






大家好,我是向阳。
当你用AI绘画Stable Diffusion生成出 场景很逼真、人物也很精致的图片时,会不会很开心?但是不是总是感觉照片少了点什么?
其实是因为图片缺少合适的光!
无论是自然光还是人造光
恰当地利用光线,能够为图片塑造质感、创造氛围
如果你希望SD生成的图片不再单调
不妨查看我为大家准备的这篇SD打光教程~
妙招1:关键词提示
“上帝说,要有光,于是,就有了光。”想要给图片打光,咱们不用动嘴,动手就行(doge)。通过使用不同的照明关键词,我们可以让图片获得多样的光线效果。

(柔和照明效果)
例如添加关键词“soft lighting(柔和照明)“,它就能够增强人物面部和背部的光线,带来柔和的光线表现。

(阳光照射效果)
如果想要实现在户外的自然光线效果,我们可以添加关键词“sunlight”,人物及背景景物就会实现自然的阳光照射。你别说,你还真别说,阳光照射的感觉有了!

(工作室灯光效果)
另外推荐的一个关键词是“studio linght(工作室灯光)”,它可以为人物补足光源,带来更强的立体感。纯色的背景再加上充足明亮的光线,这怎么就不是影棚实拍呢?(咱可以把手忽略哈)
通过关键词提示,我们可以很方便地为图片带来各种光照效果,但缺点大家也能看到,就是无法精确地控制光照的方向和范围。如果你想更进一步,不妨跟随小i接着往下看。
妙招2:ControlNet控制
对于经常使用SD的小伙伴来说,应该不会对ControlNet感到陌生。这是一款可以精准控制图像生成效果的AI绘画插件,支持多种预处理器和模型。作者名叫张吕敏,是的你没猜错,这是一位中国人,目前在斯坦福读博。

(图片来源于网络)
通过这个插件,我们能够进一步地精确控制照明区域,实现更好的打光效果。话不多说,一起来看看具体的操作步骤吧!
具体操作步骤
STEP 1
下载并安装ControlNet插件。(插件获取请看下方扫描获取)

