







少样本机器学习(Few-Shot Learning):CAML算法代码实现与教学
引言
在机器学习领域,少样本学习(Few-Shot Learning, FSL)是一个备受关注的研究方向。与传统的监督学习不同,少样本学习旨在通过极少量的标注数据来训练模型,使其能够在新的类别上表现良好。这种能力对于那些标注数据稀缺或获取成本高昂的应用场景尤为重要。
本文将深入探讨少样本学习的核心概念,并重点介绍一种名为CAML(Context-Aware Meta-Learning的算法。我们通过改造原作者的代码,并进行扩展使用。
一、少样本学习常识概念
1.1 少样本学习要点
少样本学习是一种机器学习范式,其目标是通过极少量的训练样本(通常是每个类别1到5个样本)来学习一个模型,使其能够在新的类别上进行泛化。与传统的监督学习不同,少样本学习不需要大量的标注数据,因此非常适合那些数据稀缺的场景。
1.2 N-way K-shot
N-way K-shot 是机器学习和深度学习中用于描述小样本学习(Few-Shot Learning)任务的一个术语。它通常用于元学习(Meta-Learning)或小样本分类任务中。
-
N-way: 表示在任务中有多少个类别(或类别数)需要进行分类。例如,如果任务是 “5-way”,那么模型需要在5个不同的类别中进行分类。
-
K-shot: 表示每个类别中有多少个样本(或示例)用于训练或测试。例如,如果任务是 “5-shot”,那么每个类别有5个样本。
-
N-way K-shot 表示在一个任务中,模型需要在N个类别中进行分类,每个类别有K个样本。
在少样本学习(Few-Shot Learning)中,支持集(Support Set)和查询集(Query Set)是两个关键的概念,它们用于训练和评估模型在有限样本情况下的学习能力。
1.3 支持集(Support Set)
支持集是用于提供模型学习所需信息的样本集合。它通常包含少量(即“少样本”)的标记数据,这些数据用于帮助模型识别和理解特定任务或类别。支持集的规模通常很小,可能只有几个样本(例如,每个类别只有1到5个样本)。
- 组成:支持集由多个类别的样本组成,每个类别通常有少量样本。
- 作用:支持集用于模型学习如何区分不同的类别。在训练过程中,模型通过支持集来学习类别的特征和模式。
1.4 查询集(Query Set)
查询集是用于测试模型性能的样本集合。它包含未标记的样本,模型需要根据从支持集中学到的知识来对这些样本进行分类或预测。
- 组成:查询集通常包含与支持集相同类别的样本,但模型之前没有见过这些样本。
- 作用:查询集用于评估模型在少样本情况下的泛化能力。模型需要根据支持集中的少量样本,对查询集中的样本进行正确的分类。
二、 图像分类算法CAML
CAML(Context-Aware Meta-Learning)是一种基于元学习的少样本学习算法。CAML通过引入上下文感知的机制,实现小样本图像的识别分类。CAML的核心思想是通过元学习的方式,学习一个能够在少量数据上快速适应的模型。CAML的核心要点(原理细节可以点此看我空间另一文章):
- 适合少样本:CAML算法可以支持每个类别个位数的图片,当前已训练好的模型,支持5个及以下(way<=5)类别的图像分类。
- 可动态加载support样本:在推理过程中,把支持集(Support Set)实时编码进上下文。
- 上下文感知:CAML通过引入上下文感知的机制,进一步提升了模型的表现。
- 效果表现靠前:在2024年排行榜里,少样本图像分类榜单中,排前三,开源中排第一。(详细对比点此看我另一篇文章)
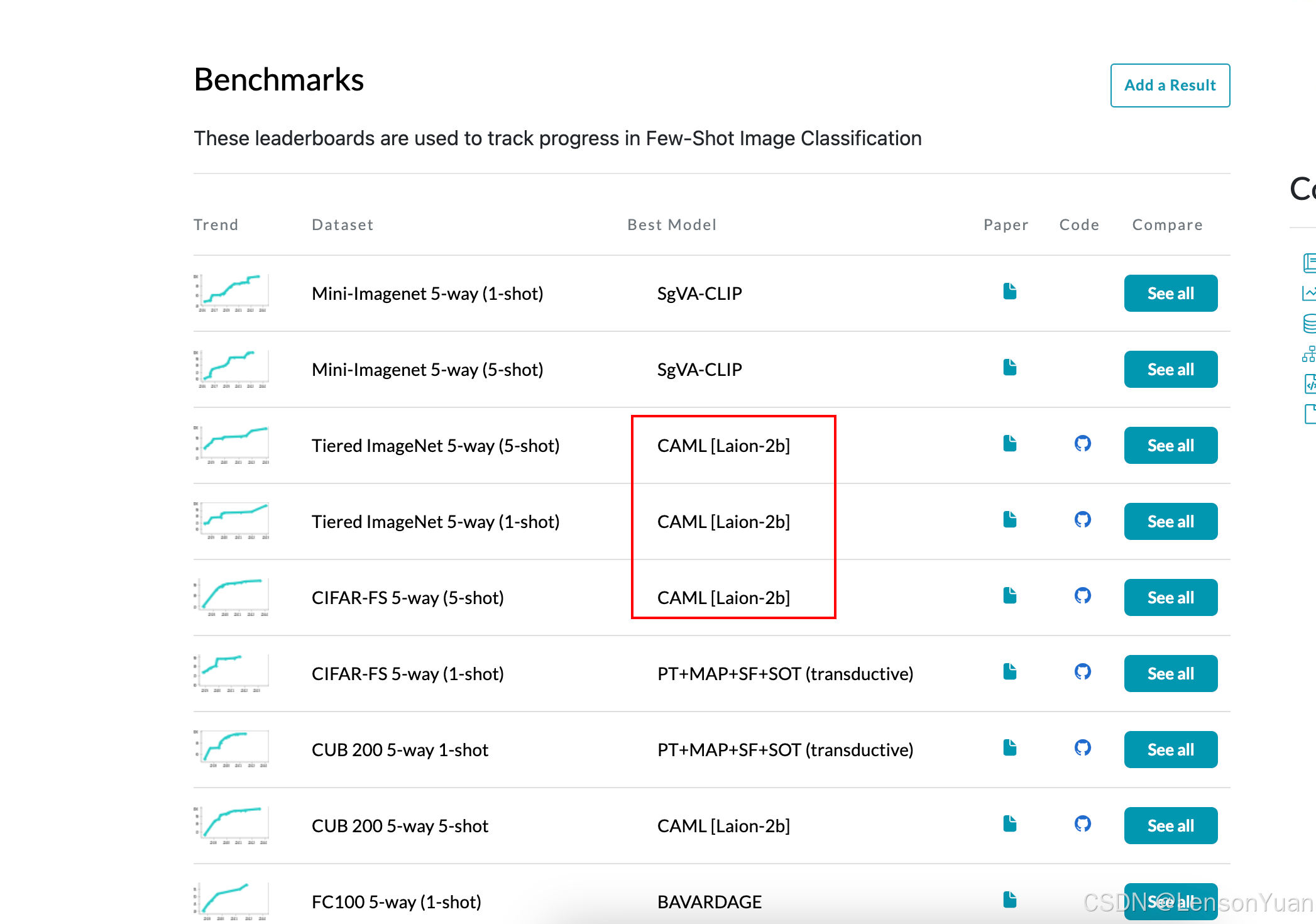
三、CAML代码实现
1.1 CAML源码预览
首先,我们看下原作者的代码,为了方便演示讲解,按当前时间我进行了代码克隆。克隆后的代码仓库如下:
https://github.com/1148270327/CAML
截图如下:
1.2 CAML源码BUG与不足
- 不足:通过命令行传递调用evaluation/test.py
