






ModelScope Notebook的产品基础概述,帮助你快速了解该功能。
ModelScope Notebook是一款云端机器学习开发IDE工具,为您提供交互式编程环境,适用于不同水平的AI开发者。 通过与阿里云PAI-DSW、弹性加速计算实例EAIS合作,Notebook为用户提供了开箱可用的限时免费算力额度,实现ModelScope模型开发环境与CPU/GPU等多样化计算资源的无缝连接。
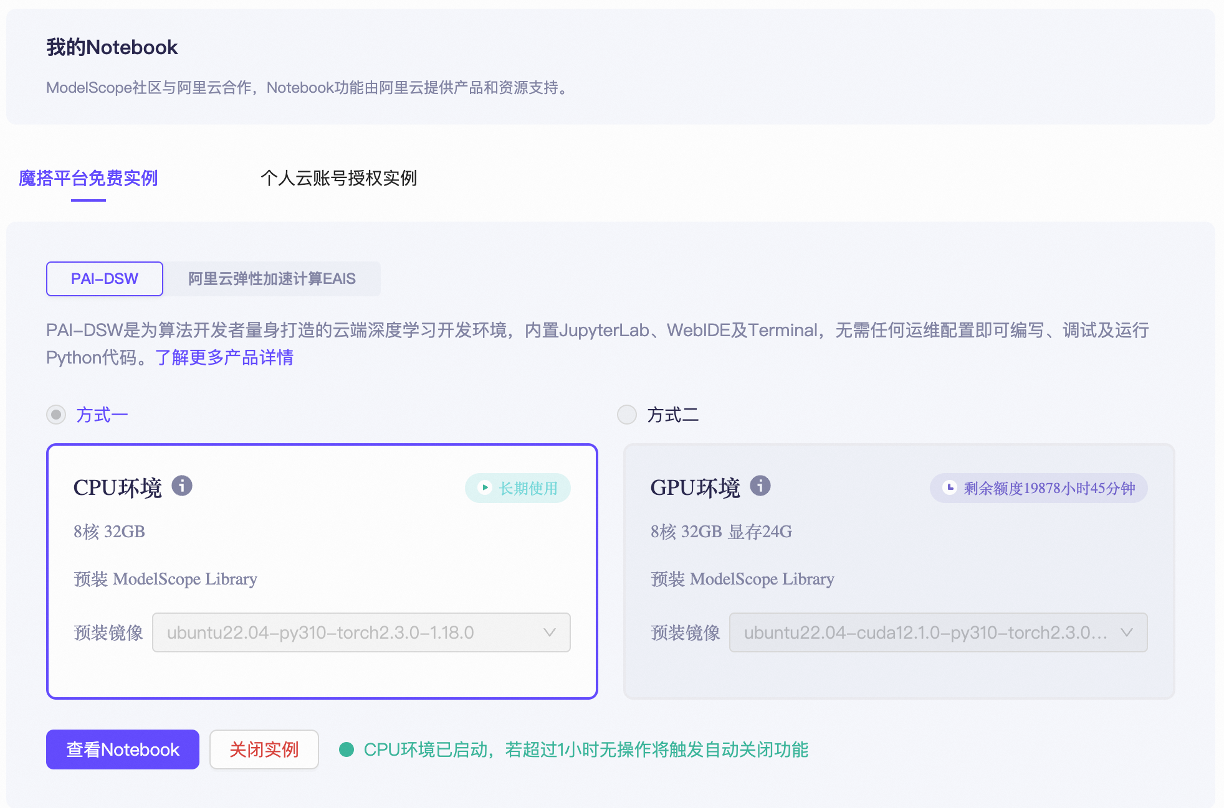
免费Notebook的使用,需要绑定阿里云账号授权,详细操作查看相关文档。
特性#
ModelScope Notebook是基于Jupyter Notebook,通过结合云上CPU/GPU计算实例来提供开箱即用的模型开发体验。同时Notebook也配置了Web-IDE的入口,方便开发者使用VS-Code IDE进行在线开发。关于原生Jupyter Notebook的官方功能介绍,请参考 官方文档。在这个基础上,ModelScope的Notebook预置了魔搭模型开发包及算法库,且支持自定义安装第三方库。同时基于不同云算力的Notebook,也有一些不同的产品特性:
| 功能 | PAI-DSW Notebook | EAIS Notebook |
|---|---|---|
| 支持GPU | 是 | 是 |
| CPU核数及内存 | 8核32G | 8核32G |
| 网络访问 | huggingface等外网访问受限 | github,huggingface等外网访问受限 |
| Root权限 | 默认root账号 | 默认root账号 |
| 持久化存储 | /mnt/workspace/ 目录 | 暂无 |
存储说明:#
- 免费Notebook环境均提供一定存储空间。当前基于PAI-DSW实例的Notebook,平台提供免费100G的持久化存储,并挂载在默认的 /mnt/workspace 目录下。对于需要持久化保存的数据,请在实例关闭前,确保其保存在/mnt/workspace/下,放置于其他路径下的数据,在实例关闭后会自动清除。
- 您可以通过
du -sh /mnt/workspace命令来查看当前免费持久化存储的使用额度,请及时清理不必要文件。 - 平台提供的免费存储,是为了方便您的使用,不做SLA保障。重要数据请勿依赖免费持久化存储能力,务必自行备份避免丢失。同时如果账号如果长时间(365天以上)无活动,平台可能清除对应账号的持久存储数据。
- EAIS Notebook暂时不支持数据的持久化存储。
- 若您使用的为付费的DSW或EAIS资源来使用Notebook,可以根据相关云产品说明,自行挂载云存储资源。
在Notebook运行模型推理,评估等范例#
通过ModelScope Notebook使用ModelScope上的模型时,所有的依赖环境都已经预先安装好,可直接使用。
运行推理pipeline#
下面以中文分词任务为例,说明pipeline函数的基本用法。
- pipeline函数支持指定特定任务名称,加载任务默认模型,创建对应pipeline对象。 执行如下python代码 :
