






前两周StableDiffusion WebUI1.6.0发布了,新增了很多对SDXL生态的支持。
而ControlNET也对SDXL的支持也逐渐稳定。
SDXL的生态终于有一点起色了,我也觉得是时候,可以来写一篇SDXL的大模型推荐了。
在推荐之前,以免大家混淆,所以这里再做一个简单的小科普:
现在的所有的SD的大模型,都是基于stability.ai发布的开源模型Stable Diffusion进行微调的,而Stable
Diffusion本身有很多个版本。
对,有这么多,但是基本都没人玩,只有SD1.5屹立不倒,你不管在Civitai还是一些其他的模型站上,99%都是把SD1.5当底座进行微调或者融合的。
而SDXL1.0是今年7月新发布的大模型,参数量比SD1.5大将近7倍,语言模型也“抄”了OpenAI的CLIP可以写大长句,他的上限比SD1.5高太多太多了。
现在,就来盘点一些,很棒的基于SDXL1.0微调出来的模型。

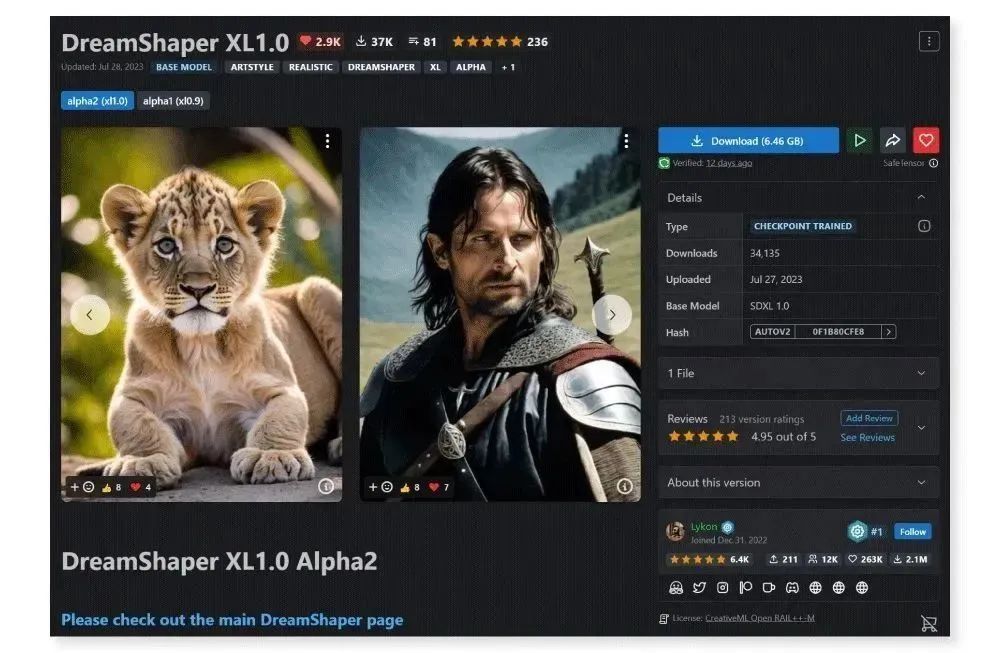
1.DreamShaper XL1.0
熟悉 SD WebUI 的小伙伴应该对 DreamShaper 不陌生,它是一款非常全能的写实风大模型,出图质量很高。此次 SDXL 1.0
更新后,DreamShaper 的制作者也进行了同步模型优化,于是就产生了 DreamShaper XL1.0 模型。它在图像生成质量、清晰度上比基于 SD
1.5 训练的 DreamShaper 模型更优秀。
-
类型:大模型(安装路径:根目录 models\Stable-diffusion)
-
注意事项:显存小于或低于 8G 时,需要开启显存要优化;
图像尺寸不低于 768*768px
参考数值:
-
正向提示词:photo of the warrior Aragorn from Lord of the Rings, film grain, 8k hd
-
负向提示词:Negative prompt: (deformed iris, deformed pupils), text, worst quality, low quality, uglySteps: 40, Seed: 17748028598464,
-
大模型:DreamShaperXL1.0Alpha_half
-
尺寸:768*1024 px
-
采样器:DPM++ 2S a Karras
-
CFG scale: 8
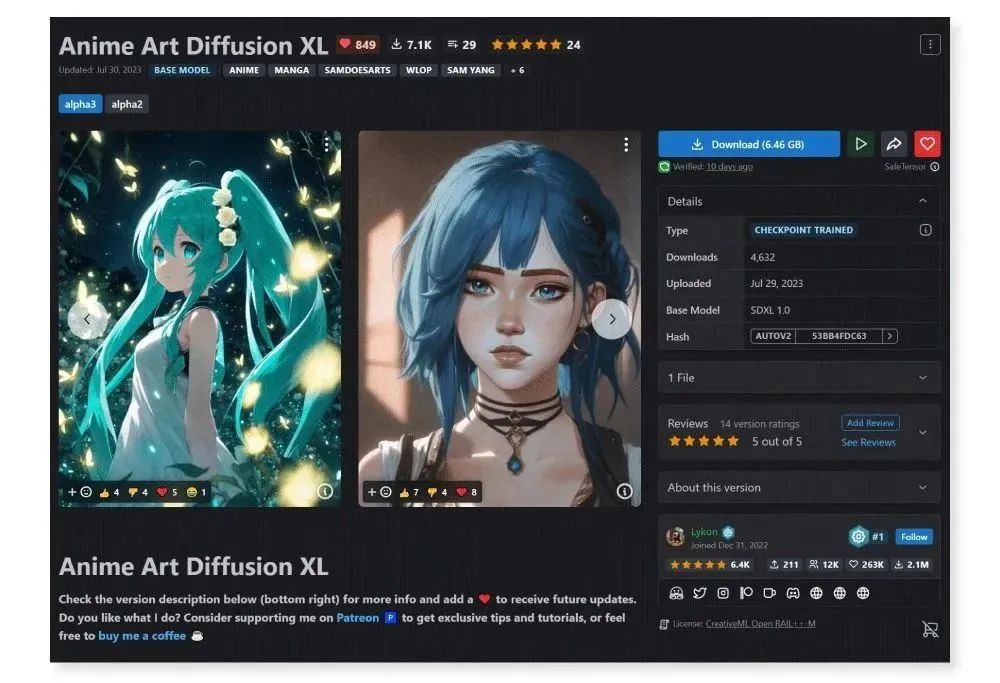
2.Anime Art Diffusion XL
