







目录
1.代码示例
加载了所需的库和模块
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn import metrics用pandas库读取Excel文件中的鸢尾花训练数据和测试数据
train_data = pd.read_excel("鸢尾花训练数据.xlsx")
test_data = pd.read_excel("鸢尾花测试数据.xlsx")在数据集中选择了特征和目标变量。这里,特征包括四个花瓣和萼片的尺寸,而目标变量是花的类型(通常被编码为数字)
train_X = train_data[['萼片长(cm)','萼片宽(cm)','花瓣长(cm)','花瓣宽(cm)']]
train_y = train_data['类型_num'] # 提取的是一列数据,因此它是pandas的Series类型初始化逻辑回归模型并使用训练数据进行拟合
model = LogisticRegression()
model.fit(train_X, train_y)用训练好的模型对训练集和测试集进行了预测。
train_predicted = model.predict(train_X)
test_x = test_data[['萼片长(cm)','萼片宽(cm)','花瓣长(cm)','花瓣宽(cm)']]
test_y = test_data['类型_num']
test_predicted = model.predict(test_x)用predict_proba方法获取测试集上每个样本属于各个类别的概率
test_predicted_pr = model.predict_proba(test_x)
# predict_proba返回的是一个二维数组,其中每一行对应一个样本,每一列对应一个类别的预测概率。使用metrics.classification_report来评估模型在测试集上的性能。这个函数会输出每个类别的精确度、召回率、F1分数和支持数
print(metrics.classification_report(test_y, test_predicted))读取另一个Excel文件,它包含一些需要进行预测的数据,用模型进行了预测,并打印了其中一个类别的预测概率(在这个例子中,是第二个类别的概率)
predicted_data = pd.read_excel("鸢尾花预测数据.xlsx")
pr_X = predicted_data[['萼片长(cm)','萼片宽(cm)','花瓣长(cm)','花瓣宽(cm)']]
predicted = model.predict(pr_X)
predicted_pr = model.predict_proba(pr_X)
print(predicted_pr[:, 1]) # 打印第二个类别的预测概率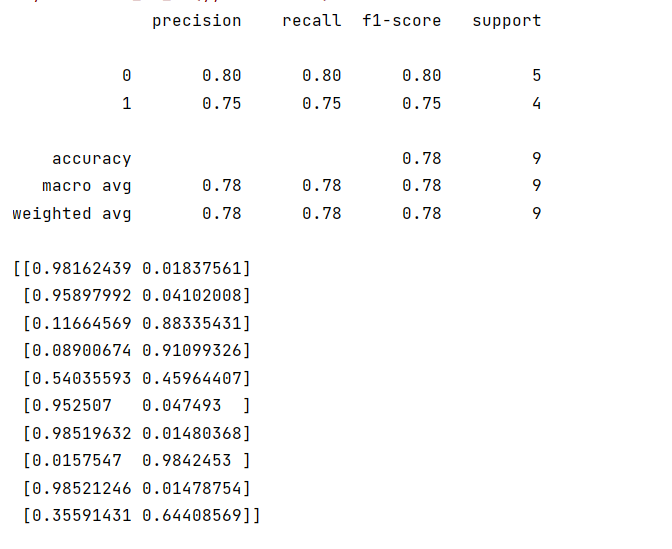















 200
200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