python src/evaluation/test.py --model CAML --gpu 4 --eval_dataset pascal_paintings --fe_type timm:vit_base_patch16_clip_224.openai:768
- bug:evaluation/utils.py第18行代码错误,修改如下:
if args.model == 'CAML':
if 'openai' in args.fe_type:
model_path = 'caml_pretrained_models/CAML_CLIP/model.pth'
elif 'laion' in args.fe_type:
model_path = 'caml_pretrained_models/CAML_Laion2b/model.pth'
elif 'resnet' in args.fe_type:
model_path = 'caml_pretrained_models/CAML_ResNet34/model.pth'
- 不足:大部分人无法运行代码,存在以下问题:
- huggface的timm模型无法在线下载。
- 已训练的CAML模型文件,在google网盘,无法下载。
- 代码没有实现推理,只有对数据集做自动化评估,而且是对1-5shot的多个评估。
- 支持集、查询集都是随机抽取的,无法进行固定测试。
- 代码不全,而且数据集dataset格式各一。
1.2 CAML核心源码位置讲解
python src/evaluation/test.py --model CAML --gpu 4 --eval_dataset pascal_paintings --fe_type timm:vit_base_patch16_clip_224.openai:768
对该执行传参的解析:
- model CAML: 调用models/CAML.py,除了这个,还有元学习算法中的原型网络等。
- gpu 4: Pytorch指定显卡调用, 类似字符串device=torch.device(“cuda:4”)。
- eval_dataset 就是指定评测集的格式,和什么公开集标注一样的方式去加载自己的支持集。
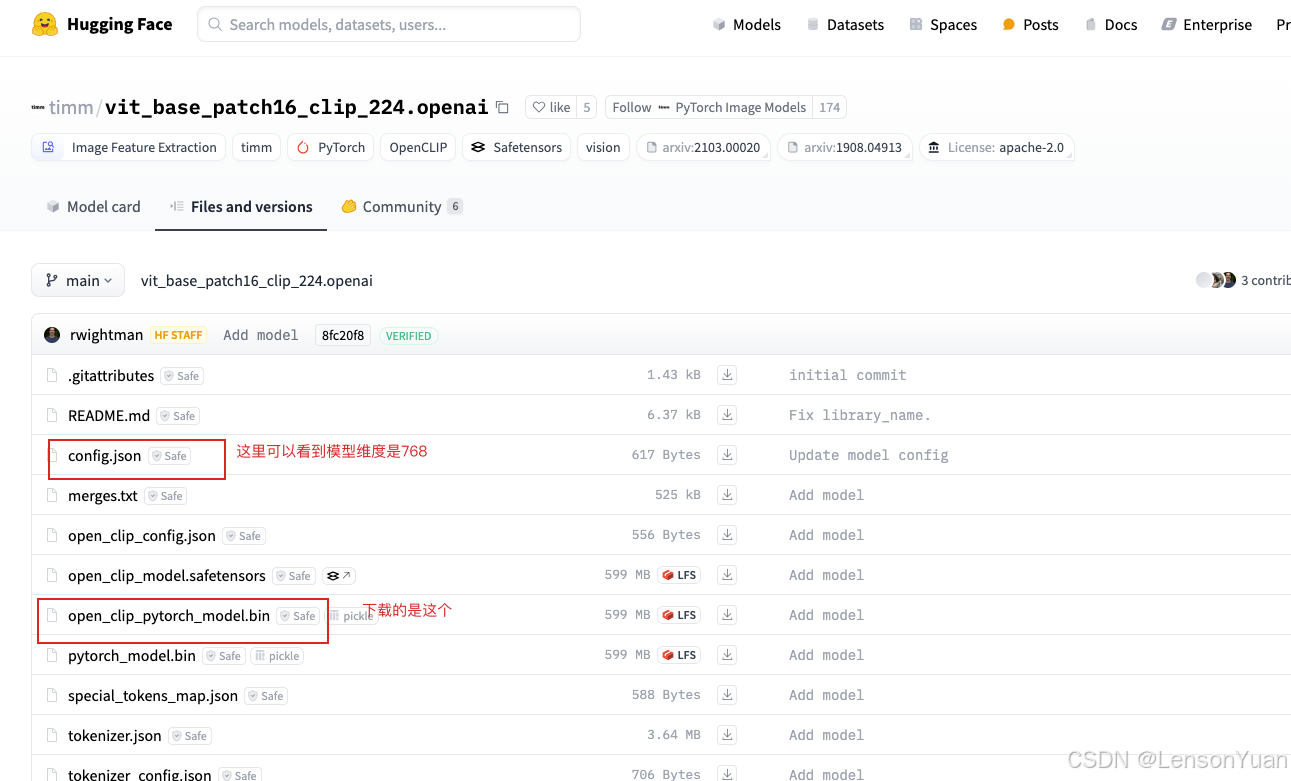
- fe_type timm:vit_base_patch16_clip_224.openai:768 :这个是通过字符串在代码里做切割,主要用于输入图像的特征编码,包括编码和Transform操作。里面涵盖了几个信息,从timm库里下载“vit_base_patch16_clip_224.openai”这个模型文件,而768是模型的维度,其实就是下载的timm库模型文件的dim,一般在模型文件下载链接的config.json中有标记。huggface截图如下:
对evaluation/test.py代码分析如下(看注释):
# 核心代码注释
if __name__ == '__main__':
#命令行传参过来的内容,默认设置5个类别
way = 5
args = train_parser()
# 这部分忽略
strict = forward_method = False
if 'Finetune' in args.model:
forward_method = True
# 通过传过来的参数,加载timm库中的模型,返回特征抽取器、图像变换操作、维度等
fe_metadata = get_fe_metadata(args)
# 这个其实就是拿测试集的真实数据路径
test_path = get_test_path(args, data_path)
#设置GPU
device = torch.device(f'cuda:{args.gpu}')
# 加载CAML模型的框架
model, model_path = get_model(args, fe_metadata, device)
if model_path:
# 模型中灌入训练好的CAML模型参数,模型是在way=5下训练的。
model.load_state_dict(torch.load(model_path, map_location=f'cuda:{args.gpu}'), strict=strict)
