









一、OCR到底选哪个模型?
OCR(Optical Character Recognition,光学字符识别)。目前开源OCR工具种类繁多,不同场景图像的识别效果却参差不齐,这给开发人员的选型工作带来了不小的挑战。
为了尽可能全面测试OCR工具的识别能力,该链接文章测评精心挑选了12款开源OCR工具,评测过程参考原文:评测报告
该链接文章评测开源OCR基本的文字识别能力,包括印刷中文、印刷英文、手写中文等三类基本类型,以及复杂自然场景和变形字体两类附加测评;
这里直接上结论:
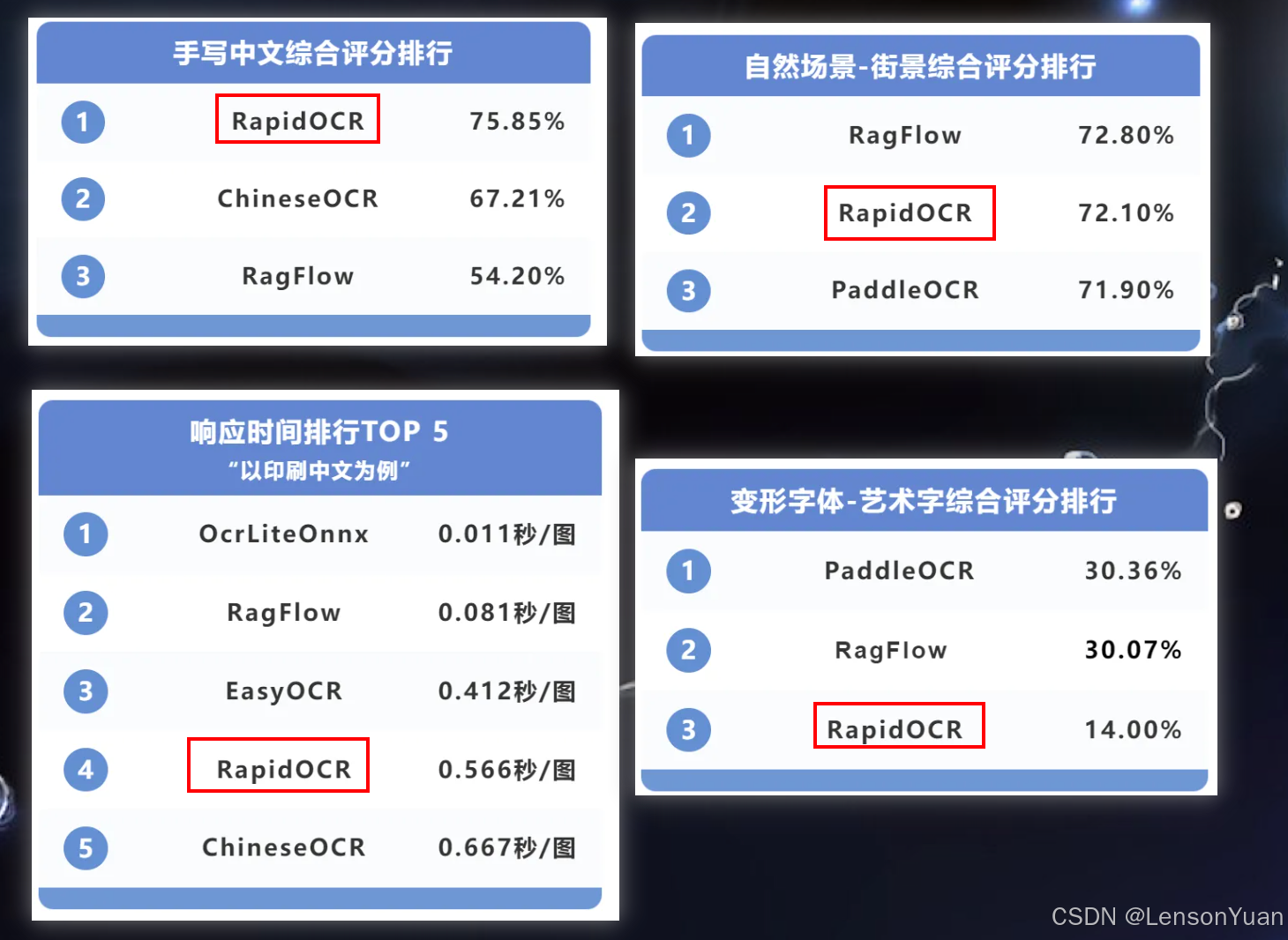
二、OCR界扛把子RapidOCR
本文要重点介绍的就是优秀生RapidOCR,以下是基本的使用。文末附源码(包含模型文件)。
2.1 官方简介
💖目前,我们自豪地推出了运行速度最为迅猛、兼容性最为广泛的多平台多语言OCR工具,它完全开源免费,并支持离线环境下的快速部署。其核心亮点在于采用ONNXRuntime作为推理引擎,相比传统的PaddlePaddle推理引擎,速度实现了4至5倍的提升,同时彻底解决了内存泄露问题,确保了高效稳定的运行。
🦜 支持语言概览: 默认支持中文与英文识别,对于其他语言的识别需求,我们提供了便捷的自助转换方案。具体转换指南,请参见这里。
🔎 项目缘起: 鉴于PaddleOCR在工程化方面仍有进一步优化的空间,为了简化并加速在各种终端设备上进行OCR推理的过程,我们创新地将PaddleOCR中的模型转换为了高度兼容的ONNX格式,并利用Python、C++、Java、C#等多种编程语言,实现了跨平台的无缝移植,让广大开发者能够轻松上手,高效应用。
🎓 名称寓意: RapidOCR,这一名称蕴含着我们对产品的深刻期待——轻快(操作简便,响应迅速)、好省(资源占用低,成本效益高)并智能(基于深度学习的强大技术,精准高效)。我们专注于发挥人工智能的优势,打造小巧而强大的模型,将速度视为不懈追求,同时确保识别效果的卓越。
