






Gemini 2.5 Pro 作为谷歌 2025 年 3 月 25 日发布的颠覆性 AI 模型,其技术细节、应用场景及性能表现可从以下维度展开分析:
一、技术架构与训练方法
1 动态认知蒸馏技术
通过将专家级数学证明过程分解为 120 万条思维片段,模型在推理时能动态激活相关知识节点,形成类似人类“思维树”的决策路径。例如面对拓扑绝缘体问题时,会生成 6 种可能路径并排除错误方向,最终输出含数学推导的完整解释。
2 量子化稀疏激活机制
在保持 175B 参数规模下,通过动态选择关键神经元子集进行计算,推理能耗降低 40%,同时支持百万级上下文窗口的实时处理。
3 自演进测试框架
每天自动生成 8.7 万个对抗性测试案例,覆盖从量子物理到法律伦理的跨学科场景,确保模型在复杂任务中的鲁棒性。
二、多模态与长上下文能力
1 输入输出特性
支持类型:文本(100 万 token)、图像(解析图表/手绘流程图)、音频(会议录音转录)、视频(关键帧分析)、完整代码库(如 GitHub 项目)。
输出限制:当前仅支持文本生成,但可通过代码生成间接实现图像/音频处理(如生成 Stable Diffusion 提示词或 FFmpeg 脚本)。
2 长上下文应用场景
学术研究:一次性解析 3 小时会议录音+200 页技术网页,生成带参考文献的综述报告。
企业级处理:某金融公司案例中,从 3,842 份财报和 2.7 万条新闻中定位半导体供应链风险,输出 12 种对冲方案。
文学创作:用户上传 268 页英文 PDF,模型用 20 分钟完成翻译,质量超越传统分段处理方法。
三、编程与推理能力突破
1 代码生成革命
单行指令生成完整应用:输入“开发像素恐龙跑酷游戏”,可输出包含物理引擎、碰撞检测的 Pygame 代码框架。
代码转换与优化:将 Python 数据分析脚本转化为并行计算的 Spark 作业,自动插入算子并生成性能测试用例。
跨模态编程:上传手绘流程图,直接生成符合 PEP8 规范的 Flask 后端代码及 Swagger API 文档。
2 数学推理表现
国际数学邀请赛(AIME):单次尝试准确率 86.7%,多次尝试提升至 93.3%,超越前代模型 47%。
复杂问题解决:在需要反事实推理的代数拓扑问题中,表现超越 IMO 金牌选手。
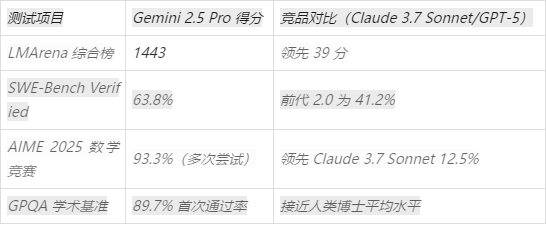
四、基准测试与竞品对比
五、用户体验与使用场景
1 开发者生态
接入方式:通过 Google AI Studio 免费体验(每日 50 次),或使用 API 集成至 Vertex AI 平台。
实测案例:某医疗科技公司使用该模型后,临床数据管道开发周期从 3 周缩短至 8 小时。
2 内容创作场景
视频摘要生成:上传 2 小时学术会议视频,自动识别关键帧并生成带时间戳的结构化摘要。
跨模态分析:解析财报 PDF 中的表格与手写批注,生成可视化图表及风险预警报告。
3 极限测试表现
百万 token 处理:成功分析《指环王》三部曲(约 45 万单词)的人物关系网络,并生成角色影响力图谱。
实时工具调用:遇到需要实时数据的问题时,自主调用 Wolfram Alpha 进行符号计算或 MATLAB 引擎执行数值模拟。
六、局限性与未来规划
1 当前限制
知识时效性:训练数据截止至 2025 年 1 月,无法处理后续事件(如新科技突破)。
多模态输出缺失:暂不支持直接生成图像/音频,需通过代码间接实现。
长上下文检索精度:在 50 万 token 处记忆准确率降至 92.3%,极端长文本可能遗漏细节。
2 迭代路线图
200 万 token 上下文:预计 2025 年 Q2 推出,支持整本《三体》三部曲+注释的分析。
多模态输出扩展:计划增加图表生成、语音合成功能,完善创作闭环。
七、行业影响与战略价值
Gemini 2.5 Pro 的发布标志着 AI 技术从“模式匹配”向“认知推理”的范式转变。其动态思维链架构为医疗诊断(如癌症病理分析)、法律文书审查(合同条款交叉验证)等高精度场景提供了新范式。据内部测试,模型在处理需要类比推理的 ConceptARC 测试时,展现出类似人类“顿悟”的认知跃迁,这可能成为迈向通用人工智能(AGI)的关键里程碑。

















 6646
6646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