# 启用评估,和数据移入gpu
model.to(device)
model.eval()
with torch.no_grad():
# 每个类别下的样本数,从1-5张图,后面支持集和查询集都是随机抽取的。
for shot in [5, 1]:
mean, interval = meta_test(
data_path=test_path,
model=model,
way=way,
shot=shot,
pre=False,
transform_type=fe_metadata['test_transform'],
trial=10000, # 重复10000次进行测试
use_forward_method=forward_method)
print('%d-way-%d-shot acc: %.3f\t%.3f' % (way, shot, mean, interval))
timm库模型下载代码在feature_extractors/pretrained_fe.py(看代码注释)
def get_timm_model(model_name, model_type, dtype=None):
# model types that only rely on fixed pretrained backbones
if model_type in ['CAML', 'MetaQDA', 'SNAIL'] or 'ICL' in model_type:
if 'clip' in model_name:
# timm模型联网下载位置
model = timm.create_model(model_name,
pretrained=True,
img_size=224,
num_classes=0).eval()
评估数据集抽样部分在datasets/dataloaders.py(看代码注释):
def meta_test_dataloader(data_path, way, shot, pre, transform_type=None, query_shot=16, trial=1000):
dataset = get_dataset(data_path=data_path, is_training=False, transform_type=transform_type, pre=pre)
loader = torch.utils.data.DataLoader(
dataset,
#随机抽取函数
batch_sampler=samplers.random_sampler(data_source=dataset, way=way, shot=shot, query_shot=query_shot, trial=trial),
num_workers=3,
pin_memory=False)
return loader
CAML算法评估调用在models/CAML.py(看代码注释)
def meta_test(self, inp, way, shot, query_shot):
"""For evaluating typical Meta-Learning Datasets."""
# 通过timm下载的模型,对输入集进行特征编码
feature_vector = self.get_feature_vector(inp)
# 按比例划分支持集和查询集
support_features = feature_vector[:way * shot]
query_features = feature_vector[way * shot:]
b, d = query_features.shape
# 支持集向量和查询集向量进行拼接,组成上下文
support = support_features.reshape(1, way * shot, d).repeat(b, 1, 1) # 平铺向量并按查询集数进行重复
query = query_features.reshape(-1, 1, d) # 平铺
