






前几天我搭建了一个基于RAGflow构建了一个知识库系统,分享给大家!
首先我们来了解一下什么是ragflow?
RAGFlow 是一个结合了RAG(Retrieval-Augmented Generation,检索增强生成)和 自动化工作流(Workflow)的智能知识库管理工具。它通过整合多源数据、自动化处理流程和智能生成能力,帮助用户高效构建和管理知识库。
系统架构图:
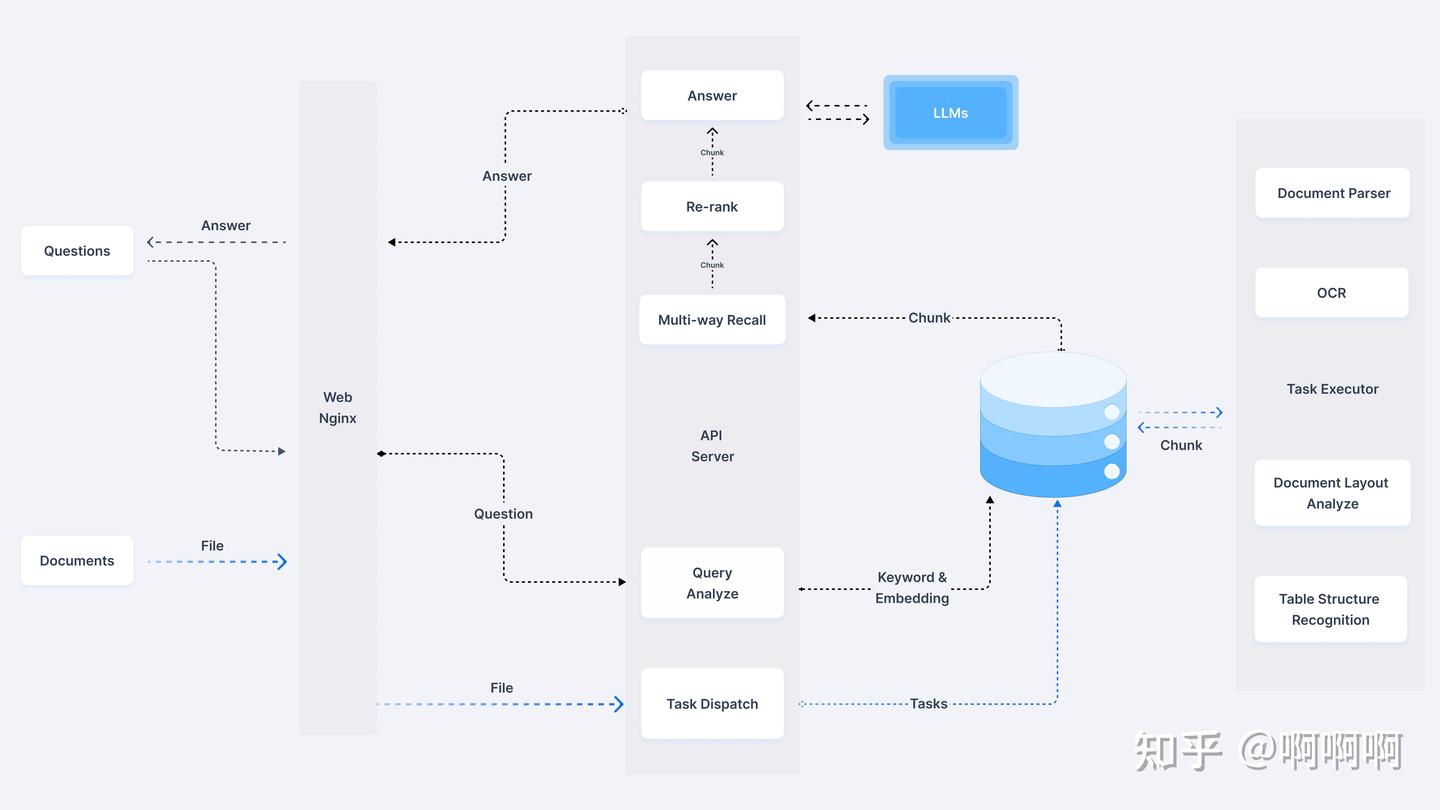
简单说就是一个智能资料库管家,能干三件事:
1.帮你把乱七八糟的文件(Word、PDF、表格、图片甚至语音)自动整理成知识库
2.像真人一样“理解”问题,从资料里找答案(比如你问“请假流程要几步?”,它直接告诉你步骤,而不是甩给你一堆文件)
3.自动更新资料(比如上传新文件后,不用手动调整,它自己就学进去了)
用这玩意儿做知识库,打工人能爽在哪?
- 不用当“人肉扫描仪”了
以前:手动整理合同、扫描件、表格,复制粘贴到知识库,眼睛都看瞎。