三、改进的源码包教程
3.1 源码资源地址点此处下载
3.2 代码说明
rapidocr官方是只实现了核心部分,返回的是图片。实际大部分场景是要发布成api,并且识别出来的结果要可复制可布局。本人改造的项目结构如下:
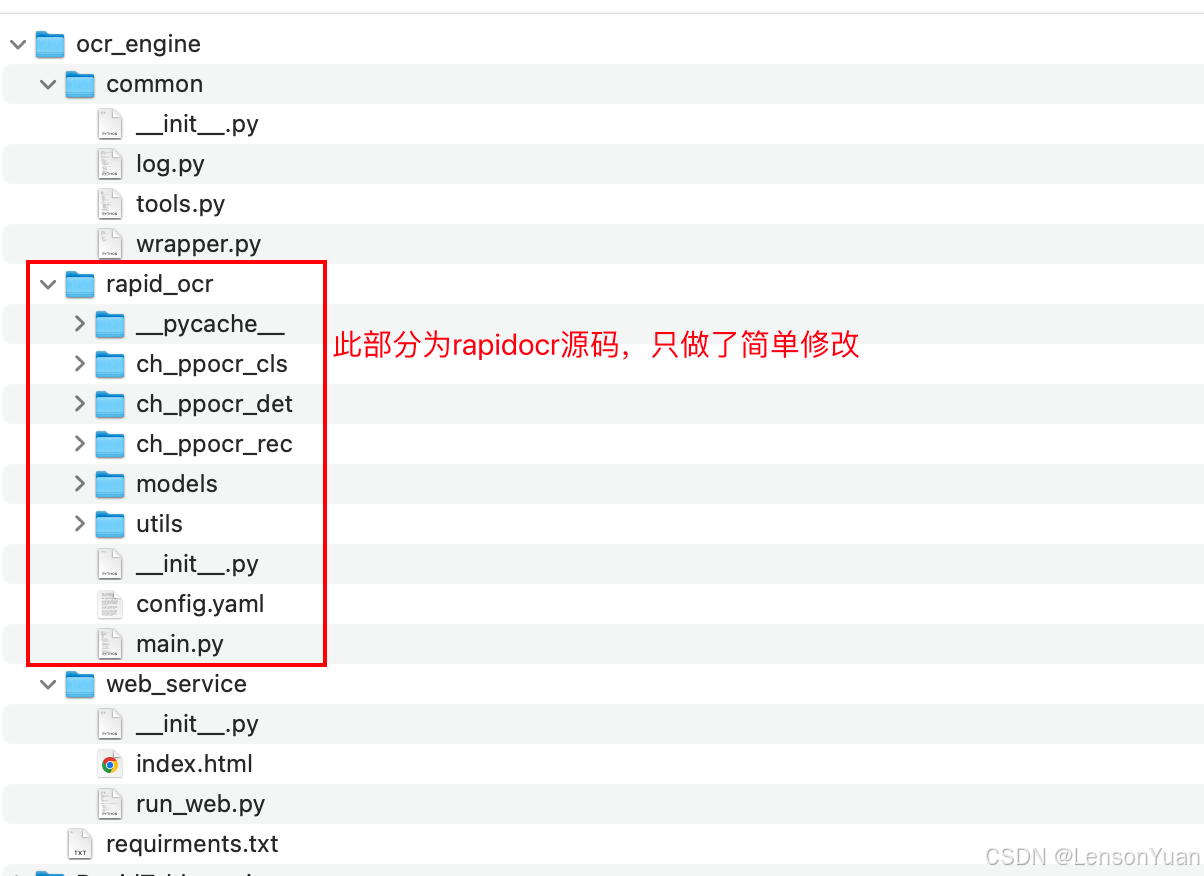
其中,common是依赖的一些工具,实现了识别结果转html、接口应对不同类别的图片输入等。我们需要运行web_service/run_web.py文件,即可启动api服务,接口信息如下:
- 地址:localhost:5001/engine/ocr
- 入参:threshold、image
- 响应json:{‘code’: 200, ‘info’: ‘success’, ‘data’: “html字符串”}
- 直接看run_web.py代码:
# -*- encoding: utf-8 -*-
"""
@File : run_service.py
@Description : None
@Author : 一只特立独行的羱
@Contact : 未知
@License : (C)Copyright 2019-2030,xx
@Modify Time @Version
------------ --------
2024/11/26 15:36 1.0
"""
import uvicorn
from fastapi import FastAPI, Form, File, UploadFile
from fastapi.middleware.cors import CORSMiddleware
from typing import Union
from rapid_ocr import RapidOCR
from common.tools import get_pil_images_in_anyway, boxes_generate_html
# ocr 引擎
_engine = RapidOCR()
# api对象
app = FastAPI()
# 添加CORS中间件
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 允许所有源,也可以指定具体的源
allow_credentials=True,
allow_methods=["*"], # 允许所有方法
allow_headers=["*"], # 允许所有头
)
@app.post('/engine/ocr/')
async def engine_ocr(
threshold: float = Form(default=0.6, description='可选参。识别返回的置信度阈值,默认0.6'),
image: Union[str, UploadFile] = File(..., description='必要参。待识别的图片,支持二进制格式、base64位图片字符串、http图片地址、服务器资源地址')
):
resp = {'code': 200, 'info': 'success', 'data': ""}
if image is None:
resp['code'] = 201
resp['info'] = '请求参数异常'
else:
img = get_pil_images_in_anyway(image)
try:
# 识别图片带框位置
ocr_result = _engine(img, text_score=threshold)
# 提取框boxes和标记文本
rectangles = [(i[0], i[1]) for i in ocr_result[0]]
# 生成HTML
html = boxes_generate_html(rectangles)
resp['data'] = html
# resp['data'] = json.dumps(rs, default=json_serializable, ensure_ascii=False)
print('response success.')
