







LeetCode笔记:快速幂算法
自大学开始,我便陆陆续续的学习一些 算法和数据结构 方面的内容,同时也开始在一些平台刷题,也会参加一些大大小小的算法竞赛。但是平时刷题缺少目的性、系统性,最终导致算法方面进步缓慢。最终,为了自己的未来,我决定开始在LeetCode上进行系统的学习和练习,同时将刷题的轨迹整理记录,分享出来与大家共勉。
参考教材: labuladong
参考资料: LeetCode社区官方提供的思路/题解 以及 评论区/题解区各路大神提供的思路/答案
1.手写幂算法
算 x 的 n 次幂,使用累乘来编写代码:
res = 1
for i in range(n):
res *= x
好的,我们已经完成了 O(N) 的解法。
2.递归
利用幂运算的性质,我们可以写出这样一个递归式:
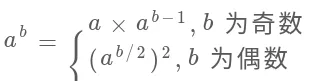
这个思想肯定比直接用 for 循环求幂要高效,因为有机会直接把问题规模(b的大小)直接减小一半,该算法的复杂度肯定是 log 级了。
那么就可以修改之前的mypow函数,翻译这个递归公式,再加上求模的运算:
int base = 1000;
int mypow(int a, int k) {
if (k == 0)
return 1;
a %= base;
if (k % 2 == 1) {
// k 是奇数
return (a * mypow(a, k - 1)) % base;
} else {
// k 是偶数
int sub = mypow(a, k / 2);
return (sub * sub) % base;
}
}
3.二进制拆分
为了优化这个算法,我们接下来进行数学推导:
我们继续思考当 N = 10 这个具体场景,我们可以把 10 写成二进制来表示 1010(BIN),然后我们模拟一次二进制转十进制的过程(复习一下大学知识):
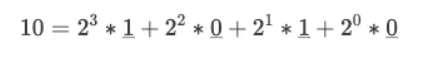
我用下划线把二进制的 1010 标识出来,这样大家就可以发现二进制和十进制转换时的代数式规律。
继续回想刚才的场景,那么我们求 x 的 10 次幂,则式子我们可以写成这样:
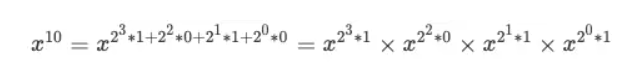
我们按照二进制低位到高位从左往右交换一下位置:
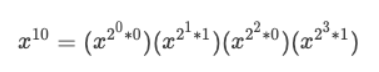
我们关注相邻的两项,如果我们不考虑幂指数的 *0 和 *1 ,我们只看前半部分,会发现有这么一个规律:
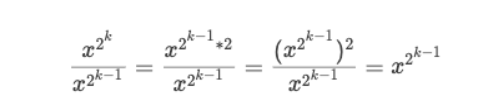
也就是说,不考虑幂指数的 *0 和 *1 右式,左式每次只要每次乘以自身,就是下一项的左式。在我们的例子中其实就是:

用编程思维来考虑这个问题,只要我们从 x 开始维护这么一个左式,每一次迭代都执行 x *= x,然后每次遇到右边是 *1 的情况,就记录一下 res *= x 是不是就能模拟咱们二进制拆分的计算思路了呢?
是不是发现非常的简单!我们至此已经实现了快速幂算法。我们将 n, x 做成参数,编写一个快速幂的方法:
int qpow(int x, int n) {
int res = 1;
while (n) {
if (n & 1) res *= x;
x *= x;
n >>= 1;
}
return res;
}
复杂度
通过上面对幂指数的拆分,发现快速幂只需要循环拆分的项数就可以完成整个幂运算。
我们不妨设求 x 的 N 次方,并且令 x 的所有二进制位都为 1,就可以得到下面这个等式:
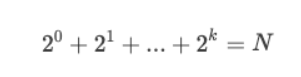
那么其实,k 就是计算机需要计算的次数,也就是时间复杂度。套入公比是 1 的等比数列前 k 项和来反推 k 的大小:
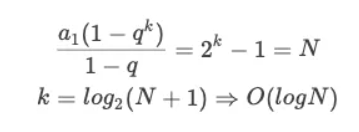
4.力扣题解
372. 超级次方
难度中等100收藏分享切换为英文接收动态反馈
你的任务是计算 ab 对 1337 取模,a 是一个正整数,b 是一个非常大的正整数且会以数组形式给出。
示例 1:
输入:a = 2, b = [3]
输出:8
示例 2:
输入:a = 2, b = [1,0]
输出:1024
示例 3:
输入:a = 1, b = [4,3,3,8,5,2]
输出:1
题解:java
class Solution {
int mu = 1337;
public int superPow(int a, int[] b) {
LinkedList<Integer> list = new LinkedList<Integer>();
for(int bb:b){
list.add(bb);
}
return superP(a,list);
}
public int superP(int a, LinkedList<Integer> list){
if(list.isEmpty()){
return 1;
}
int last = list.peekLast();
list.pollLast();
int res1 = quickMul(a,last);
int res2 = quickMul(superP(a,list),10);
return res1*res2%mu;
}
public int quickMul(int a, int n){
if(n == 0){
return 1;
}
a %= 1337;
int ans = 1;
int x = a;
while(n>0){
if(n % 2 == 1){
ans = ans*x%mu;
}
x = x*x%mu;
n /= 2;
}
return ans%mu;
}
}















 892
892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