现在:直接把文件丢给它,自动识别文字、表格、图片里的内容(连潦草的手写签名都能OCR识别)。 - 找资料像问同事一样自然
以前:在知识库里搜关键词,结果要么漏了,要么出来一堆无关内容。
现在:直接问:“去年华东区销售额最高的产品是啥?” 它先翻财报表格,再读会议记录,最后用大白话告诉你答案。 - 客服不用背手册了
以前:客户问“订单延迟怎么办?”,客服得翻10个文档找退货政策、物流流程、补偿规则…
现在:RAGFlow自动从手册、邮件、公告里提取信息,生成直接能用的回复话术:“您好,您的订单预计延迟3天,可联系xxx申请运费补偿(依据《2023售后政策》第5条)”。 - 资料安全又省心
权限控制:比如销售部只能看产品资料,财务部才能看报表。
自动更新:上传新版本合同后,旧版本自动存档,不用怕用错文件。 - 连老板都能用
老板问:“把最近3个月的市场分析报告总结成500字”,它5秒钟就能从20份PPT里抓重点,生成:“Q2市场增长主要来自…(数据源自6月5日《华东市场报告》第8页)”
一句话总结:
如果你受够了传统知识库的“搜不到、看不懂、管不动”,RAGFlow就像个24小时上班的AI图书管理员+学霸助理,把死文件变成活知识。
如何搭建
前提条件
- CPU >= 4 核
- RAM >= 16 GB
- Disk >= 50 GB
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
| 如果你并没有在本机安装 Docker(Windows、Mac,或者 Linux), 可以参考文档 Install Docker Engine 自行安装。 |
|---|
一、下载RagFlow
1.github地址:https://github.com/infiniflow/ragflow?tab=readme-ov-file
2.下载以后进行解压
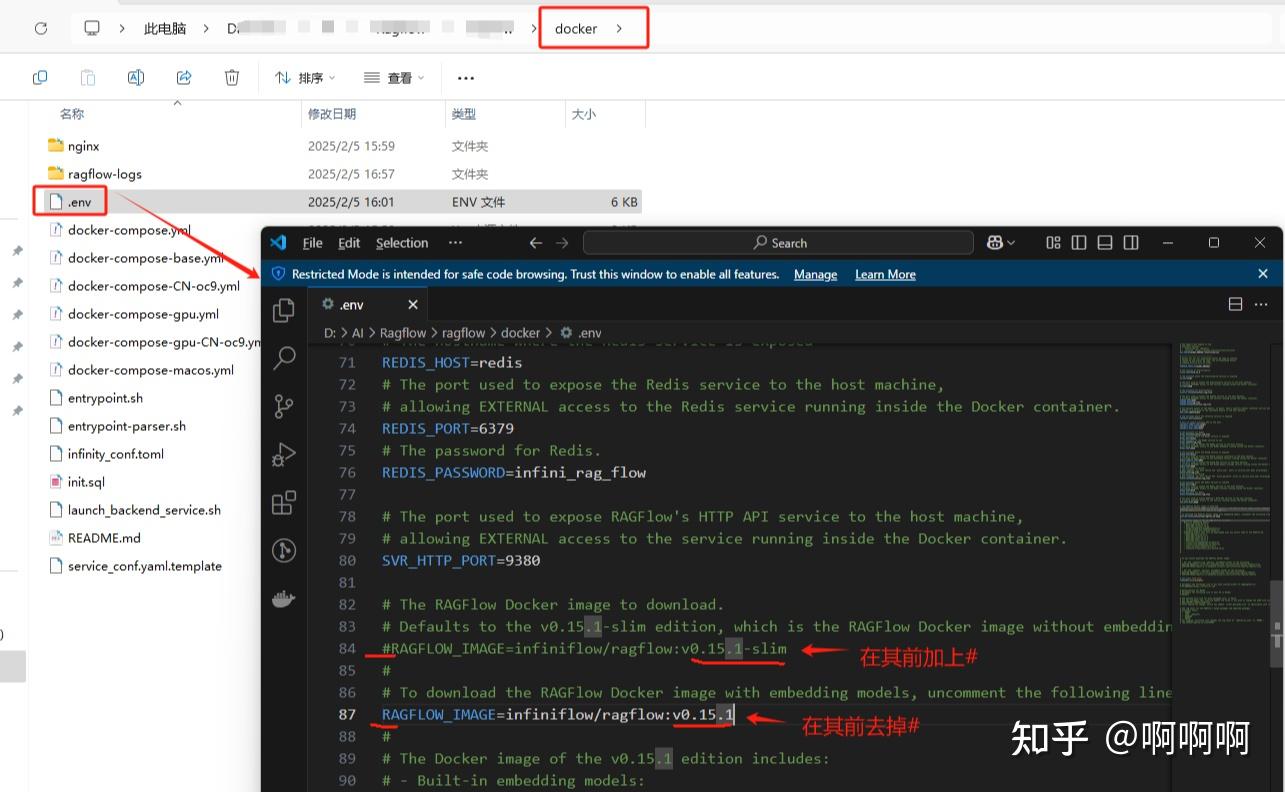
在ragflow\docker.env 文件按如下图修改
启动RAGFlow Docker
按windows+r 打开终端程序,
cd ragflow 路径
