







如何让我们在SD中绘制的角色保持一致,这是人们长久以来在探索AI绘画的领域当中一直寻求解决的问题。目前来看,实现这个目标最好的方法就是使用LoRA。
但是要训练一个LoRA,我们首先要至少有一个15到20张图片的训练集。在一个固定的形象中,最重要的是面部五官,其次是体型、服装、配饰之类的。所以,我们在收集训练集的过程当中,收集形象的头部图片是很重要的。
现实中的人物我们可以通过照片来进行训练,但如果是我们在AI中生成的虚构角色呢?我们就要让这个虚构角色能稳定输出多张不同角度的图片才能达到训练集的要求。
今天,我们就来学习一下,如何创建一个虚构人物的多视图角色表。
01、准备工作
首先,我们要准备一张人物的多角度图片。这张图一共有15个不同的视图,它的主要作用是可以使用openpose来控制形象的面部角度。尺寸设置的是1328×800px,这样的话,当我们放大两倍之后就能保证每张小图都是512×512px。
【一个小知识:稳定扩散输出尺寸必须能被8整除。这个工作表的设置方式是由__8 像素的分割线和 256×256像素__的图像组成。__】

再加上一个网格图,通过lineart来分割不同的块面。

接下来,我们来设置controlnet,第一张图选择openpose_face,得到人物的15个面部角度。
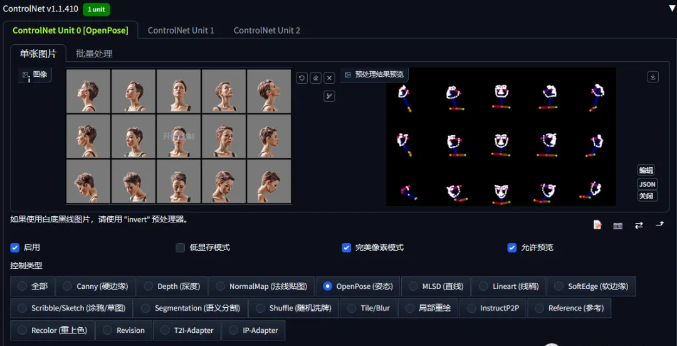
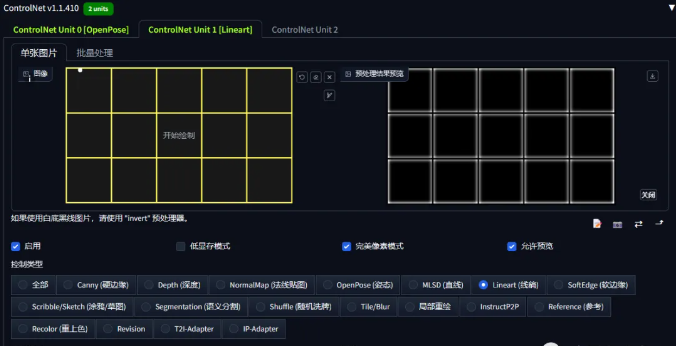
第二张图选择lineart_standard (from white bg & black line),可以得到清晰的表格分区。
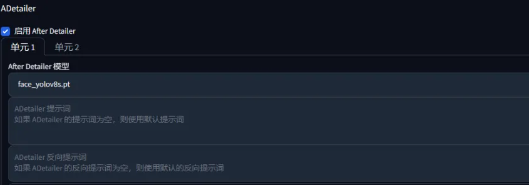
为了让小图模式下的人脸不会崩坏,我们可以在增加一个ADetailer的脸部修复插件。
02、开始生图
设置文生图提示词:
大模型:majicmixRealistic_v6.safetensors
正向提示词:
(a character sheet of a woman from different angles with a grey background:1.4),auburn hair,eyes open,cinematic lighting,Hyperrealism,depth of field,photography,ultra highres,photorealistic,8k,hyperrealism,studio lighting,photography,
负向提示词:
EasyNegative,canvasframe,canvas frame,eyes shut,wink,blurry,hands,closed eyes,(easynegative),((((ugly)))),(((duplicate))),((morbid)),((mutilated)),out of frame,extra fingers,mutated hands,((poorly drawn hands)),((poorly drawn face)),((bad art)),blurry,(((mutation))),(((deformed))),blurry,((bad anatomy)),(((bad proportions))),((extra limbs)),cloned face,(((disfigured))),gross proportions,(malformed limbs),((missing arms)),((missing legs)),((floating limbs)),((disconnected limbs)),((malformed hands)),((missing fingers)),worst quality,((disappearing arms)),((disappearing legs)),(((extra arms))),(((extra legs))),(fused fingers),(too many fingers),(((long neck))),canvas frame,((worst quality)),((low quality)),lowres,sig,signature,watermark,username,bad,immature,cartoon,anime,3d,painting,b&w,
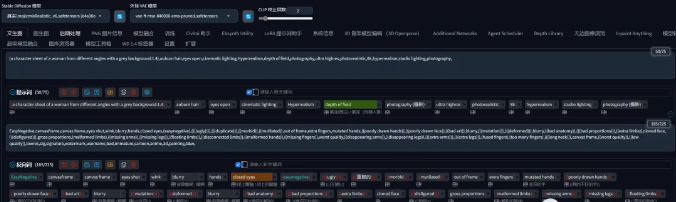
设置一下参数:
迭代步数:50
采样方法:DPM++ 2M Karras
尺寸:1328×800px
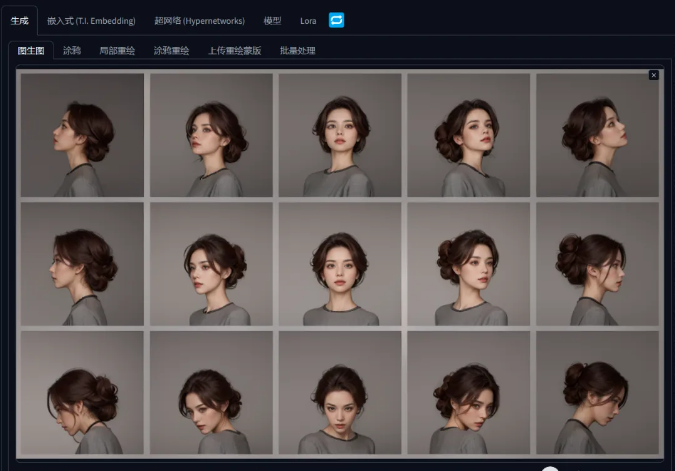
出图!15个不同角度的人物图片,大概看下来基本就是同一个人,没毛病。