STEP 2
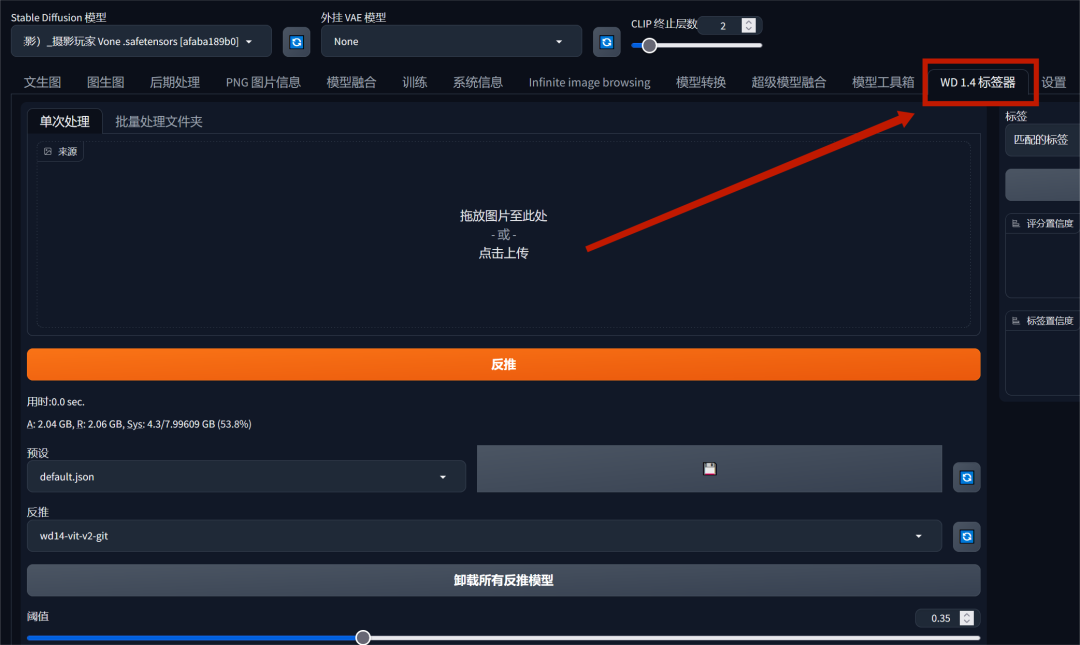
在webui打开**“WD1.4标签器”**,同时上传要变换的图片。选择的大模型风格也需与图片类似,这样能够尽可能地保证生成图片与原图的一致性。
STEP 3
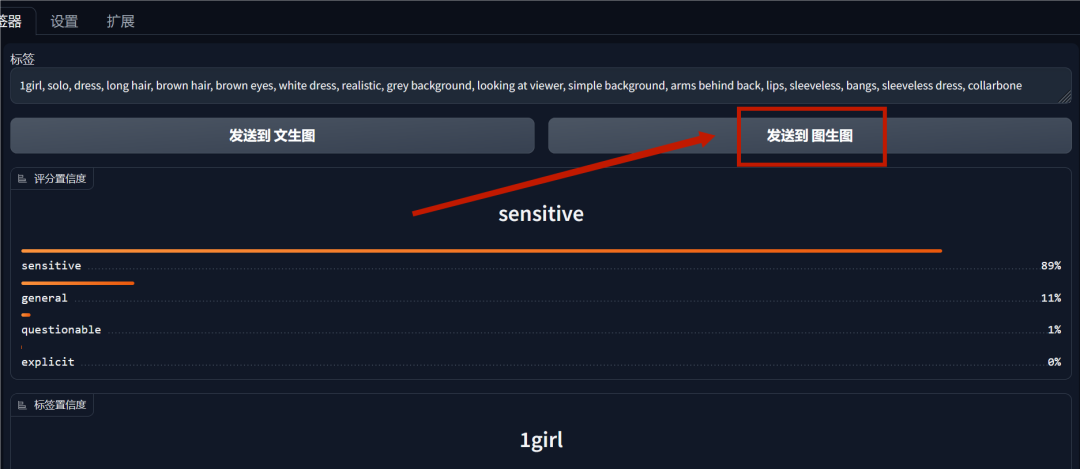
通过图片反推出关键词,并点击“发送到图生图”
STEP 4
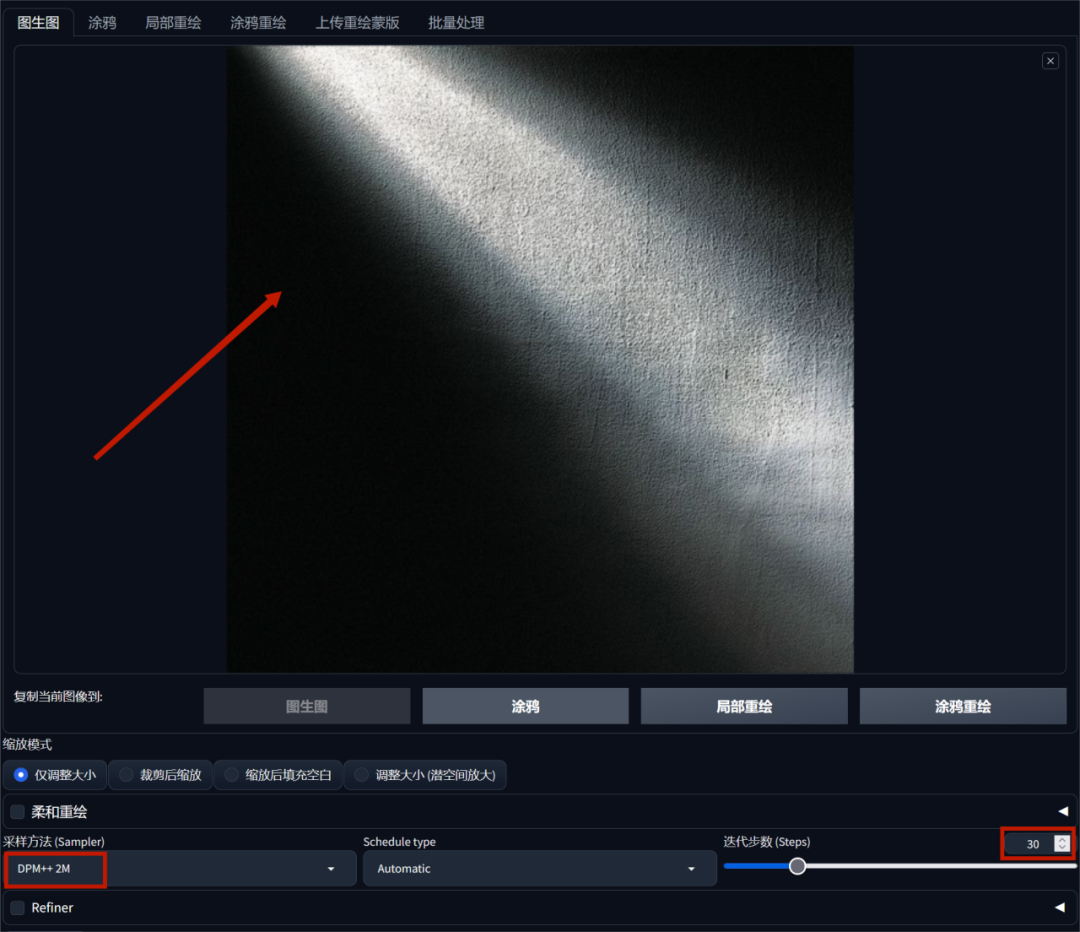
在“图生图”界面上传准备好了的光束图,上传的光束图尺寸最好与原图_保持一致_。采样方法设置为“DPM+2M”,迭代步数设置为30步。
STEP 5
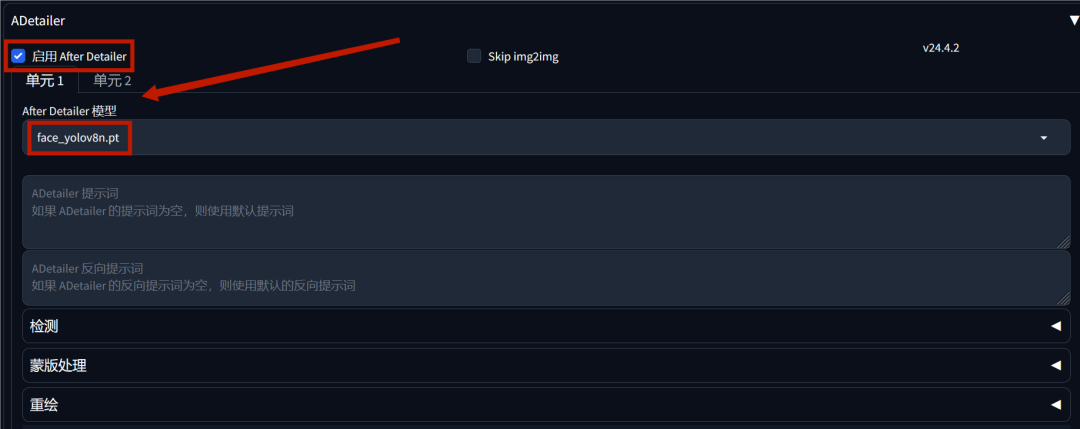
在ADetailer模块,我们点击“启用after Detailer”,模型选择“face_yolov8n.pt”,这一步可以防止人物的面部出现畸变,毕竟你也不想被奇奇怪怪的五官吓到吧?
STEP 6