启动RAGFlow Docker
docker compose -f docker/docker-compose.yml up -d
输入之后 按回车键,如果有错误则是网络问题,检查Docker镜像配置地址。
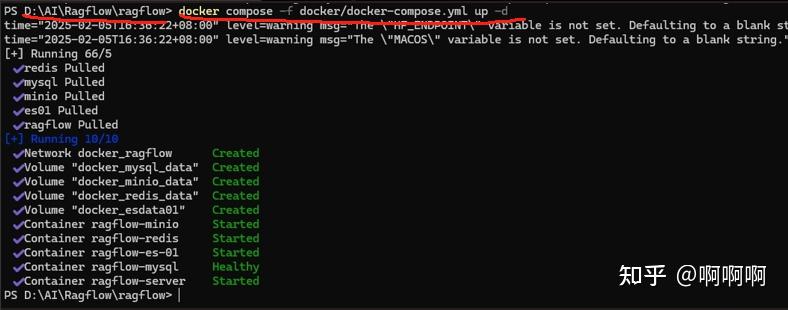
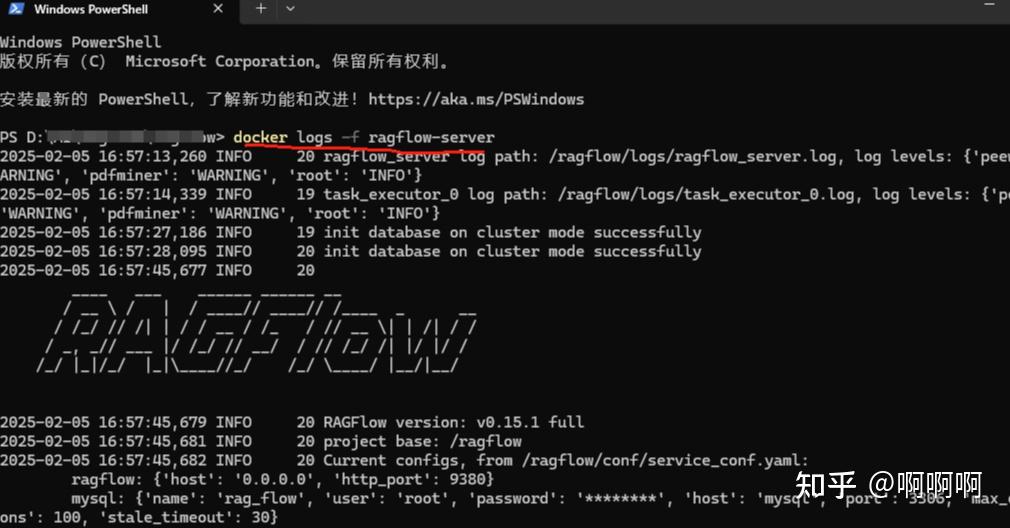
完成后输入docker logs -f ragflow-server
如果看到如下信息 则启动成功:
二、Ollama安装
第一步:直奔 ollama 官网:https://ollama.com/,根据电脑系统下载对应版本。
第二步:安装 ollama,下载完后,一路 “下一步” 就搞定安装,轻松加愉快 。
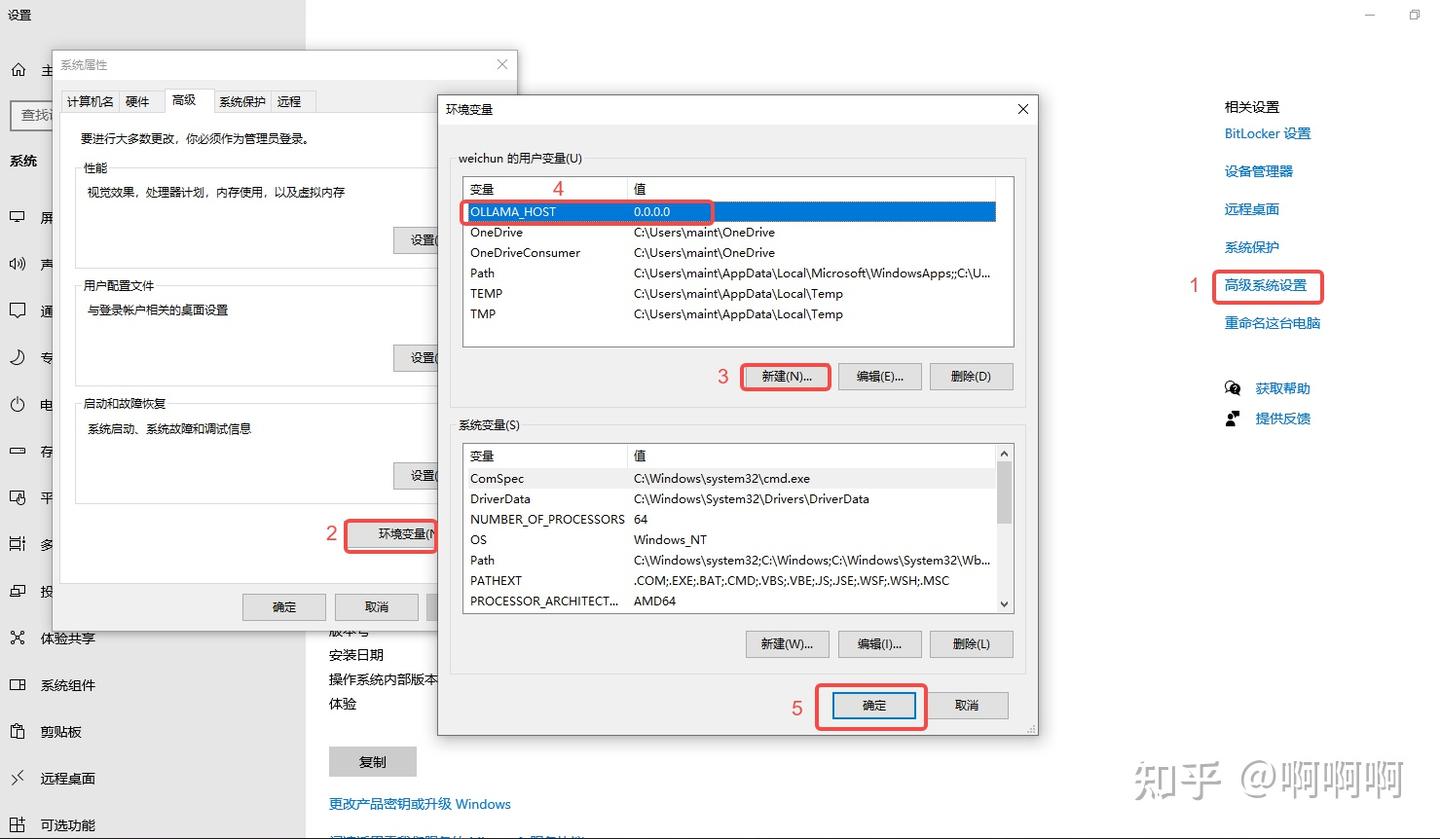
第三步:配置环境变量,打开电脑设置-系统-关于,点击【高级系统设置】,按照下图进行配置:
第四步:安装大模型并运行
快捷键:win+r,打开命令窗口,安装deepseek r1模型,输入命令:
