







第四章 逻辑回归(Logistic Regression)
<假设表示(Hypothesis Representation) >
<决策边界(Decision Boundary)>
<代价函数(Cost Function)>
<简化的代价函数和梯度下降(Simplified Cost Function and Gradient Descent)>
<高级优化(Advanced Optimization)>
<多类别分类--一对多(Multiclass Classification:One vs All)>
1.分类(Classificstion)和假设表示(Hypothesis Representation)
首先,我们从二分类问题开始讨论,其中0表示负向类,1表示正向类。
回顾在一开始提到的乳腺癌分类问题,我们可以用线性回归的方法求出适合数据的一条直线:
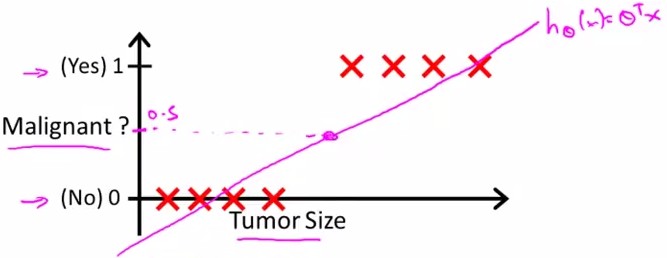
根据线性回归模型我们只能预测连续的值,然而对于分类问题,我们需要输出0或1,我们可以预测:
当hθ大于等于0.5时,预测y=1。
当hθ小于0.5时,预测y=0 。
对于上图所示的数据,这样的一个线性模型似乎能很好地完成分类任务。假使我们又观测到一个非常大尺寸的恶性肿瘤,将其作为实例加入到我们的训练集中来,这将使得我们获得一条新的直线。
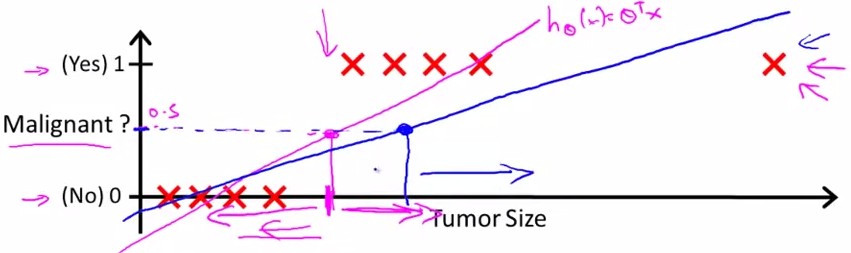
这时,再使用0.5作为阀值来预测肿瘤是良性还是恶性便不合适了。可以看出,线性回归模型,因为其预测的值可以超越[0,1]的范围,并不适合解决这样的问题。
我们引入一个新的模型,逻辑回归,该模型的输出变量范围始终在0和1之间。 逻辑回归模型的假设是:hθ(x)=g(θTX)
其中:
X 代表特征向量
g 代表逻辑函数(logistic function)是一个常用的逻辑函数为S形函数(Sigmoid function)。
具体信息如下图所示:
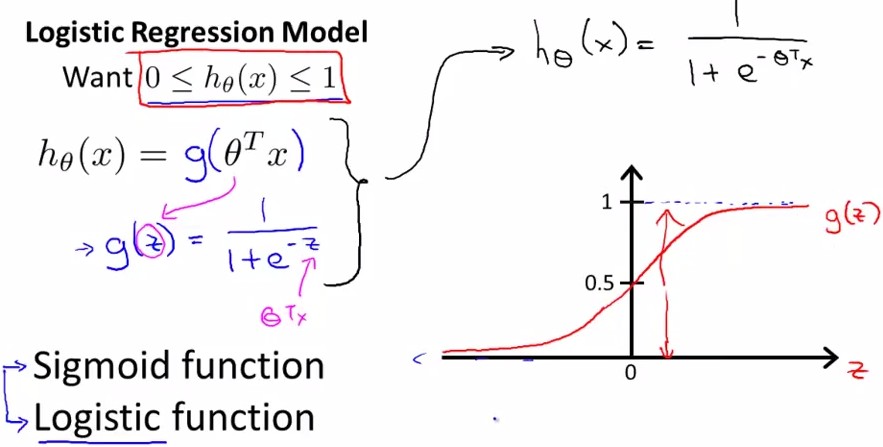
上图中的Sigmoid function 或者是Logistic function,就是这样一个函数g(z)。见上图所示。
当z>=0时,g(z)>=0.5;当z<0时,g(z)<0.5
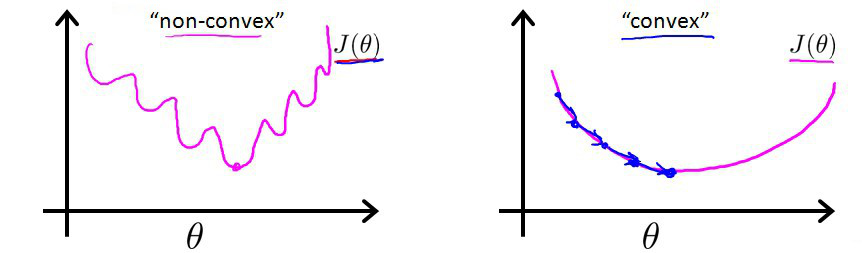
hθ(x)的作用是,对于给定的输入变量,根据选择的参数计算输出变量=1的可能性(estimated probablity)即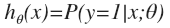
我们还可以得到如下关系:
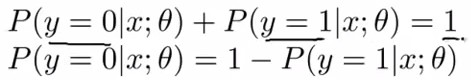
逻辑回归算法实际上是分类算法,我们不要收到“回归”二字的误导。它的性质就是:它的输出值永远在0到1之间。
2.决策边界(Decison Boundary)
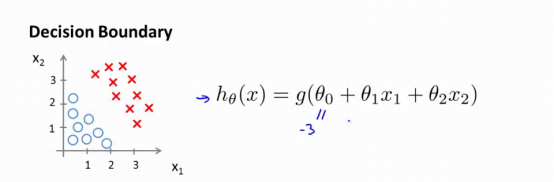
并且参数θ是向量[-3 1 1]。 则当-3+x1+x2 大于等于0,即x1+x2大于等于3时,模型将预测y=1。我们可以绘制直线x1+x2=3,这条线便是我们模型的分界线,将预测为1的区域和预测为0的区域分隔开。