Anime Art Diffusion XL 是基于 SDXL 1.0 专门训练的动漫风模型,可以生成精致 2D 及 3D 动漫风图像,也适合作为未来其他
Lora 模型的基础模型。
-
类型:大模型(安装路径:根目录 models\Stable-diffusion)
-
注意事项:显存小于或低于 8G 时,需要开启显存要优化;
图像尺寸不低于 768*768px;使用 8k 和 high resolution 这样的词汇
细节会更丰富
参考数值:
-
正向提示词:face focus, masterpiece, best quality, 1girl, , white roses, petals, night background, fireflies, light particle, solo, standing, pixiv, depth of field, cinematic composition, best lighting, looking up
-
反向提示词:(low quality, worst quality:1.2), 3d, watermark, signature, ugly, poorly drawn
-
大模型:animeArtDiffusionXL_alpha3
-
生成步数:35
-
宽度:768*1024 px
-
采样器:DPM++ 2S a Karras
-
CFG scale:10
3.Mysterious - SDXL
Mysterious - SDXL 是基于 SDXL 1.0
训练的一款奇幻风格大模型,出图质量高且非常稳定性。东西方奇幻风都可以生成,在赛博朋克、奇幻生物、3D 游戏人物上的效果也不错。
-
类型:大模型(安装路径:根目录 models\Stable-diffusion)
-
注意事项:显存小于或低于 8G 时,需要开启显存要优化;
图像尺寸不低于 768*768px

参考数值:
-
正向提示词:(mysterious:1.3), ultra-realistic mix fantasy,(1 giant eastern dragon:1.3) (behind an asian woman holding a glowing sword:1.1),void energy diamond sword, in the style of dark azure and light azure, mixes realistic and fantastical elements, vibrant manga, uhd image, glassy translucence, vibrant illustrations, ultra