| Plain Textollama pull deepseek-r1:32b |
|---|
下载嵌入模型,主要做文本切片使用的
| Pythonollama pull nomic-embed-text |
|---|
需要下载很久,耐心等待即可。
安装完成之后,要查看是否安装成功,执行命令:
三、Docker安装
1.从官网下载docker安装包,地址:https://www.docker.com/products/docker-desktop/,根据你的系统选择对应的版本进行下载。
2.打开docker软件,点击设置,点击docker引擎,配置下载镜像:
因网络问题,国外docker镜像 无法拉取,需在Docker做些相关配置才可以。
打开安装好的Docker应用程序,如下图双击Docker Desktop
打开Docker 应用时 不需要注册,直接跳过。
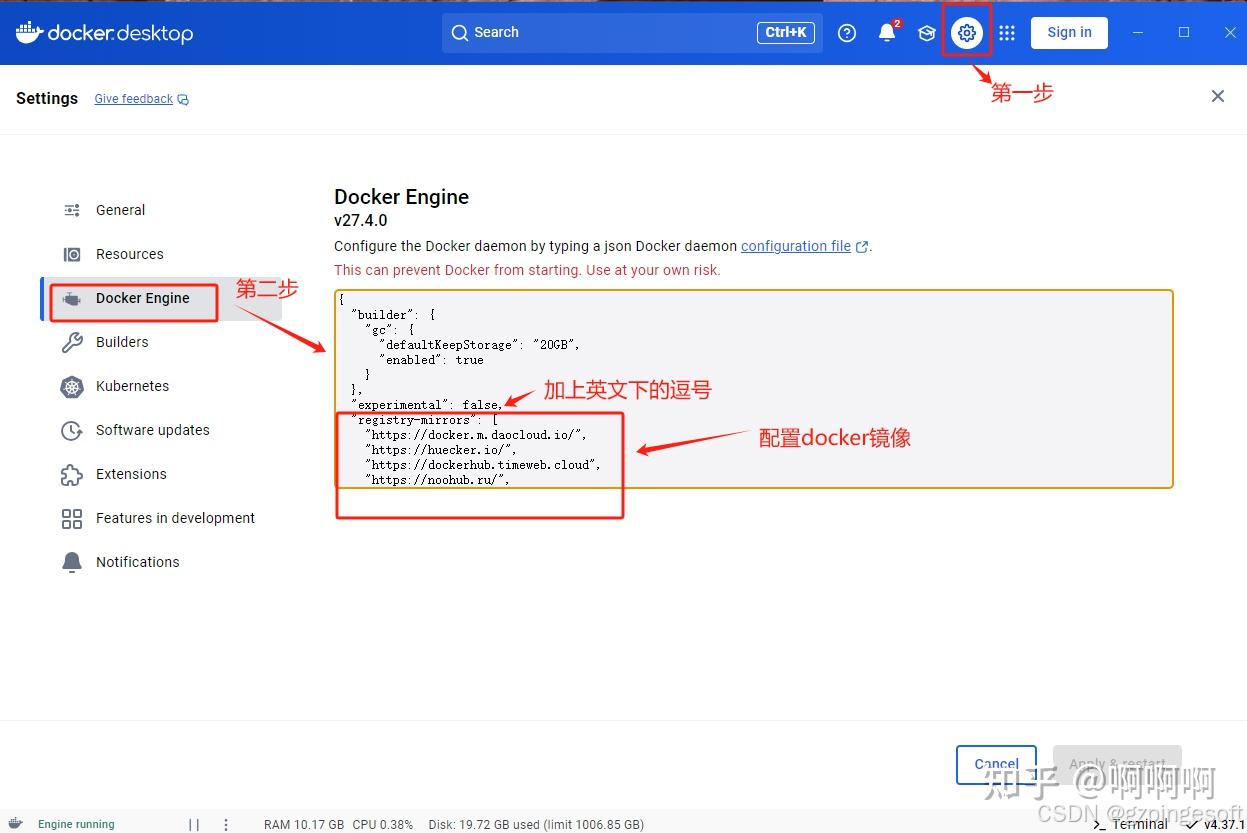
