






本文介绍模型卡片(Model card)的定义、编辑规范、使用方式和管理说明。
模型卡片#
模型卡片是社区用户获取模型信息的关键来源,主要通过模型文件中的README.md文件维护。其主要由头部的 YAML元数据 和 Markdown正文 共两个部分组成,为社区用户快速了解、使用、共享模型提供了沟通协作的媒介。
一份完善的模型卡片可以包括但不限于以下内容:
-
模型名称与模型描述。介绍该模型的基础信息、特点、架构等。
-
期望模型使用方式以及适用范围。 介绍该模型适用的应用场景,便于用户理解。
-
如何使用。 可以给出简单示例介绍用户如何使用该模型,包括所使用的框架、运行环境要求或者模型调优的数据格式等。若给出代码范例供效果更佳。
-
训练数据。介绍使用了怎样的训练数据集或数据格式要求。
-
训练流程。介绍如何训练,使用了怎样的预处理方法、训练参数等。
-
数据评估及结果。介绍模型运行的效果和性能维度。
详细内容请参阅本文模型卡片正文部分。
为了社区用户更好地了解、使用、交流社区开源模型,我们强烈建议模型贡献用户参照撰写规范完善模型卡片。同时,我们也倡议全体社区用户积极参与共建社区开源模型,您可以通过模型页面的讨论版块向您关注模型的所有者提建议,或直接修改、补充、完善其模型卡片内容并提交拉取请求(Pull Request)。
模型卡片元数据#
模型卡片元数据由 README.md 文件头部的 YAML 小节维护,并使用 --- 将其与 Markdown 正文分节区隔。元数据主要用于描述与模型相关的基础字段,包括但不限于:开源证书(License)、语言(language)、任务类型(tasks)、框架(frameworks)、基础模型(base_model)、新版本(new_version)、模型指标(metrics)、关联数据集(datasets)及自定义标签(tags)等。
在魔搭社区,元数据将被用于提升模型的发现效率及模型使用的易用性。如展示模型的开源证书、在搜索页面中筛选模型、在模型详情页展示关联的数据集、在模型详情页展示微调训练的血缘系谱等。
添加卡片元数据#
社区提供两种不同的方式维护卡片元数据:
-
使用元数据配置界面
-
直接在 README.md 文件中编辑 YAML 头
使用配置界面快速添加#
您可以前往“模型文件-README.md文件-编辑”进入编辑状态,并使用我们提供的配置界面很方便快速地添加重要元数据。如须添加其他元数据,可直接在文件中的 YAML 头中添加、编辑。
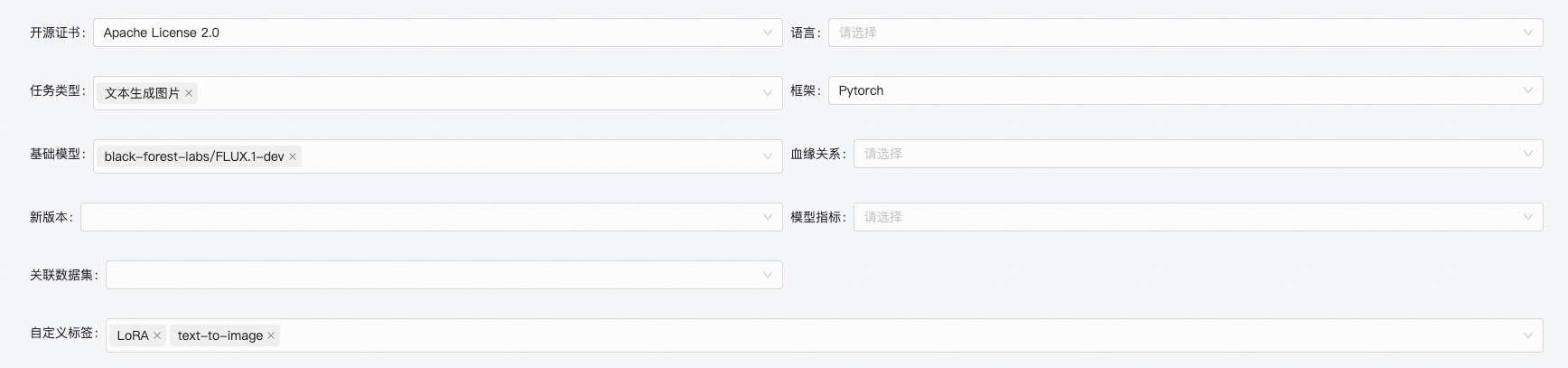
在文件中编辑 YAML 头#
您也可以直接使用 README.md 文件的 YAML 头编辑元数据。如果原始文件中没有 YAML 头,您可以添加两行成对的---将元数据部分包括在其中完成 YAML 头的编辑。
详细的元数据字段介绍及示例可参考以下示例:
---
license: Apache License 2.0 # 开源许可证类型,如Apache License 2.0、GPL-2.0、GPL-3.0、MIT等。
tasks:
- image-classification # 对应模型pipeline的任务类型,用户也可以自定义任务类型。
frameworks: # 支持的深度学习框架,如"pytorch"、"tensorflow"等。
- pytorch
- tensorflow
language: # 支持的语言类型
- en
- fr
- cn
tags: # 用户可自定义标签,方便搜索和分类
- transformer
- Alibaba
- customized-tag
datasets: 模型所关联的数据集
- OmniData/Pile-BookCorpus2
# 或者也可以这样描述datasets
datasets:
train:
- owner_name/trainset1
- owner_name/trainset2
test:
- owner_name/testset
evaluation:
- owner_name/mydataset
metrics: # 评估模型性能的指标
- accuracy
- recall
- precision
base_model: owner_name/model_name
# 以下对模型在不同任务下的评估指标及结果进行说明
indexing:
results:
- task:
name: Image Classification # 任务名称
dataset:
name: mydataset1 # 数据集名称
type: images # 数据集类型(可选)
args: default # 其他参数(可选)
metrics:
- type: accuracy
value: 0.8 # 在mydataset1上的准确率
description: true positive rate on data xxx
args: default
- type: recall
value: 0.05 # 在mydataset1上的召回率
description: recall on data xxx
args: default
- task:
name: Text Classification # 任务名称
dataset:
name: mydataset2 # 数据集名称
type: text # 数据集类型(可选)
args: default # 其他参数(可选)
metrics:
- type: precision
value: 0.7 # 在mydataset2上的精确率
description: precision for classification on data xxx
args: default
domain:
- multi-modal # 模型所属领域。包括"cv""nlp""audio""multi-modal"等,用户也可自定义。
---
其中,tasks字段支持填写的详细任务类型可参看任务类型列表。您可以根据需要在模型卡片中添加合适的元数据,或者您也可以自定义元数据字段名。
元数据的可视化展示#