realistic, long hair, straight hair, white hair,head jewelly, jewelly, shawls,light In eyes, red eyes, portrait, firefly, mysterious, fantasy, cloud, abstract, colorful background, night sky, flame, very detailed, high resolution, sharp, sharp image, 4k, 8k, masterpiece, best quality, magic effect, (high contrast:1.4), dream art, diamond, skin detail, face detail, eyes detail, mysterious colorful background, dark blue themes
-
反向提示词:(worst quality:1.5), (low quality:1.5), (normal quality:1.5), lowres, bad anatomy, bad hands, multiple eyebrow, (cropped), extra limb, missing limbs, deformed hands, long neck, long body, (bad hands), signature, username, artist name, conjoined fingers, deformed fingers, ugly eyes, imperfect eyes, skewed eyes, unnatural face, unnatural body, error, painting by bad-artistlayman work, worst quality, ugly, (deformed|distorted|disfigured:1.21), poorly drawn, bad anatomy, wrong anatomy, mutation, mutated, (mutated hands AND fingers:1.21), bad hands, bad fingers, loss of a limb, extra limb, missing limb, floating limbs, amputation, Yaeba, photo, deformed, black and white, realism, disfigured, low contrast
-
大模型:[Lah]-Mysterious-V2.95
-
生成步数:50
-
尺寸:768*1080px
-
采样器:DPM++ 2M SDE Karras
-
CFG scale: 9
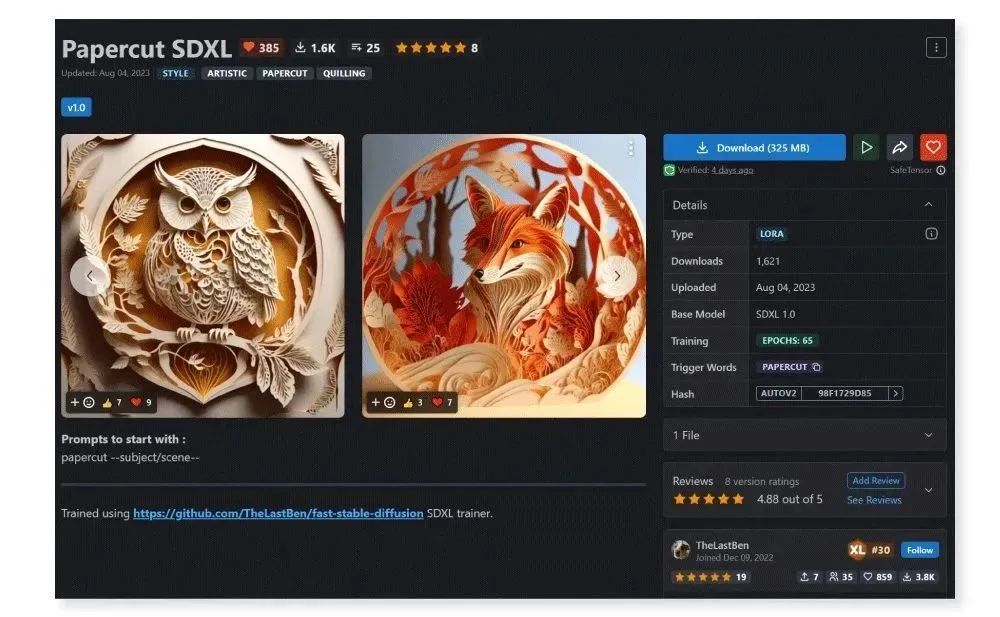
4.Papercut SDXL
一款基于 SDXL 1.0 训练的剪纸风 lora 模型,可以通过简单的提示词生成各种内容的多层剪纸插画,内容清晰准确,适合生成海报素材。
-
类型:lora 模型(安装路径:根目录 models\Lora )
-
注意事项:显存小于或低于 8G 时,需要开启显存要优化
-
图像尺寸不低于 768*768px
参考数值:
-
正向提示词:papercut of a fox in a forest, papercut, fox, forest,
-
负向提示词:blurry, boken
-
基础模型:sd_xl_base_1.0
-
lora 模型:papercut
-
生成步数: 25
-
尺寸:1024*1024px
-
采样器: DPM++ SDE
-
CFG scale: 7
5.3D Render Style XL
基于 SDXL 1.0 训练的 3D 渲染风格模型,图像质量很高,类似 Pixar 3D 动画的风格,适合用来生成各种 3D 人物、动物及场景。
-
类型:lora 模型(安装路径:根目录 models\Lora )
-
注意事项:显存小于或低于 8G 时,需要开启显存要优化
图像尺寸不低于 768*768px;不要开启高清修复
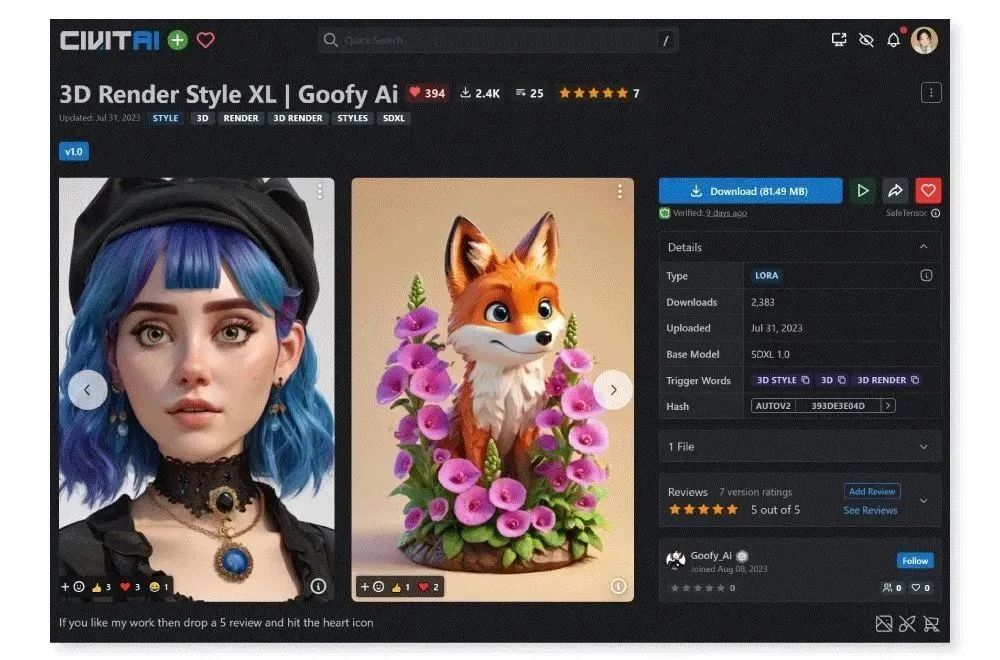
参考数值:
-
正向提示词:(masterpiece, best_quality, ultra-detailed:1.3), a cute Fox, 3d render ,
负向提示词:Negative prompt: (worst quality, low quality:1.4), (lip, nose, tooth,
rouge, lipstick, eyeshadow:1.4), (blush:1.2), (jpeg artifacts:1.4), (depth of
field, bokeh, blurry, film grain, chromatic aberration, lens flare:1.0),
(1boy, abs, muscular, rib:1.0), greyscale, monochrome, dusty sunbeams,