在 “experimental”: false, 后加上如下Docker镜像地址,建议直接复制
“registry-mirrors”: [
“https://docker.m.daocloud.io/”,
“https://dockerhub.timeweb.cloud”,
“https://docker.mirrors.ustc.edu.cn”,
“https://xx4bwyg2.mirror.aliyuncs.com”,
“http://f1361db2.m.daocloud.io”,
“https://registry.docker-cn.com”,
]
配置修改后,点击 Apply&restart 保存并重启Docker
四、使用ragflow创建知识库
1.打开浏览器,输入地址:http://localhost/knowledge,回车。
2.点击注册按钮进行注册,填写完信息后,点击继续按钮。
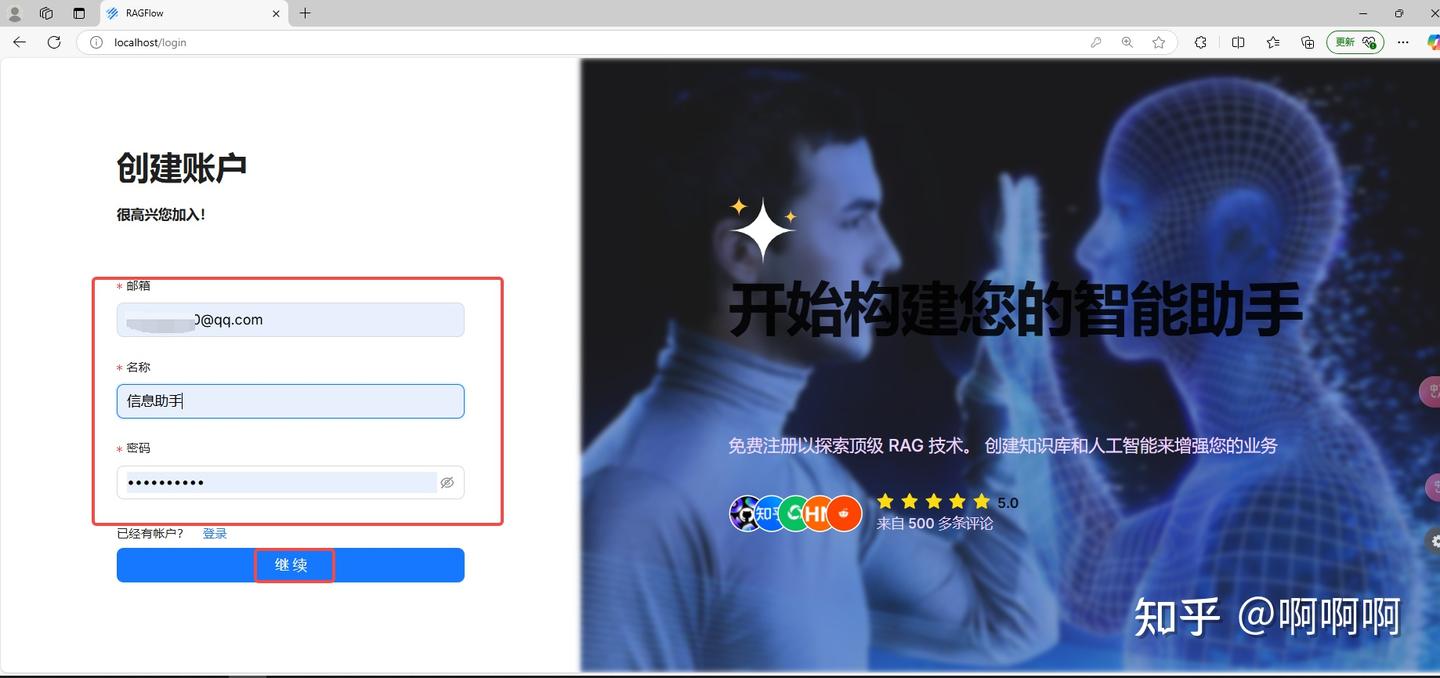
3.注册完后进行登录。
4.模型提供商