下面我们来看另一个以半径为1的圆为分类边界的例子:

事实上,我们可以用非常复杂的模型来适应非常复杂形状的判定边界。而决策边界的目的就是要把属于不同类别的部分以最精确的方式区分开。
3.代价函数(Cost Function)
下面我们要介绍如何拟合逻辑回归模型的参数θ。具体来说,我要定义用来拟合参数的优化目标或者叫代价函数,这便是监督学习问题中的逻辑回归模型的拟合问题。
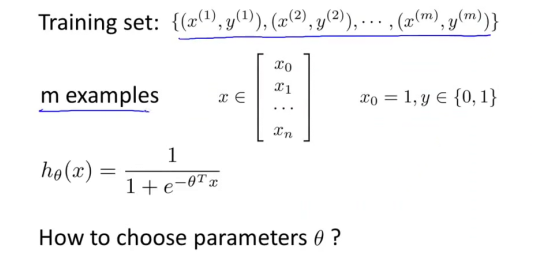
对于线性回归模型,我们定义的代价函数是所有模型误差的平方和。理论上来说,我们也可以对逻辑回归模型沿用这个定义,但是问题在于,当我们将hθ(x)带入到:
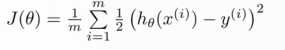
这样的代价函数中时,我们得到的代价函数将是一个非凸函数(non-convex function)。
这意味着我们的代价函数有许多局部最小值,这将影响梯度下降算法寻找全局最小值。
我们重新定义逻辑回归的代价函数为:

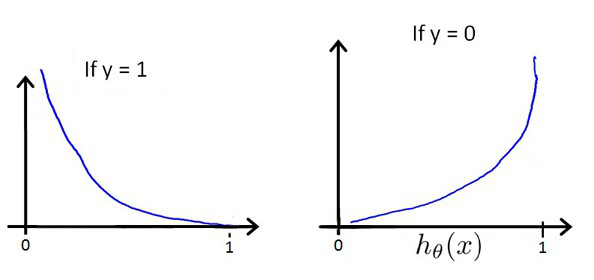
4.简化的代价函数和梯度下降(Simplified Cost Function and Gradient Descent)

