






以前拍专业的人像照片,都是拿着个沉重的单反相机和众多镜头,耗时耗力。现在有了AI,随时随地分分钟可以“计算”出专业级的真人摄影照片。该怎么做呢?
比如,我们想生成一张真人摄影照片,内容是:一个年轻时尚漂亮的女孩,站在路上,背景是一排金黄色的银杏树。
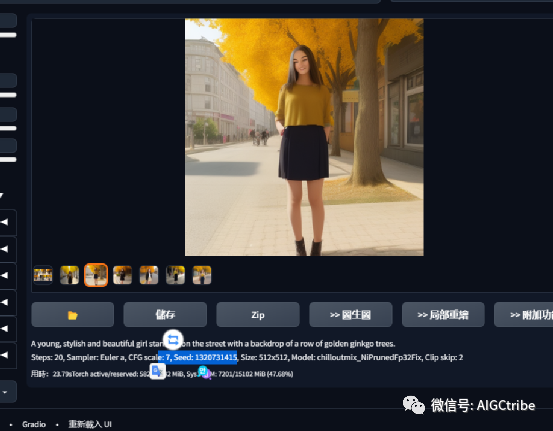
翻译成英文就是:A young, stylish and beautiful girl standing on the street with a backdrop of a row of golden ginkgo trees.输入到Stable Diffusion的提示词框中,生成下面价格照片

这里存在两个问题,一是像画画,不像摄影;二是人物脸部有些扭曲。
我们可以先选择一张比较满意的风格,比如第2张。
复制底部的Seed值,随机种子里面填入这个值,然后点击底部的:图生图按钮
在提示词里面加入一些摄影相关关键词:Phtography,HDR RAW photo, 8K, highres,absurdres ,Kodak Portra 400 , film grain 等,还可以根据自己需求加一些特定关键词:Bokeh,lens flare,vibrant color等,这样就会让图片像相机拍摄出来的一样。
然后加入一些反向提示词: (worst quality:2) ,(low quality:2), (normalquality:2), lowres, normal quality ((monochrome)), )(grayscale )), skin spots,veins, acnes ,skin blemishes, age spot,glan,extra fingers,fewer fingers, strange fingers, bad hand, bad anatomy, fused fingers, missing leg, mutated hand, malformed limbs, missing feet,(toe:1.5),(sandals:1.5),(curtain), skin spots
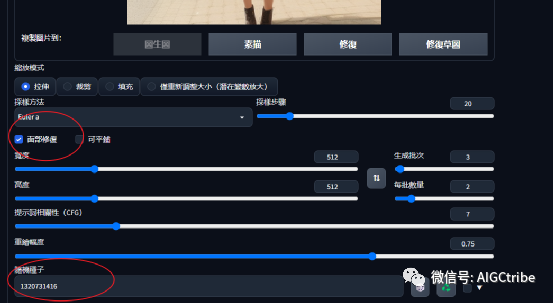
面部修复这个选项打√,这样有助于生成更好的人像面部。下面是生成的结果:

效果好多了,但是脸部还是有问题,
选其中比较满意的第二张照片,复制 Seed: 1320731417,随机种子里面填入这个值。
然后在正面提示词里面加入:(detailed eyes and skin)
负面提示词里面加入:(unclear faces:1.331),(unclear eyes:1.331),(disfigured:1.331),(ugly:1.331),(bad proportions:1.331),bad face
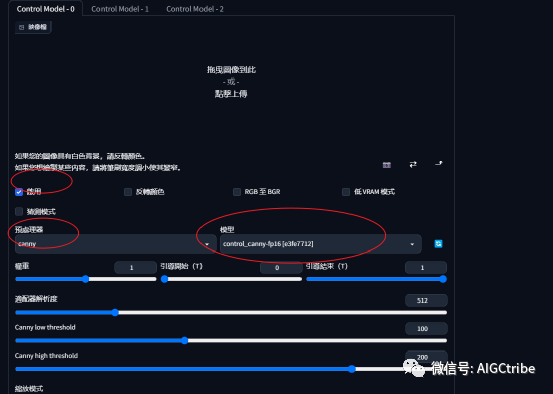
启用controlnet,预处理器和模型都选择canny,这样可以帮我们固定住人像、背景,在生成图片的时候,不会有大的变动。再次生成,结果如下: 
已经不错了,但是还不很满意。
我们可以保存刚才的提示词,切换到文生图按钮,再次生成图片,挑选出满意的: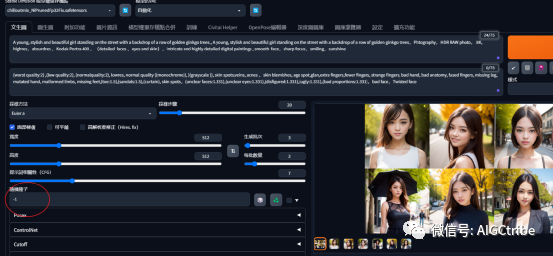
记得随机种子,这里改成-1.如果不满意,就再次生成,直到产生满意的图片。

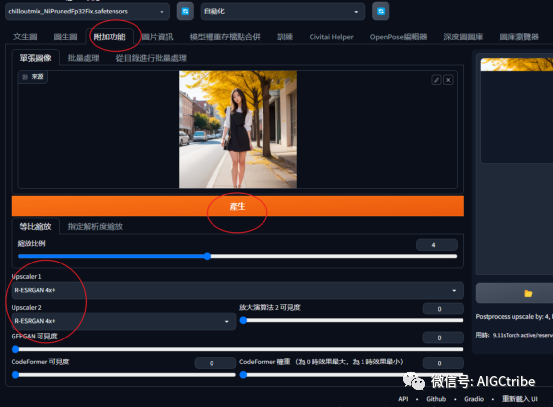
这次除了打伞的那张有些怪异,其他都很不错。然后发生图片到附加功能,将图片进行无损放大,生成更丰富的细节。OK,“拍摄”完成!
文章使用的AI工具SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,无需自行查找,有需要的小伙伴文末扫码自行获取。
写在最后
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除















 504
504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