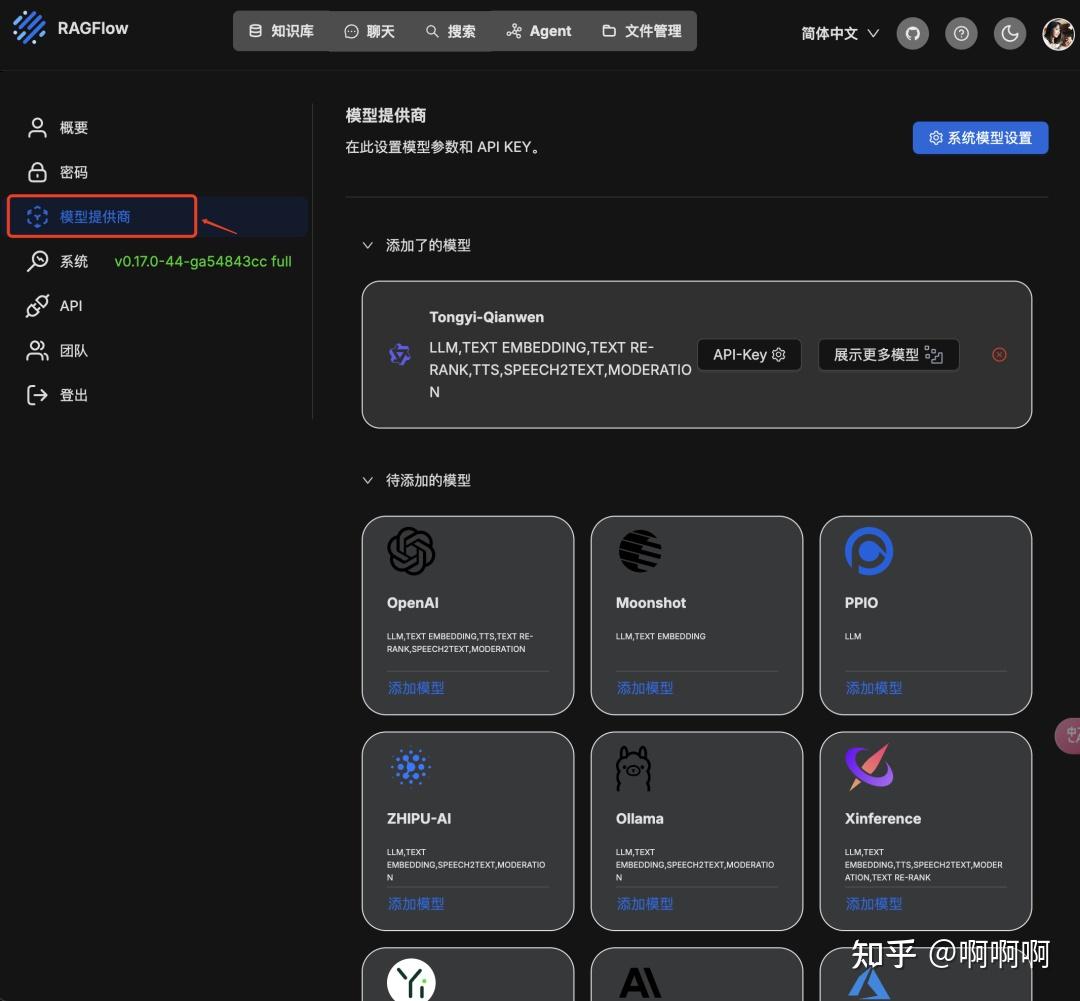
这个地方配置比较重要,我们需要利用Ollama框架添加两个需要的大模型:聊天模型DeepSeek和 embedding(嵌入向量) 模型nomic-embed-text。
5.本地Ollama 配置
Ollama 是一个轻量级的本地大模型运行框架,在设计上支持多种模型架构。他本身也是一个大语言模型。Ollama 由 Go 语言开发,利用 Go 语言高效的并发处理能力进行模型管理,能较好地调度系统资源
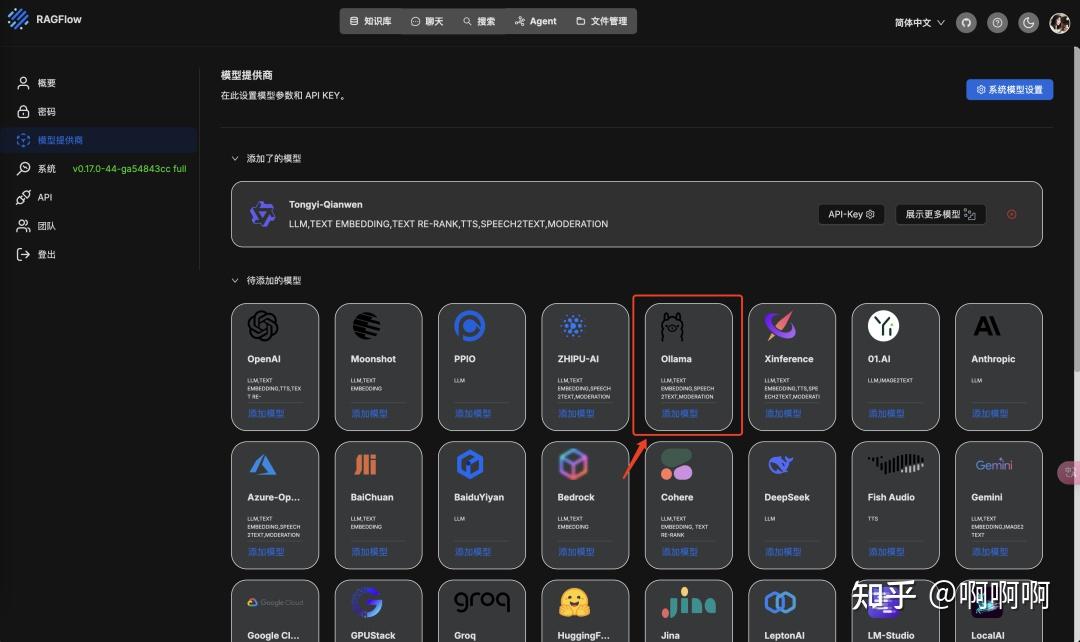
打开docker desktop 工具,点击终端输入ollama list就可以查询本地安装的所有模型。
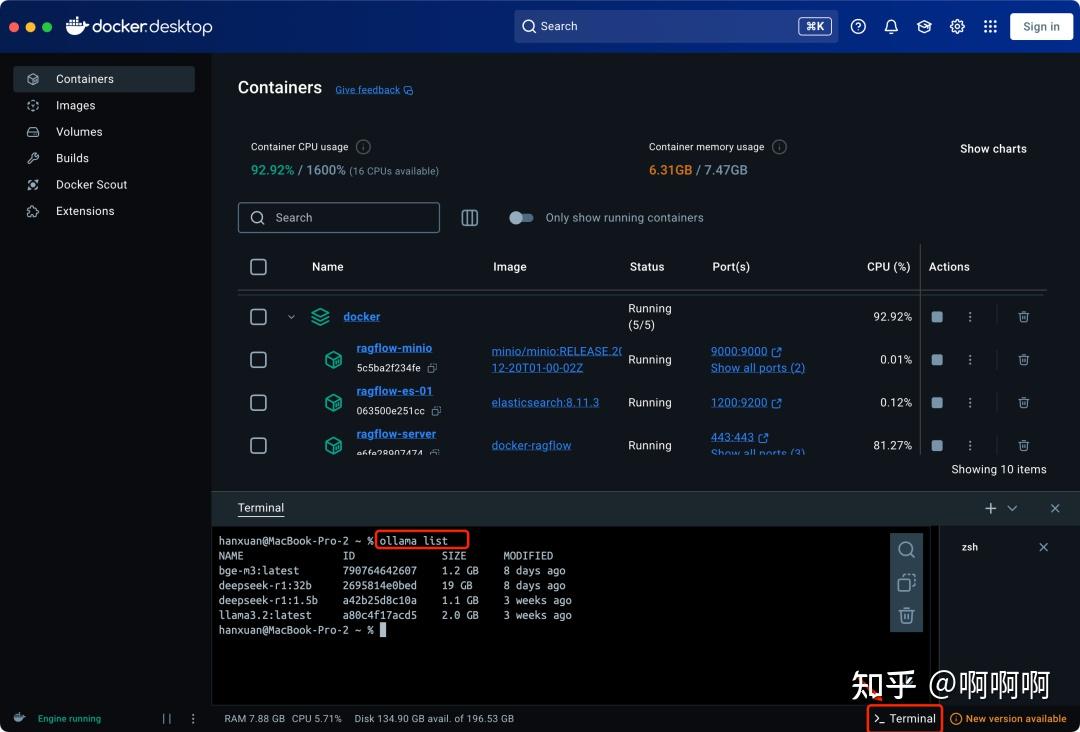
6.配置DeepSeek模型
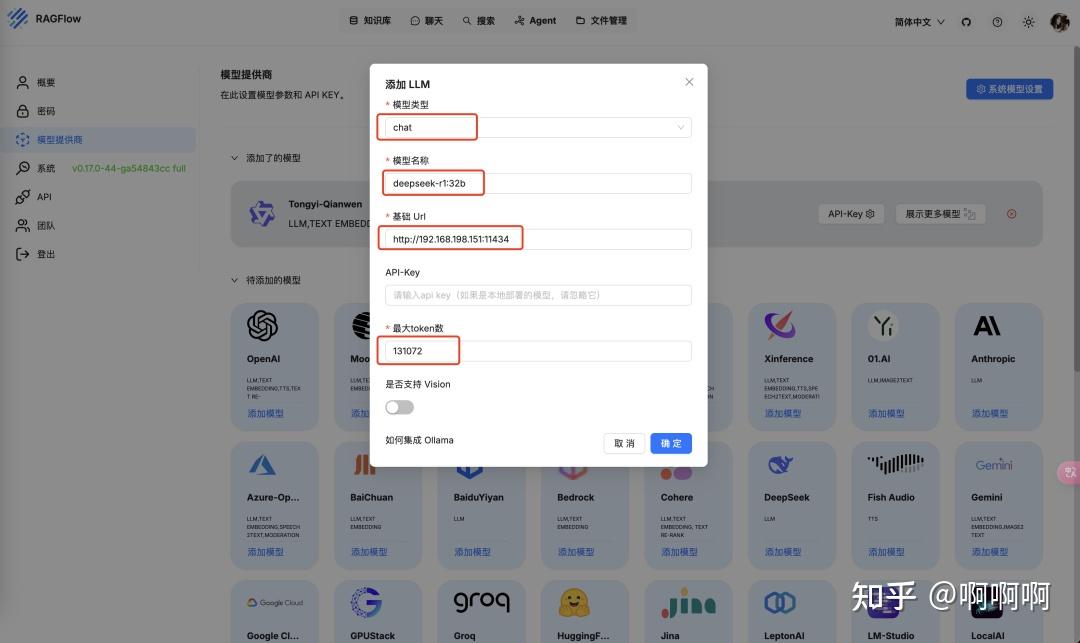
- 模型类型: chat
- 模型名称: deepseek-r1:32b