在模型卡片中,以下元数据提示了模型及其相关模型、数据集的关联关系,有效填写后将激活模型卡片详情页的“模型系谱”、“版本更新提示”等功能,有利于阅读用户更全面、系统的认知当前模型及其关联模型、关联数据集,同时提升模型在社区内的发现效率。
| 字段名称 | 中文描述 | 字段示例值 |
|---|---|---|
| base_model | 基础模型:模型 ID ,通过一定方法衍生出当前模型的基础模型。 | Qwen/Qwen2.5-7B-Instruct的基础模型为Qwen/Qwen2.5-7B,支持以列表格式传入多值。 |
| base_model_relation | 血缘类型:枚举值,填入"adapter", "merge", "quantized", "finetune"之一。既可以在该字段中直接指定,也可以由平台自动判定。 | adapter |
| new_version | 当前同系列模型的新版本 | Qwen/Qwen2-72B-Instruct的新版本模型为Qwen/Qwen2.5-72B-Instruct |
| datasets | 相关数据集:数据集ID,当前模型训练、评估等使用过的数据集 | BAAI/Aquila-135M模型的相关数据集为BAAI/Infinity-Instruct |
模型系谱#
对于微调模型、适配器模型、或者是基础模型的量化版本、由多个社区其他模型合并产生的新模型,您可以前往模型卡片元数据配置基础模型(base_model)。当您所配置的基础模型为有效的模型ID,模型卡片页面将会展示当前模型的模型系谱。

模型系谱由当前模型、基模型及当前模型与基模型的血缘关系逐级推导而来,您可以轻松的由模型系谱发现更多产生当前模型的基础模型,或由当前模型派生的新模型。
模型系谱中所展示的当前模型与基模型的血缘关系,可以由一定的规则自动推理而来,同时也可以直接由模型卡片元数据中的“血缘关系(base_model_relation)”显式指定,其值须为 "adapter", "merge", "quantized", "finetune"之一。
版本更新提示#
当同系列模型在 ModelScope 存在一个更新的版本时,您可以通过在元数据中指定new_version字段的值为对应模型ID来完成新版本关联。完成配置后,模型卡片页面将提示“此系列模型有新发布,点击前往最新模型”。
如Qwen/Qwen2-72B-Instruct存在一个新的版本Qwen/Qwen2.5-72B-Instruct,那么可以在Qwen/Qwen2-72B-Instruct的模型卡片元数据中配置:
new_version: Qwen/Qwen2.5-72B-Instruct
相关数据集#
当该模型使用到的数据集在 ModelScope 社区已经完成上传时,您可以在元数据中指定datasets字段为对应的数据集ID来完成关联。完成配置后,平台将自动关联该模型及数据集,并在模型卡片页面的“相关数据集”部分、数据集卡片页面的”相关模型“部分提供快捷的互跳链接。
模型卡片正文#
本小节提供推荐的模型卡片正文模板,您可以参考模板并根据需要灵活组织正文内容。
<!--- 以下model card模型说明部分,请使用中文提供(除了代码,bibtex等部分) --->
