







1 索引的作用
索引就像书的目录, 通过书的目录就准确的定位到了书籍具体的内容。我们知道目录只存放标题,浏览标题比翻书要快的多。就好比我们对id建立索引,我们查询id就只查询id这一个属性,而不是去遍历id对应的整条记录。先查询id所在的数据页,通过缩小记录的查找范围,有效的减少IO的次数。
2 索引分类
2.1 聚集索引
索引的顺序就是数据的物理存储顺序,索引的叶子节点就是数据节点。
2.2 非聚集索引
索引顺序和物理存储数据顺序无关,索引的叶子节点依然是索引节点。
该如何理解呢?
其实,我们的汉语字典的正文本身就是一个聚集索引。比如,我们要查“安”字,就会很自然地翻开字典的前几页,因为“安”的拼音是“an”,而按照拼音排序汉字的字典是以英文字母“a”开头并以“z”结尾的,那么“安”字就自然地排在字典的前部。如果您翻完了所有以“a”开头的部分仍然找不到这个字,那么就说明您的字典中没有这个字;同样的,如果查“张”字,那您也会将您的字典翻到最后部分,因为“张”的拼音是“zhang”。也就是说,字典的正文部分本身就是一个目录,您不需要再去查其他目录来找到您需要找的内容。我们把这种正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”。
如果您认识某个字,您可以快速地从自动中查到这个字。但您也可能会遇到您不认识的字,不知道它的发音,这时候,您就不能按照刚才的方法找到您要查的字,而需要去根据“偏旁部首”查到您要找的字,然后根据这个字后的页码直接翻到某页来找到您要找的字。但您结合“部首目录”和“检字表”而查到的字的排序并不是真正的正文的排序方法,比如您查“张”字,我们可以看到在查部首之后的检字表中“张”的页码是672页,检字表中“张”的上面是“驰”字,但页码却是63页,“张”的下面是“弩”字,页面是390页。很显然,这些字并不是真正的分别位于“张”字的上下方,现在您看到的连续的“驰、张、弩”三字实际上就是他们在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我们可以通过这种方式来找到您所需要的字,但它需要两个过程,先找到目录中的结果,然后再翻到您所需要的页码。我们把这种目录纯粹是目录,正文纯粹是正文的排序方式称为“非聚集索引”。
2.3 图示
聚集索引
以学生表为例,根节点(310页)存放了两个索引表的地址(202页和302页),如果,要查询201511101,首先,从根节点定位到202页,再定位到101页,之后再遍历101页的每一条记录,就可以找到201511101对应的记录。这种查询的次数要比顺序遍历每一条记录的IO次数要少。

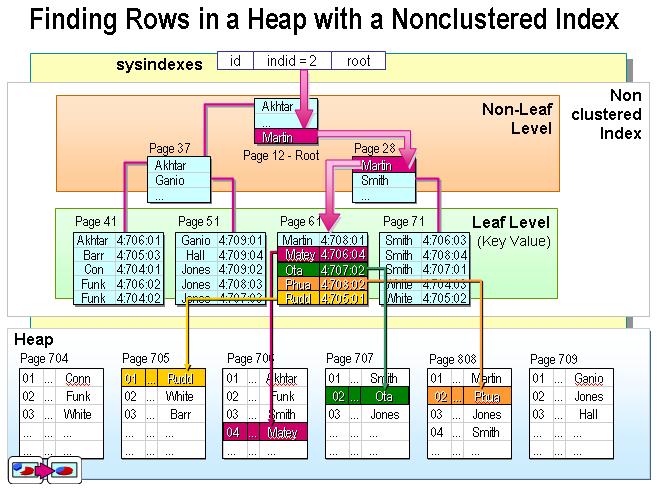
非聚集索引:非聚集索引不是按照物理顺来建立索引的,它的叶子节点仍然是索引,这个索引指向的是数据页。比如,搜索Martin,首先,由根节点定位到28页,然后定位到61页(仍然是一个索引),之后,定位到数据707页,逐条的遍历记录。
2.4 聚集索引和非聚集索引的比较:
聚集索引:
· 优点是查询速度快,因为一旦具有第一个索引值的纪录被找到,具有连续索引值的记录也一定物理的紧跟其后。
· 缺点是对表进行修改速度较慢,这是为了保持表中的记录的物理顺序与索引的顺序一致,而把记录插入到数据页的相应位置,必须在数据页中进行数据重排(继续保持B+树的结构), 降低了执行速度。
非聚集索引:
不影响表中的数据存储顺序,检索效率比聚集索引低,对数据新增/修改/删除的影响很小。非聚集索引的叶子层并不与实际的数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针的方式。非聚集索引比聚集索引层次多,添加记录不会引起数据顺序的重组。
3 mysql索引类型
3.1 简单索引
Mysql中的索引:
CREATE TABLE `NewTable` (
`bookid` INT NOT NULL,
`bookname` VARCHAR (255) NOT NULL,
`year_publication` YEAR NOT NULL,
PRIMARY KEY (`bookid`),
INDEX `year_publication` (`year_publication`)
);3.2 唯一索引
CREATE TABLE `user` (
`id` int(20) NOT NULL,
`userid` int(20) NOT NULL,
`name` varchar(30) NOT NULL,
UNIQUE KEY `userid` (`userid`)
);3.3 主键索引
CREATE TABLE `user2` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
);唯一索引和主键索引的区别:
(1)唯一索引不能为空,而唯一索引可以为空
(2)主键可以作为外键,而唯一索引不能作为外键
(3)主键索引默认为聚集索引,而唯一索引默认为非聚集索引
3.4 组合索引
CREATE TABLE `user3` (
`id` int(11) NOT NULL,
`name` varchar(255) NOT NULL,
`age` int(11) NOT NULL,
`info` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `multi` (`id`,`name`,`age`) USING BTREE
);
组合索引就是遵从了最左前缀,利用索引中最左边的列集来匹配行,这样的列集称为最左前缀,不明白没关系,举几个例子就明白了,例如,这里由id、name和age3个字段构成的索引,索引行中就按id/name/age的顺序存放,索引可以索引下面字段组合(id,name,age)、(id,name)或者(id)。如果要查询的字段不构成索引最左面的前缀,那么就不会是用索引,比如,age或者(name,age)组合就不会使用索引查询。
3.5 全文索引
全文索引可以用于全文搜索,但只有MyISAM存储引擎支持FULLTEXT索引,并且只为CHAR、VARCHAR和TEXT列服务。索引总是对整个列进行,不支持前缀索引。
CREATE TABLE `NewTable` (
`id` int NOT NULL ,
`name` varchar(255) NOT NULL ,
`info` varchar(255) NOT NULL ,
PRIMARY KEY (`id`),
FULLTEXT INDEX `text` (`info`)
);切换到MySAM引擎的方法a:
1、停掉mysql服务
2、打开my.ini,搜索
default-storage-engine=
你搜索到的应该是
default-storage-engine=INNODB
3、把INNODB改成MyISAM
4、重新启动Mysql
4 为已经存在的表创建索引
格式一:ALTER TABLE 表名 ADD[UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] [索引名] (索引字段名)[ASC|DESC]
格式二:CREATE [UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] 索引名称 ON 表名(创建索引的字段名[length])[ASC|DESC]
5 删除索引:
格式一:ALTER TABLE 表名 DROP INDEX 索引名。
格式二:DROP INDEX 索引名 ON 表名;














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









