






目录
一、逻辑回归介绍
逻辑回归(Logistic Regression)是一种用于解决二分类问题的统计学习方法,尽管名字中带有“回归”,但实际上它是一种分类算法。逻辑回归的图像特点主要体现在其决策边界和概率输出上。
1. 逻辑回归的应用场景
- 广告点击率
- 是否为垃圾邮件
- 是否患病
- 金融诈骗
- 虚假账号
看到上面的例子,我们可以发现其中的特点,那就是都属于两个类别之间的判断。逻辑回归就是解决二分类问题的利器
2. 逻辑回归的原理
初步思路:
找一个线性模型来由X预测Y
但是很明显,这样的函数图像是类似一条斜线,难以达到我们想要的(0或1)的取值
所以我们引入了一个特殊的函数:
sigmoid函数(逻辑函数)
公式
图像
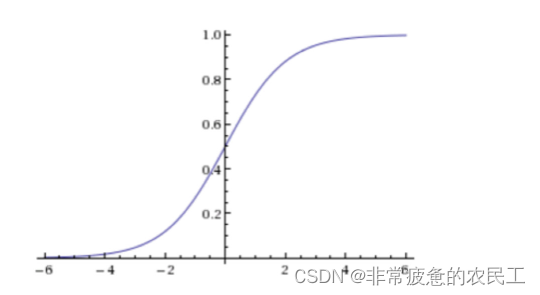
- 判断标准
- 回归的结果输入到sigmoid函数当中
- 输出结果:[0, 1]区间中的一个概率值,默认为0.5为阈值
逻辑回归最终的分类是通过属于某个类别的概率值来判断是否属于某个类别,并且这个类别默认标记为1(正例),另外的一个类别会标记为0(反例)。(方便损失计算)
刚刚的线性模型与Sigmoid函数合体
第一步:
第二步:
这样我们就把取值控制在了0或1上,初步达成了我们的目标。
输出结果解释:
假设有两个类别A,B,并且假设我们的概率值为属于A(1)这个类别的概率值。现在有一个样本的输入到逻辑回归输出结果0.55,那么这个概率值超过0.5,意味着我们训练或者预测的结果就是A(1)类别。那么反之,如果得出结果为0.3那么,训练或者预测结果就为B(0)类别。
关于逻辑回归的阈值是可以进行改变的,比如上面举例中,如果你把阈值设置为0.6,那么输出的结果0.55,就属于B类。
在之前,我们用最小二乘法衡量线性回归的损失
3.损失函数
为求出好的逻辑回归,引出损失函数 :
①损失函数是体现“预测值”和“真实值”,相似程度的函数
②损失函数越小,模型越好
逻辑回归的损失,称之为对数似然损失,公式如下:
if y=1
if y=0
其中y为真实值,为预测值
无论何时,我们都希望损失函数值,越小越好
分情况讨论,对应的损失函数值:
当y=1时,我们希望值越大越好;
当y=0时,我们希望值越小越好;
综合完整损失函数
4、逻辑回归的优缺点
1、优点
(1)适合分类场景
(2)计算代价不高,容易理解实现。
(3)不用事先假设数据分布,这样避免了假设分布不准确所带来的问题。
(4)不仅预测出类别,还可以得到近似概率预测。
(5)目标函数任意阶可导。
2、缺点
(1)容易欠拟合,分类精度不高。
(2)数据特征有缺失或者特征空间很大时表现效果并不好。
二、代码实现
1.导入模块和定义文件路径
from numpy import *
filename = r'D:\logistic\logistic_text.txt'
2.数据加载函数 loadDataSet
def loadDataSet():
data = []
label = []
fr = open(filename)
for line in fr.readlines():
lineArray = line.strip().split()
data.append([1.0, float(lineArray[0]), float(lineArray[1])])
label.append(int(lineArray[2]))
return data, label
这个函数从文件中读取数据和标签。每行数据被分割成三个部分:前两个是特征值,第三个是标签(类别)。特征值被转换为浮点数,标签被转换为整数。每个数据点还添加了一个额外的特征值1,用于计算截距
3.Sigmoid函数 sigmoid
def sigmoid(X):
return 1.0 / (1 + exp(-X))
激活函数,用于将任何实数映射到(0,1)区间
4.学习率 alpha
alpha = 0.001
学习率是梯度下降算法中的一个超参数,控制着权重更新的步长。
5.梯度计算函数 gradient
def gradient(weights, data, label):
dataMatrix = mat(data)
classLabels = mat(label).transpose()
h = sigmoid(dataMatrix * weights)
error = (classLabels - h)