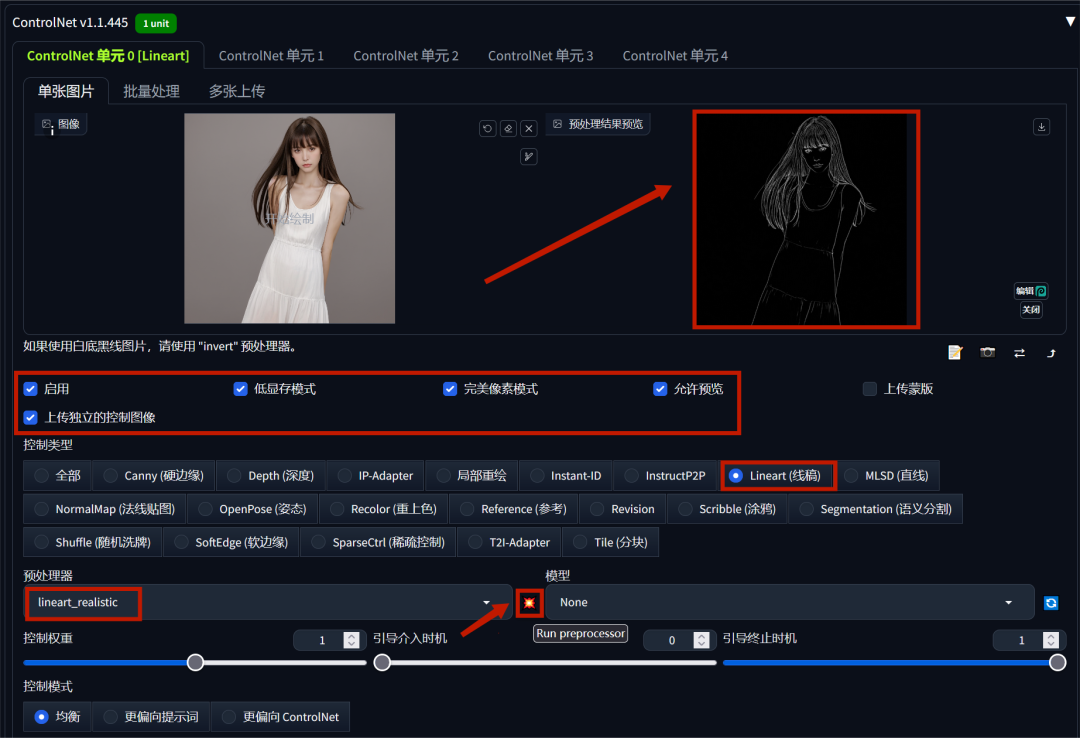
接着向下滑动到ControlNet模块,点击开启并上传图片。在_控制类型中选择“lineart(线稿)”,预处理器选择“lineart-realistic”_,之后点击右侧的爆炸图标,我们就能看到图片右侧的预处理结果预览。
STEP 7

最后点击页面右上角的生成按钮,图片就自动生成啦。我们可以看到原图与光束图形成了很好的结合。
更多效果展示
当我们选择不同的光束图时,光影效果也会随之变化。
1、


2、


3、


通过以上图片我们可以看到,最终的成图很好地呈现了光束图的的光线方向以及范围,明暗有致、也更具艺术表现力。不知道大家是否也忍不住想要试一试呢?
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除















 2574
2574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









