/prompts/new_chat
那它的实际效果到底如何?我们来测试一下,毕竟排行榜的成绩还不如测试来得实在。
让Gemini2.5编写一个 p5.js 程序,展示一个球在旋转的六边形内弹跳。球应受到重力和摩擦力的影响,并且必须真实地反弹到旋转的墙壁上,添加滑块来调整参数。
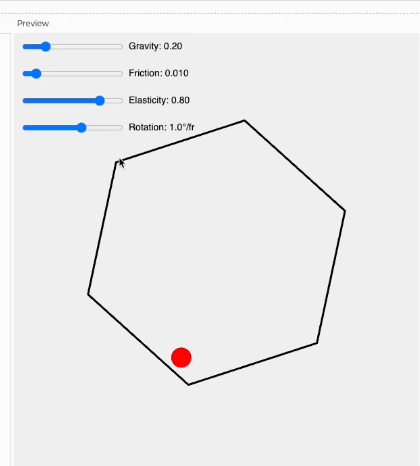
看起来是不是还不错,来一个难度高的,并它和o1 Pro对比一下,看看谁得编程能力更强。

整体而言,两个都不错,但 o1-pro 呈现的效果会更好一些,而且Gemini 2.5生成的蓝色小球掉出来了......
再来一道最近搜刮到的模型难题,之前试了一下,发现DeepSeek R1、混元 T1等模型都没有做出来,看看它们两是否可以做出来。
测试题:一根7米的棍子是否能通过长三米宽三米的门。
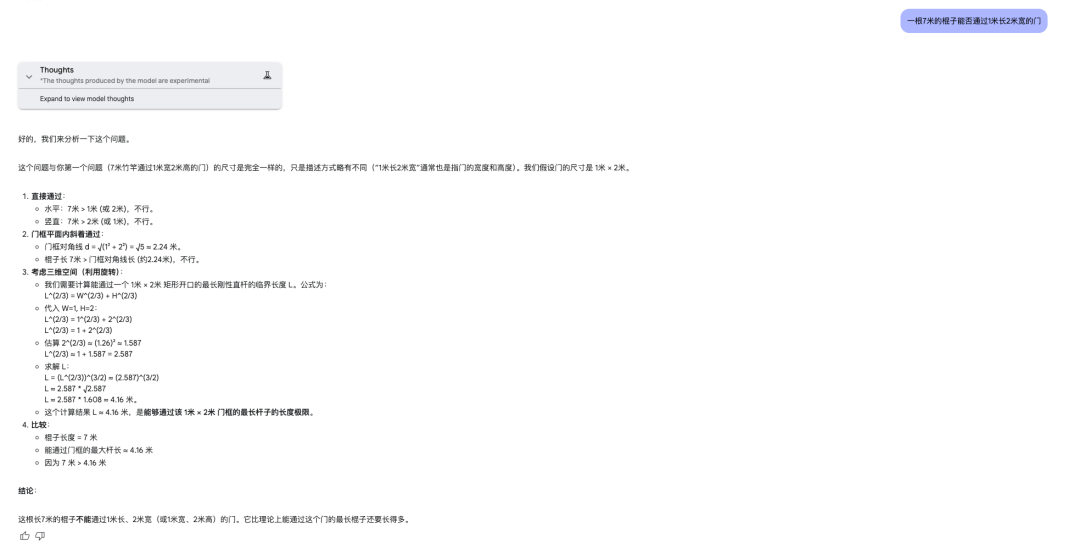
Gemini 2.5 Pro
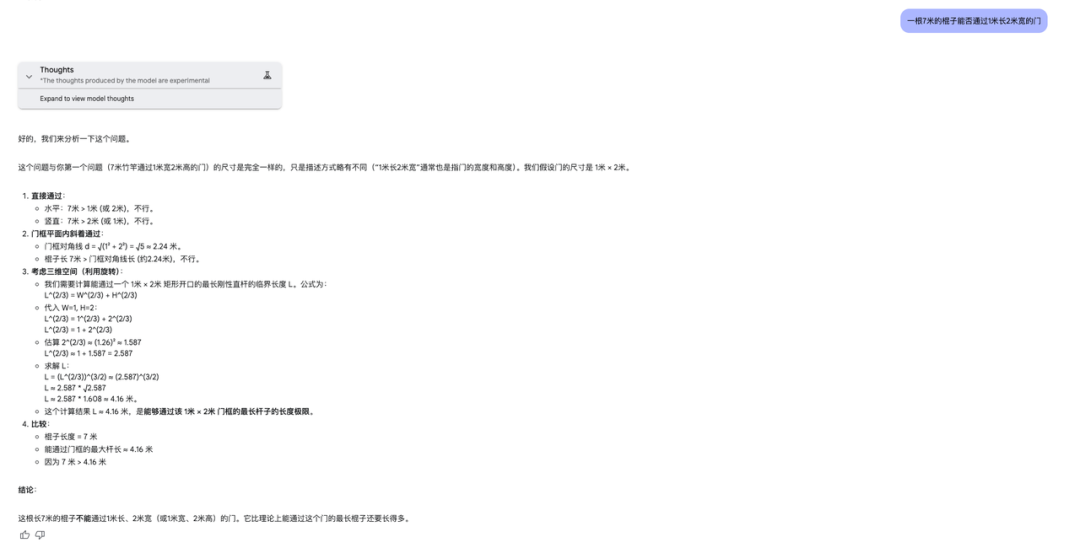
o1 Pro
这两款模型全部回答失败,仅仅只是把这道题当作是一道二维空间,而没有考虑到三维空间。
再来看看它们的数学能力如何,上传一道高三摸底考试数学题。

先公布答案,答案是「B、C、D」

Gemini 2.5 Pro

o1 Pro
Gemini 2.5 Pro回答正确,反观o1 Pro回答错误,看来Gemini 2.5 Pro的推理能力真不错。
虽然此次测评没有基准测试那么全,但也可以看到Gemini 2.5 Pro的强大之处,如果大家感兴趣,可以亲自去体验一下,毕竟是免费的。
相关阅读:

















 561
561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