q = -dataMatrix.transpose() * error
return q
这个函数计算了损失函数的梯度。它首先将数据和标签转换为矩阵形式,然后计算预测值h,接着计算误差error,最后计算梯度q。
6.梯度下降函数 gradient_Accent
def gradient_Accent(data, label):
m, n = shape(data)
weights = ones((n, 1))
q = gradient(weights, data, label)
while not all(absolute(q) <= 2e-5):
weights = weights - alpha * q
q = gradient(weights, data, label)
return weights
这个函数使用梯度下降法来更新权重。它初始化权重为1,然后在一个循环中不断更新权重,直到梯度的绝对值小于一个预设的阈值(这里设为2e-5)。
7.绘制决策边界函数 plotBestFit
def plotBestFit(weights): # 定义一个函数,用于画出最佳拟合线
import matplotlib.pyplot as plt # 导入matplotlib.pyplot,用于绘图
dataMat, labelMat = loadDataSet() # 加载数据集
dataArr = array(dataMat) # 将数据集转换为NumPy数组
n = shape(dataArr)[0] # 获取数据集中的样本数量
# 初始化两个空列表,用于存储两类数据的坐标
xcord1 = [];
ycord1 = []
xcord2 = [];
ycord2 = []
# 遍历数据集中的每个样本
for i in range(n):
# 根据标签将样本分为两类
if int(labelMat[i]) == 1:
xcord1.append(dataArr[i, 1]) # 如果是第一类,添加x坐标
ycord1.append(dataArr[i, 2]) # 如果是第一类,添加y坐标
else:
xcord2.append(dataArr[i, 1]) # 如果是第二类,添加x坐标
ycord2.append(dataArr[i, 2]) # 如果是第二类,添加y坐标
fig = plt.figure() # 创建一个新的图表
ax = fig.add_subplot(111) # 在图表中添加一个子图
# 绘制两类样本的散点图
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s') # 第一类样本,红色,形状为正方形
ax.scatter(xcord2, ycord2, s=30, c='green') # 第二类样本,绿色
# 创建一个x的数组,用于画出最佳拟合线
x = arange(-3.0, 3.0, 0.1)
# 使用逻辑回归模型的权重计算最佳拟合线的y值
y = (-weights[0] - weights[1] * x) / weights[2]
# 画出最佳拟合线
ax.plot(x, y)
plt.xlabel('X1') # 设置x轴标签
plt.ylabel('X2') # 设置y轴标签
plt.show() # 显示图表
这个函数用于绘制数据点和决策边界。它根据权重计算出决策边界,并将数据点根据类别用不同的颜色和标记绘制出来。
8.主函数 main
def main():
dataMat, labelMat = loadDataSet()
weights = gradient_Accent(dataMat, labelMat).getA()
plotBestFit(weights)
首先加载数据,然后使用梯度下降法找到最佳权重,并绘制出决策边界
9.运行主函数
if __name__ == '__main__':
main()
这部分代码确保当脚本直接运行时,主函数会被调用。如果脚本被作为模块导入,则不会执行这部分代码。
运行结果
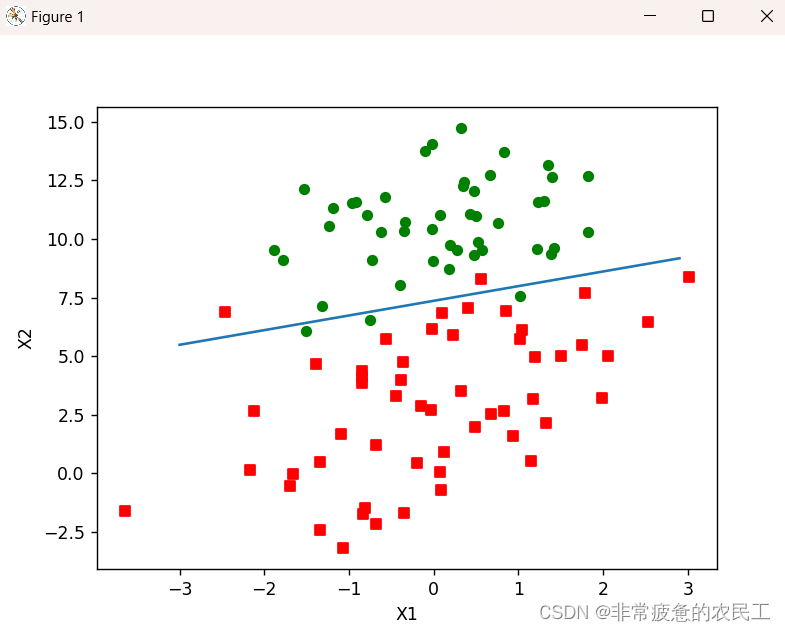
根据图像可以看出,图像中的数据点几乎都被最佳拟合线分隔开,并且两类数据点在图像中是很清晰地分离开的,那么这个模型的拟合效果是不错的。















 1802
1802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