feature_sequences = torch.cat([query, support], dim=1) # 拼接
# 其实就是按输入数据集,每条数据的编号就是类别,比如5way4shot,那class就是0-20,比如0000,1111,2222....
labels = torch.LongTensor([i // shot for i in range(shot * way)]).to(inp.device)
# way和shot其实没调用。输入就是上下文和标签。输出类别概率向量
logits = self.transformer_encoder.forward_imagenet_v2(feature_sequences, labels, way, shot)
_, max_index = torch.max(logits, 1)
return max_index
执行评估的代码在evaluation/eval.py(看代码注释):
def meta_test(
data_path,
model,
way,
shot,
pre,
transform_type,
query_shot=16,
trial=10000,
return_list=False,
use_forward_method=False,
):
eval_loader = dataloaders.meta_test_dataloader(
data_path=data_path,
way=way,
shot=shot,
pre=pre,
transform_type=transform_type,
query_shot=query_shot,
trial=trial)
target = torch.LongTensor([i // query_shot for i in range(query_shot * way)]).to(model.device)
acc_list = []
for i, (inp, _) in tqdm(enumerate(eval_loader)):
inp = inp.to(model.device)
support_labels = torch.arange(way).repeat(shot, 1).T.flatten().to(model.device)
if use_forward_method:
logits = model.forward(inp, support_labels, way=way, shot=shot)
_, max_index = torch.max(logits, 1)
else:
max_index = model.meta_test(inp,
way=way,
shot=shot,
query_shot=query_shot)
# 这就是统计打标签的准确率结果,类似与统计标签对错的比例
acc = 100 * torch.sum(torch.eq(max_index, target)).item() / query_shot / way
if i % 200 == 0:
print(f'acc at step {i}: {acc:.3f}')
acc_list.append(acc)
if return_list:
return np.array(acc_list)
else:
mean, interval = get_score(acc_list)
return mean, interval
三、本人改进并实现单样本推理的代码
接下来,基于源码存在的问题和不足,我们进行代码改造,使算法能根据输入的单张图片和支持集进行预测。
《篇幅太长,关注本人的博客"CAML算法代码的实现与教学(二)附源码下载"》点此跳转
总结
本文介绍了少样本学习的基本概念,并详细讲解了CAML算法的实现过程。讲解了算法原作者的代码问题和核心实现;
第二部分是,根据本人的实践,对源码进行改造并实现输入单图片进行样本类别预测。<链接地址>


















 2981
2981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