# <模型名字>介绍
介绍模型的基本信息。
## 模型描述
提供模型描述,包括模型结构,使用的训练数据集,以及适用场景等等内容;也可以链接模型的来源,包括代码仓库、论文或DEMO。
## 期望模型使用方式以及适用范围
介绍模型的目标使用场景。
### 如何使用
介绍模型如何使用,包括如何进行模型推理、模型微调等信息。在这里希望模型提供者能提供
详尽的范例以及代码片段来介绍模型的使用方法。对于需要配置负责运行环境的模型,
也可以在这里提供怎样配置模型运行环境的详细介绍。
如果模型支持微调,在本小节也请介绍微调需要准备的数据集格式及要求。
#### 代码范例
<!--- 请分别提供模型推理、模型微调的代码范例--->
```python
import cv2
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
from modelscope.pipelines.outputs import OutputKeys
img_matting = pipeline(Tasks.portrait_matting,model='damo/cv_unet_image-matting')
result = img_matting('test.png')
cv2.imwrite('result.png', result[OutputKeys.OUTPUT_IMG])
```
### 模型局限性以及可能的偏差
介绍模型适用的场景,以及在哪些场景可能存在局限性,以及模型在构造训练过程中,
本身可能带有的,由于训练数据以及训练方法等因素引入的偏向性。
## 模型训练
描述模型是如何具体训练出来的。
### 训练数据介绍
介绍训练数据是如何获取,组织,以及针对模型的需求进行格式化的。
### 预处理
介绍如何对训练数据进行预处理。
### 训练
介绍训练的硬件要求与环境、训练的超参数设置、训练的步骤与流程,并提供必要的训练代码块。
## 数据评估及结果
提供模型在不同数据集上的性能评测,包括评测数据是如何获得的。评测结果本身
可以通过表格,图像等多种方法做展示。
### 相关论文以及引用信息
如果本模型有相关论文发表,或者是基于某些论文的产出物,可以在这里提供Bibtex格式的参考文献。
模型卡片正文具体示例可以参阅:iic/cv_swin-b_image-instance-segmentation_coco 的 README.md 文件。
模型的在线体验服务#
除了模型卡片上的 Markdown 信息,模型卡片上还可以提供可视化的在线demo供用户快速测试模型效果。
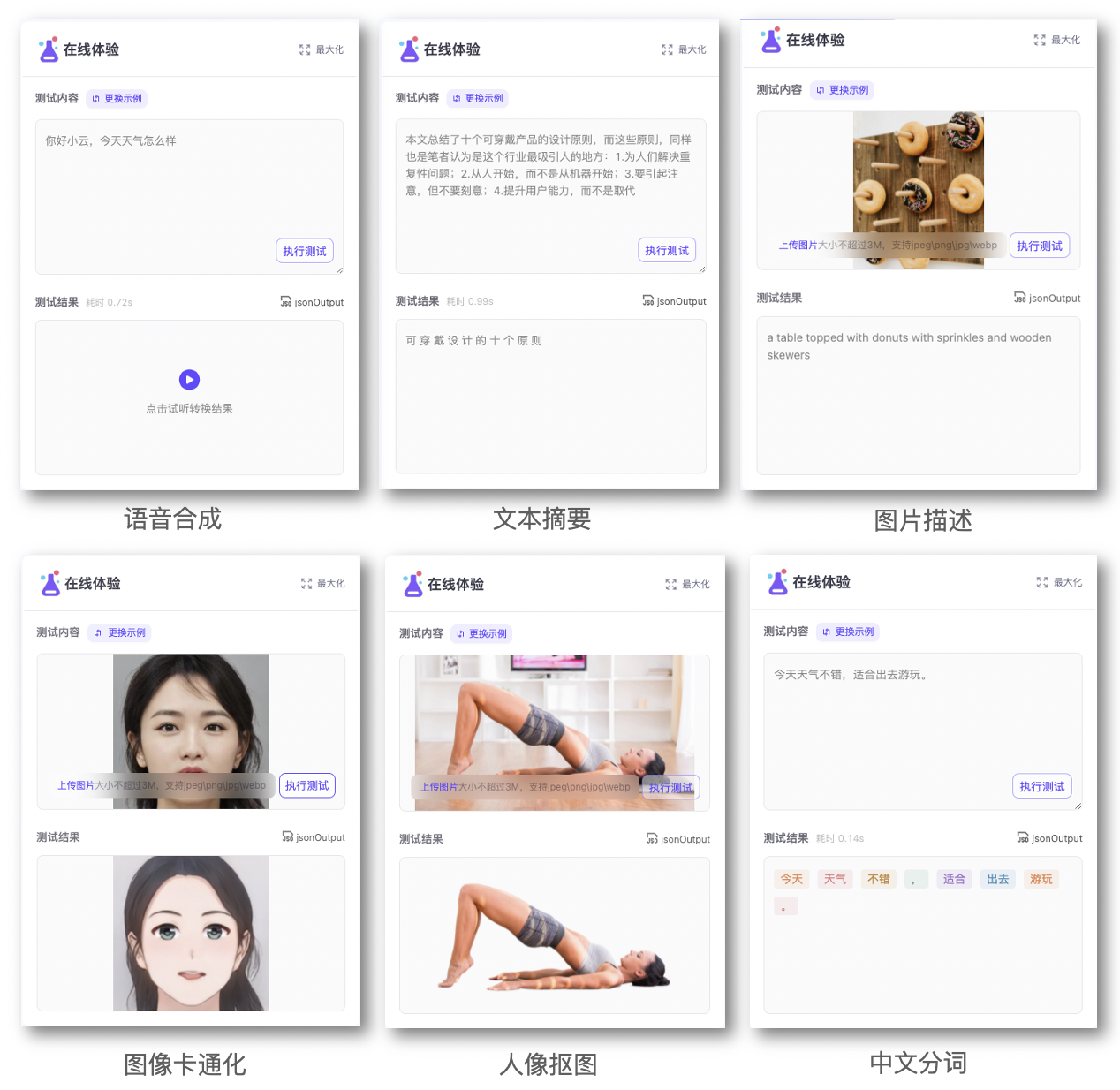
您可以在编辑 README.md 文件时找到 “DEMO配置” 的入口,为您的模型选择社区已经支持的在线 DEMO 模板

















 7791
7791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