except Exception as e:
print(f"failed response:{repr(e)}")
resp['code'] = 202
resp['info'] = repr(e)
return resp
if __name__ == '__main__':
uvicorn.run(app, host='0.0.0.0', port=8001, workers=1)
3.3 示例demo页面
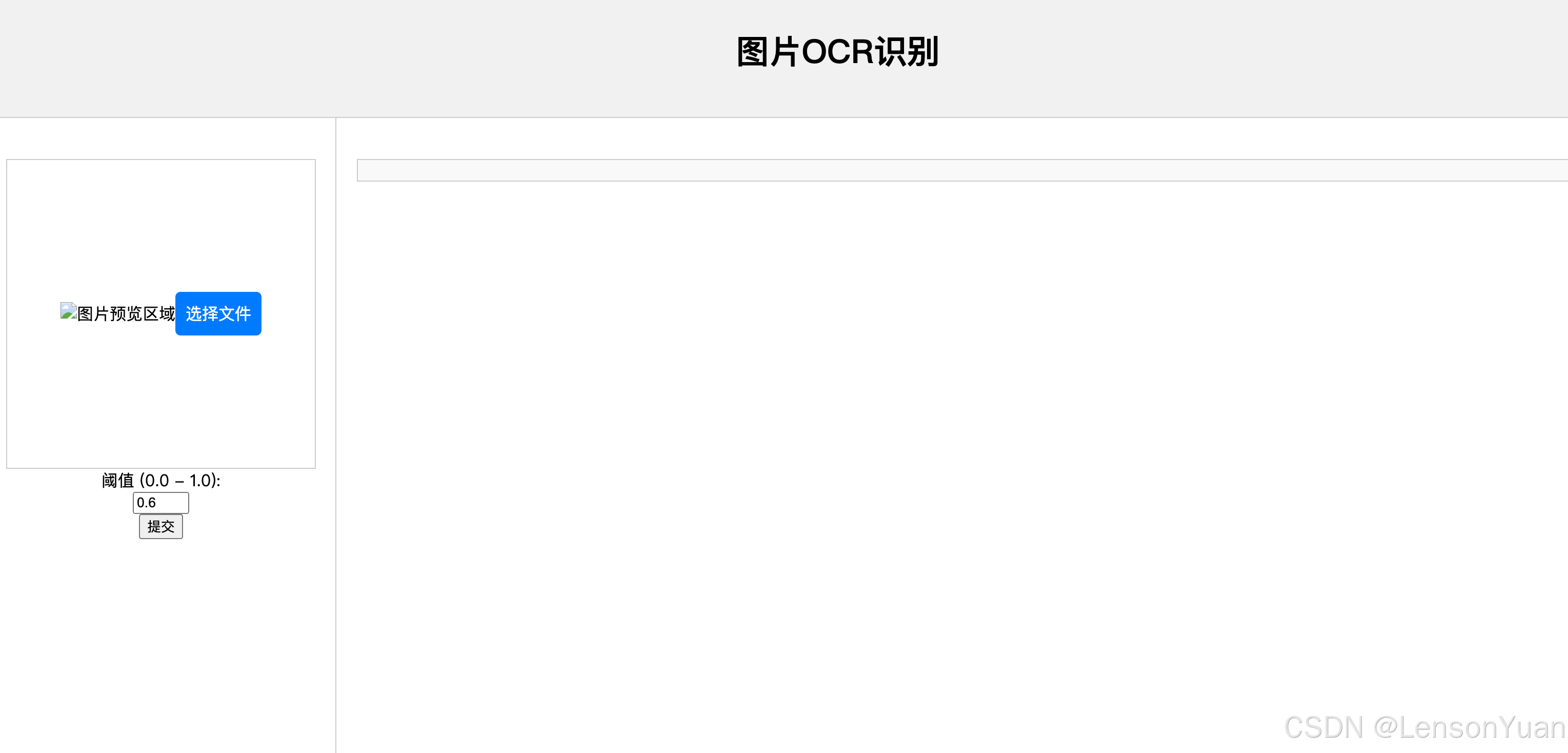