注:虽然得到的梯度下降算法表面上看上去与线性回归的梯度下降算法一样,但是这里的 hθ(x)=g(θTX)与线性回归中不同,所以实际上是不一样的。
下面我们对求偏导的过程进行详细描述:
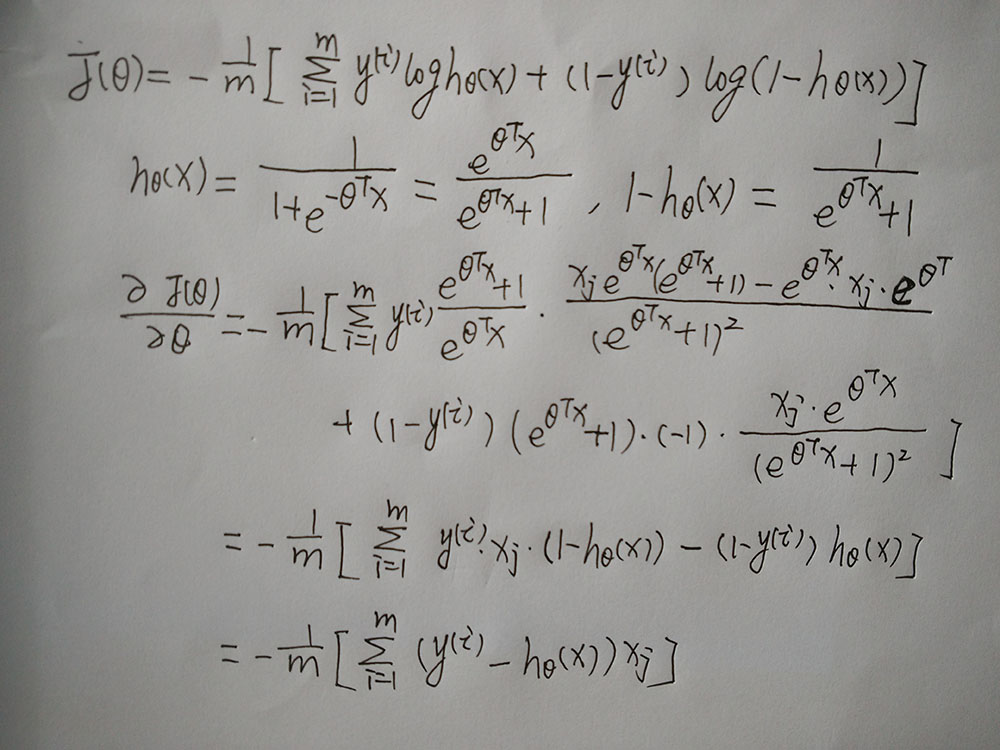
下面我们主要分析参数更新如何简单化。我们可以使用 for 循环来更新这些参数值,用 for i=0 to n,或者for i=1 to n+1。
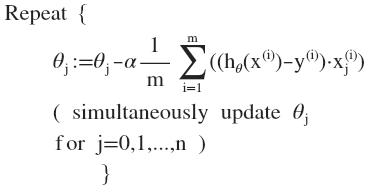
我们可以换种方式来表示。

那么如何能够 不使用for循环从而简化计算呢:上图也已经给出了答案。那就是使用向量化的方法。换言之,我们不要用for循环一个个更新θj,而用一个矩阵乘法同时更新整个θ。当然,如果你的特征范围差距很大的话,同样可以将特征缩放的方法应用到逻辑回归中,梯度下降收敛更快。
5.高级优化(Advanced Optimization)

Octave 有一个非常理想的库用于实现这些先进的优化算法,所以,如果你直接调用它自带的库,你就能得到不错的结果。因此现在让我们来说明如何使用这些算法。
举个例子。

你有一个含两个参数的问题,这两个参数是θ0 和θ1,因此,通过这个代价函数,你可以得到θ1 和 θ2的值,如果你将J(θ) 最小化的话,那么它的最小值将是θ1等于5 ,θ2 等于5。代价函数J(θ)的偏导数推出来就是上面两个表达式。如果我们不知道最小值,但你想要代价函数找到这个最小值,是用比如梯度下降这些算法,但最好是用比它更高级的算法,你要做的就是运行一个像这样的Octave函数:

这样就计算出这个代价函数,函数返回的第二个值是梯度值,梯度值应该是一个2×1的向量,梯度向量的两个元素对应这里的两个偏导数项,运行这个costFunction函数后,你就可以调用高级的优化函数,这个函数叫fminunc,它表示Octave里无约束最小化函数。调用它的方式如下:

你要设置几个 options,这个options变量作为一个数据结构可以存储你想要的options,所以GradObj和On,这里设置梯度目标参数为打开(on),这意味着你现在确实要给这个算法提供一个梯度,然后设置最大迭代次数,比方说100,我们给出一个θ 的猜测初始值,它是一个2×1的向量,那么这个命令就调用fminunc,这个@符号表示指向我们刚刚定义的costFunction函数的指针。如果你调用它,它就会使用众多高级优化算法中的一个,当然你也可以把它当成梯度下降,只不过它能自动选择学习速率α,你不需要自己来做。然后它会尝试使用这些高级的优化算法,就像加强版的梯度下降法,为你找到最佳的θ值。让我告诉你它在Octave里什么样:
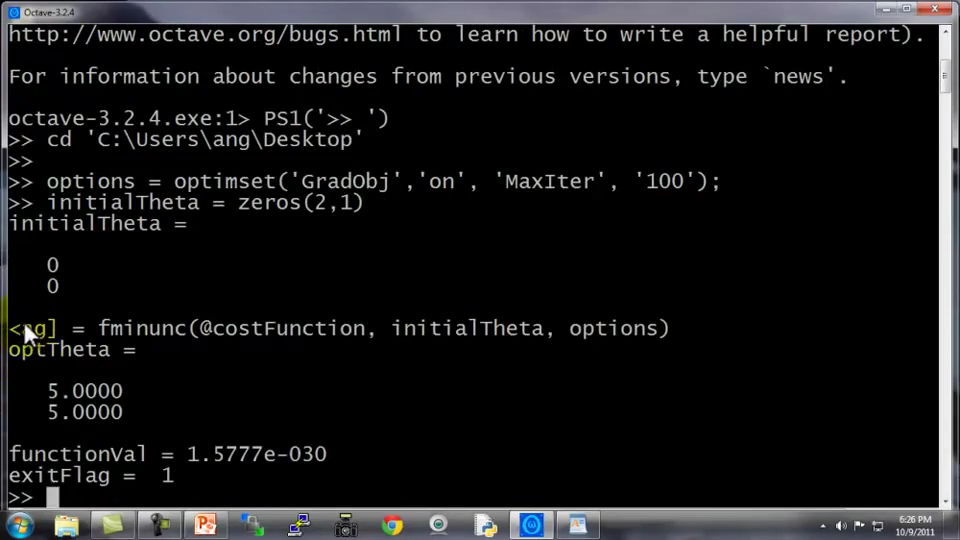
所以我写了这个关于theta的costFunction函数,它计算出代价函数jval以及梯度gradient,gradient有两个元素,是代价函数对于theta(1)和theta(2)这两个参数的偏导数。
从这里我们学到的主要内容是:写一个函数,它能返回代价函数值、梯度值,因此要把这个应用到逻辑回归,或者甚至线性回归中,你也可以把这些优化算法用于线性回归,你需要做的就是输入合适的代码来计算这里的这些东西。
现在你已经知道如何使用这些高级的优化算法,有了这些算法,你就可以使用一个复杂的优化库,它让算法使用起来更模糊一点。因此也许稍微有点难调试,不过由于这些算法的运行速度通常远远超过梯度下降。
所以当我有一个很大的机器学习问题时,我会选择这些高级算法,而不是梯度下降。有了这些概念,你就应该能将逻辑回归和线性回归应用于更大的问题中,这就是高级优化的概念。
6.多类别分类--一对多(Multicalss Classification:One vs All)
在这里,我们将谈到如何使用逻辑回归 (logistic regression)来解决多类别分类问题,具体来说,我们使用的是一个叫做"一对多" (one-vs-all) 的分类算法。所谓one-vs-all method就是将binary分类的方法应用到多类分类中。
具体来说,比如我想分成K类,那么就将其中一类作为positive正向类,另(k-1)合起来作为negative负向类,这样进行K个h(θ)的参数优化,每次得到的一个hθ(x)是指给定θ和x,它属于positive正向类的概率。
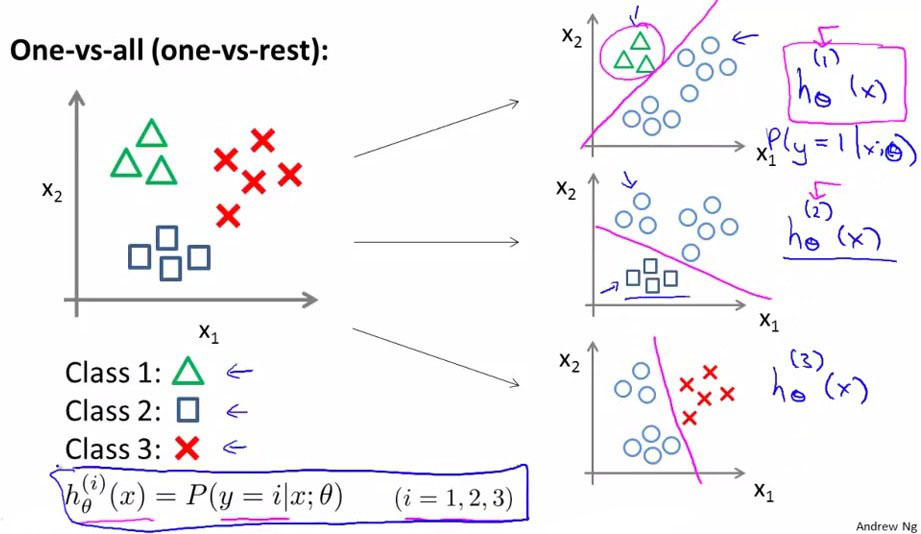
总之,我们已经把要做的做完了,现在要做的就是训练这个逻辑回归分类器: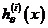
















 2038
2038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