03、细节放大
接下来发送到图生图,进行一次放大。
重绘幅度设置为0.55,不需要太高。
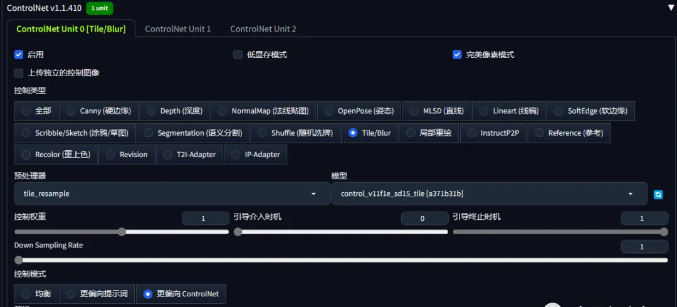
使用controlnet的teil模型来增加细节,控制模式选择“更倾向controlnet”。
Ultimate SD upscale脚本放大为2倍,使用4x-UltraSharp放大算法。
生成出图,我们来看一下最终的效果。

04、随便试试
接下来,我们再来试一试二次元的形象吧。
使用AnythingV5大模型,绘制一个浅绿色的侧马尾女孩的形象。

再做一个手办风格的卡通角色
使用revAnimated大模型,绘制一个粉色头发的长发公主的形象。

怎么样,效果不错吧,你学会了吗?
以上,就是关于在sd中制作多角度角色形象的方法。当然,由于AI绘画的随机性存在,15个角度的画面不可能那么完美,controlnet的控制也是让我们更大程度的去接近自己想要的效果。所以想要好的结果,多刷刷图吧~
需要stable diffusion相关资料的话,可以看下方扫描获取
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除















 3561
3561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