当启动了接口服务后,我们可以浏览器打开index.html文件,即可进行简单测试效果。(仅供测试,页面做的很简陋哈)
- 输入页面:
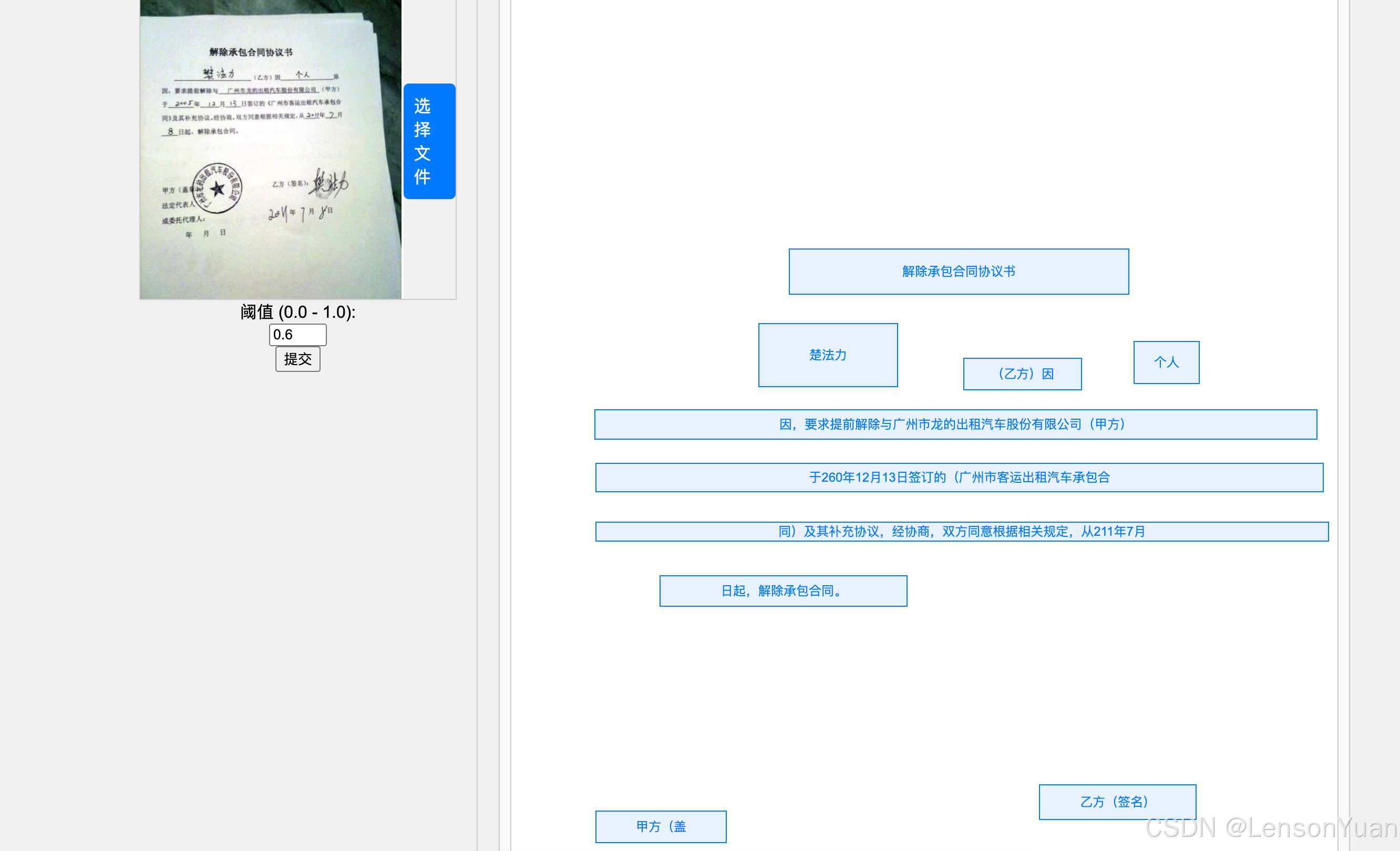
- 识别结果页面:【右边其实就是嵌入的html文件】
结语
下载项目改造的源码,一键运行。实现返回html,识别结果的布局和原始图片类似、文字可自由复制。



















 456
456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