from modelscope.pipelines import pipeline word_segmentation = pipeline('word-segmentation')
- 输入文本
input_str = '今天天气不错,适合出去游玩' print(word_segmentation(input_str)) {'output': '今天 天气 不错 , 适合 出去 游玩'}
- 输入多条样本
pipeline对象也支持传入多个样本列表输入,返回对应输出列表,每个元素对应输入样本的返回结果。
inputs = ['今天天气不错,适合出去游玩','这本书很好,建议你看看'] print(word_segmentation(inputs)) [{'output': '今天 天气 不错 , 适合 出去 游玩'}, {'output': '这 本 书 很 好 , 建议 你 看看'}]
加载数据集#
ModelScope可以提供了标准的MsDataset接口供用户进行基于ModelScope生态的数据源加载。下面以加载NLP领域的afqmc(Ant Financial Question Matching Corpus)数据集为例进行演示
from modelscope.msdatasets import MsDataset # 载入训练数据 train_dataset = MsDataset.load('afqmc_small', split='train') # 载入评估数据 eval_dataset = MsDataset.load('afqmc_small', split='validation')
数据预处理#
在ModelScope中,数据预处理与模型强相关,因此,在指定模型以后,ModelScope框架会自动从对应的modelcard中读取配置文件中的preprocessor关键字,自动完成预处理的实例化。
# 指定文本分类模型 model_id = 'damo/nlp_structbert_sentence-similarity_chinese-tiny'
训练#
首先,配置训练所需参数:
from modelscope.trainers import build_trainer # 指定工作目录 tmp_dir = "/tmp" # 配置参数 kwargs = dict( model=model_id, train_dataset=train_dataset, eval_dataset=eval_dataset, work_dir=tmp_dir)
其次,根据参数实例化trainer对象
trainer = build_trainer(default_args=kwargs)
最后,调用train接口进行训练
trainer.train()
恭喜,你完成了一次模型训练😀
评估#
训练完成以后,配置评估数据集,直接调用trainer对象的evaluate函数,即可完成模型的评估,
# 直接调用trainer.evaluate,可以传入train阶段生成的ckpt # 也可以不传入参数,直接验证model metrics = trainer.evaluate(checkpoint_path=None) print(metrics)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