trembling, motion lines, motion blur, emphasis lines, text, title, logo,
signature,bad_hands, bad-artist-anime -
基础模型:sd_xl_base_1.0 / Clip skip: 2
-
lora 模型:3d_render_style_xl(权重 0.7-1)
-
生成步数:30
-
采样器:Sampler: DPM++
-
生成尺寸:768x1024 px
-
CFG scale: 7
6.3D Render Style XL
很少会见到针对UI领域特化的SD大模型,Microsoft Design SDXL是国人针对3D UI图标专门训练的模型,偏微软风格,弥散的色彩。
虽然整体风格泛化能力目前较为单一,但是出图质量较高,且填补了这个领域的空白。依然推荐。

7.LEOSAM’s HelloWorld 新世界 SDXL
“HelloWorld”一个全新的逼真的SDXL基础模型系列,拥有极高的肖像的真实感和电影般的质量。用作者的原话说就是:
“由于SDXL的信息量和文本理解能力远远优于SD1.5,HelloWorld是一个旨在逼真描绘所有事物的基本模型,或者换句话说,我希望使用HelloWorld逐步构建一个虚拟摄影世界”
需要在prompt上写上“leogirl”进行模型触发 。


8.SDXL_Niji_Special Edition
相比Niji5,有过之而无不及,SD生态里表现最好的卡通大模型,精通所有卡通风格,你的每一个创意,都能在SDXL_Niji_Special
Edition的世界里找到最完美的表达。

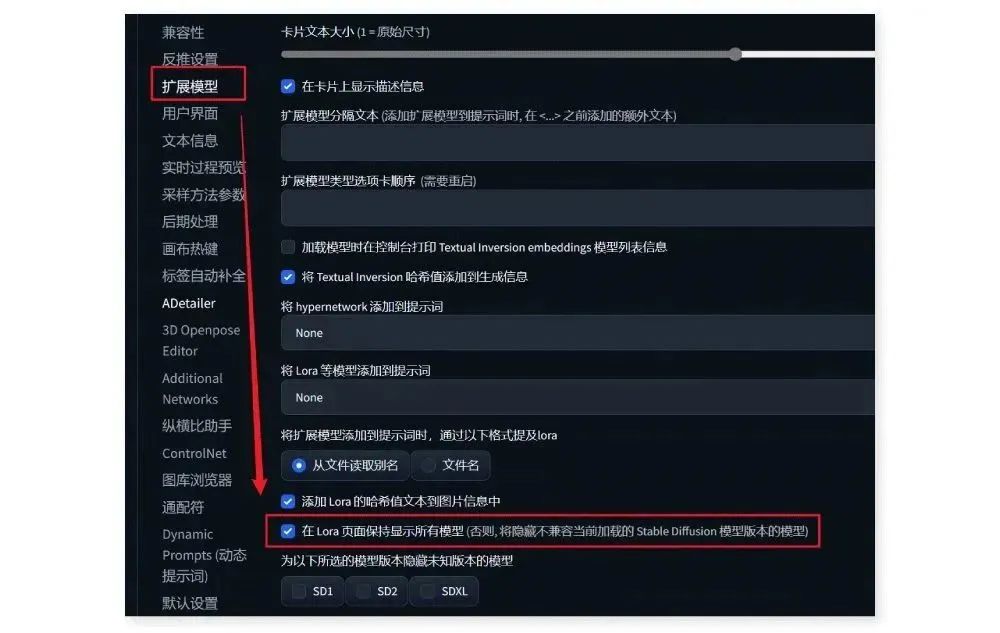
如果在调用 lora 的过程中发现拓展框内没有下载好的 lora 模型,可以进入“设置-拓展模型”中,勾选最下方的“在 Lora
页面保持显示所有模型”,保存设置后重启 WebUI,就能看到所需的 SDXL lora 模型了。
以上就是本期为大家推荐 5 款基于 SDXL1.0 训练的大模型,可以让我们生成质量更高的图像。虽然目前 SDXL
系的模型在插件兼容性上差一些,但未来配套的设置肯定会越来越完善,非常值得期待。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!

零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 2499
2499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