- 基础 Url: 模型所在的主机IP:11434
- 最大token数:131072
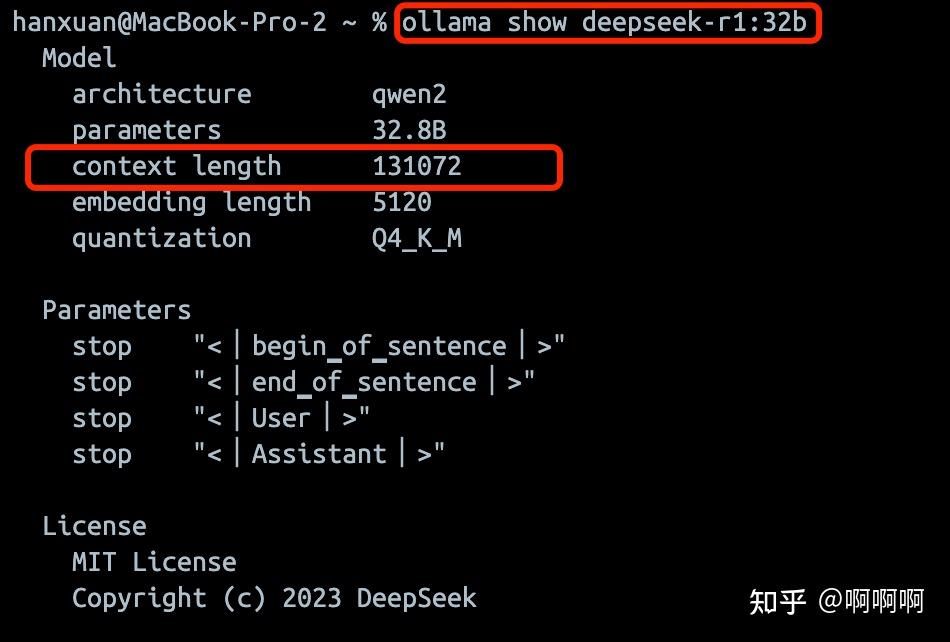
使用ollama show [模型名称]就可以查询模型的详细信息,包含最大token数。
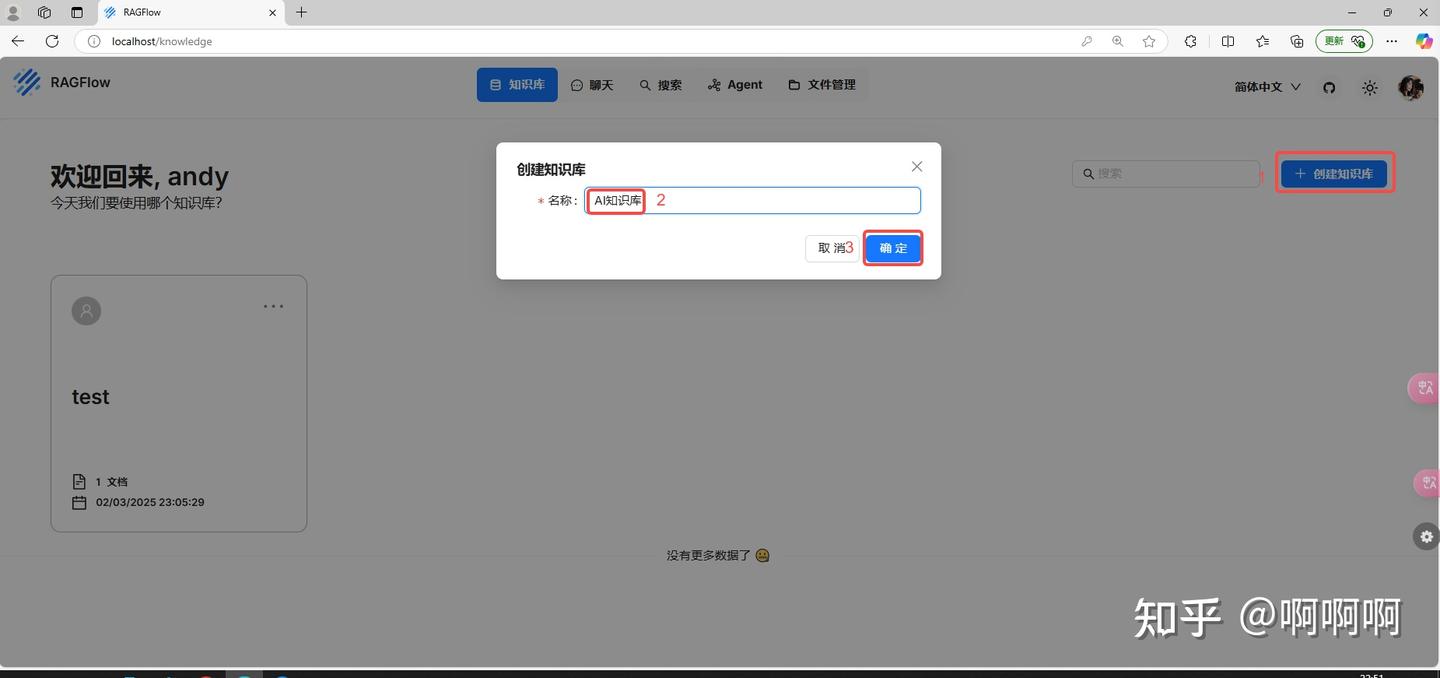
7.创建知识库
8.知识库配置
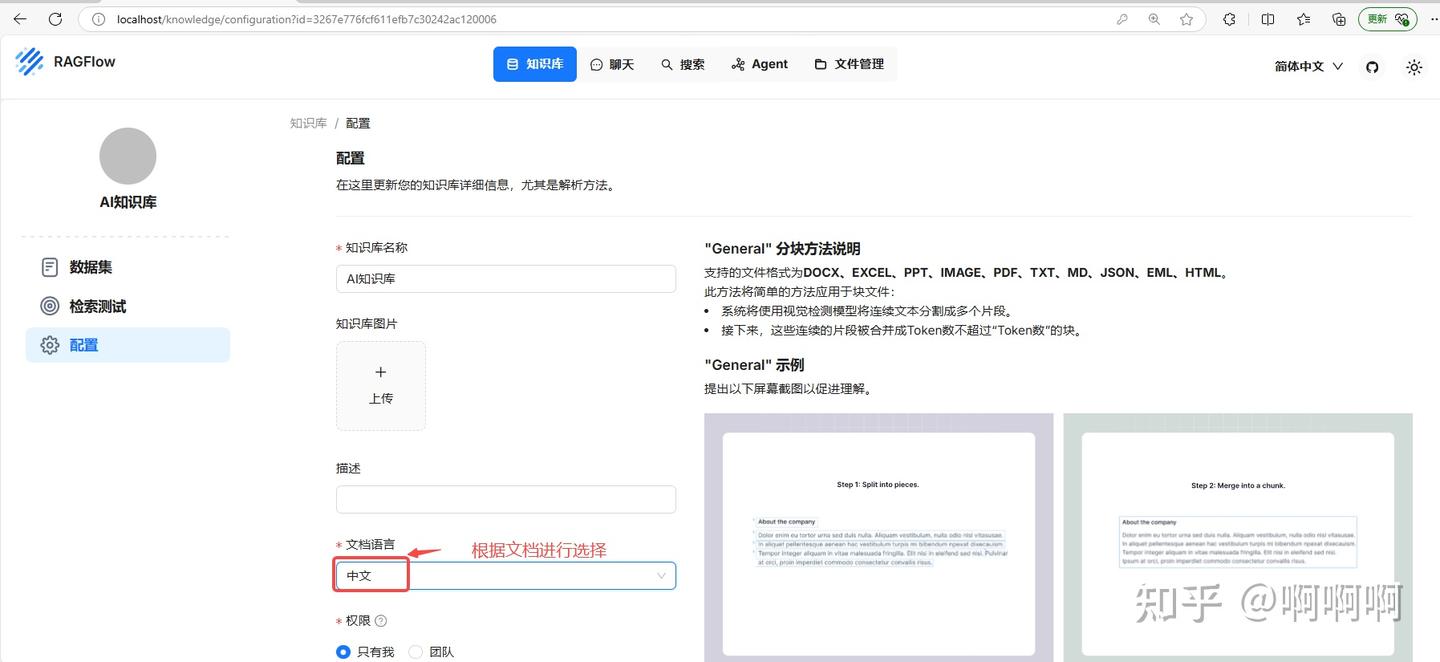
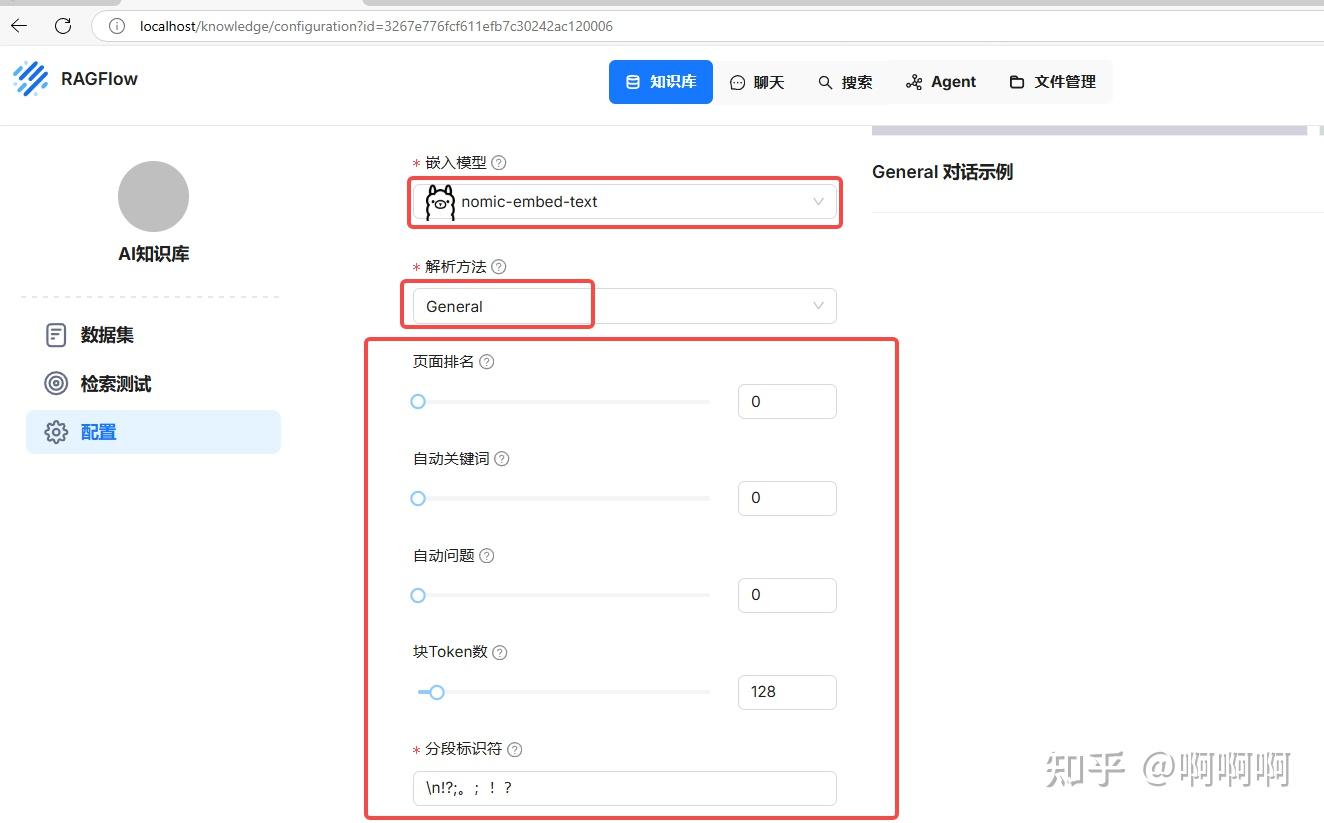
9.配置嵌入模型和解析方法:word和pdf一般用General方法,其它默认即可,然后保存。
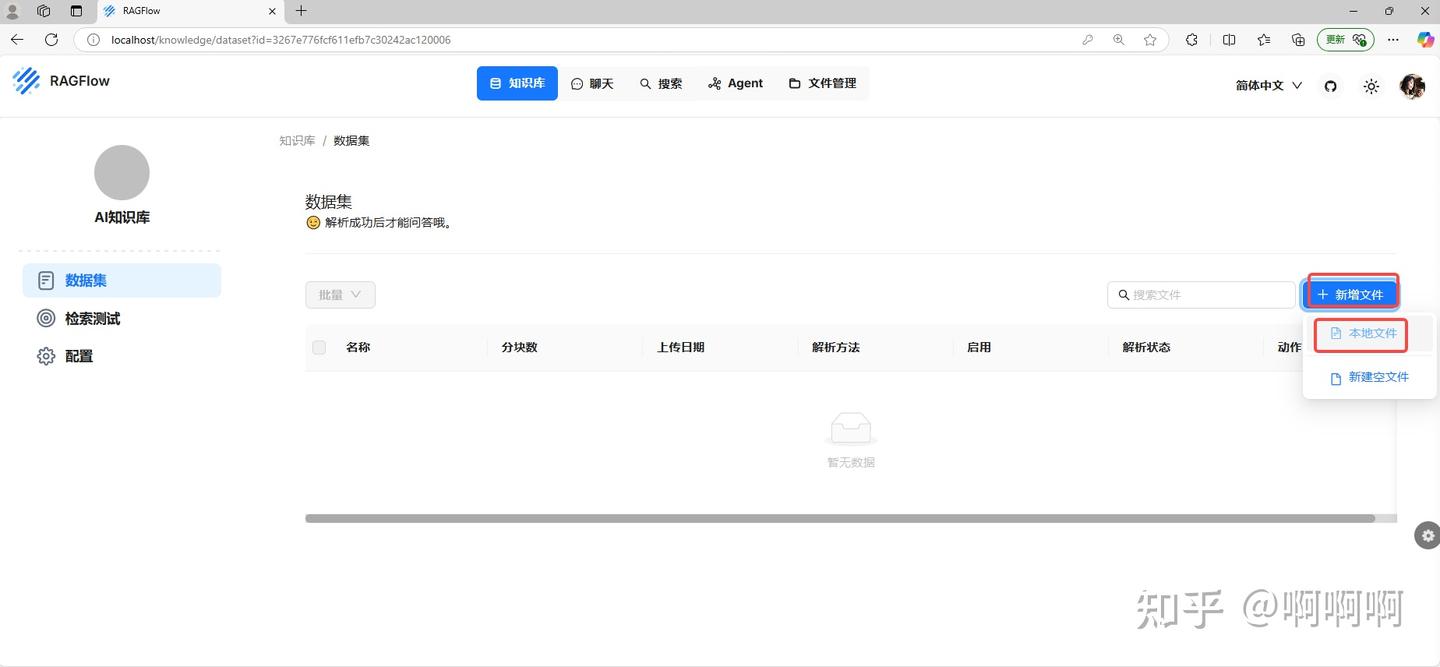
10.新增本地文件
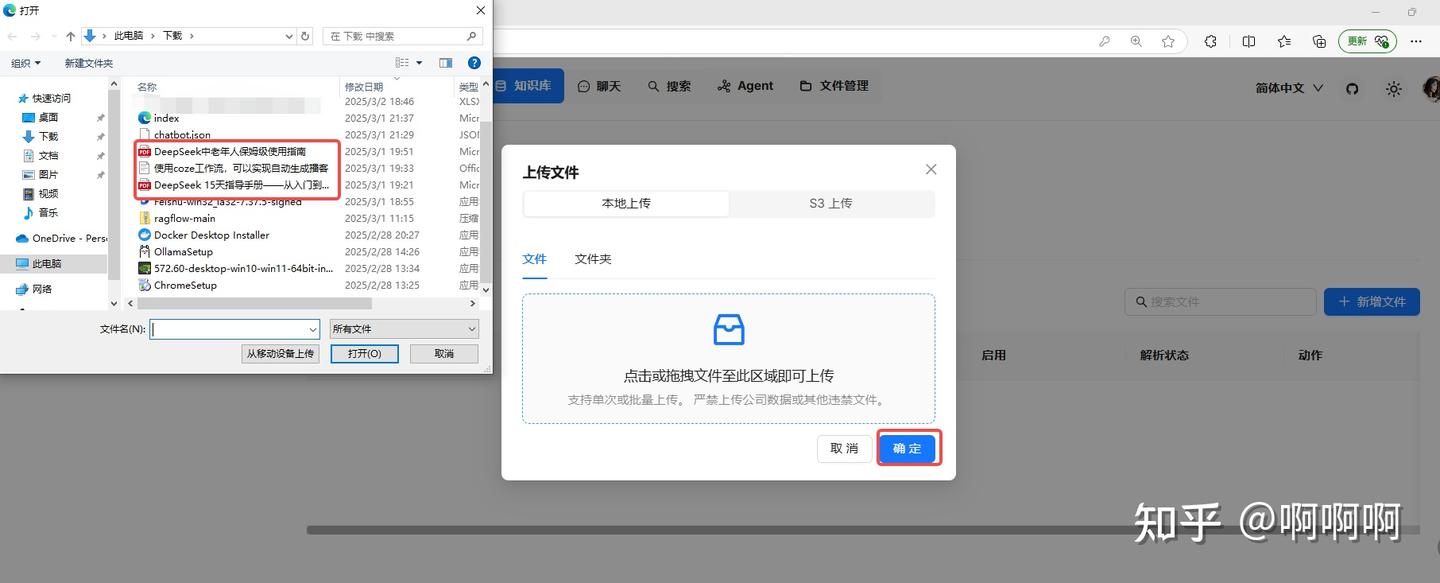
11.同时上传三个文件
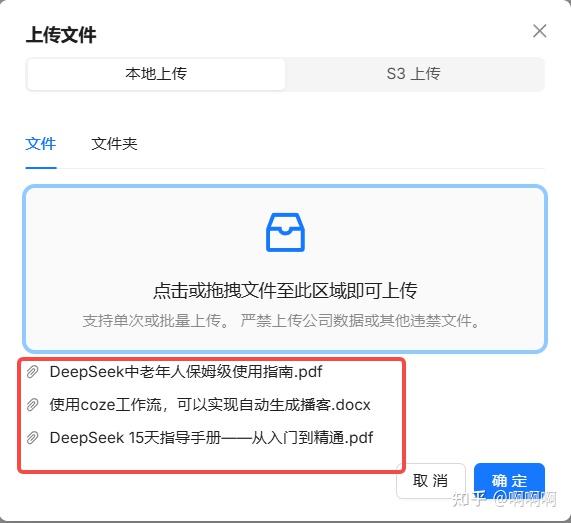
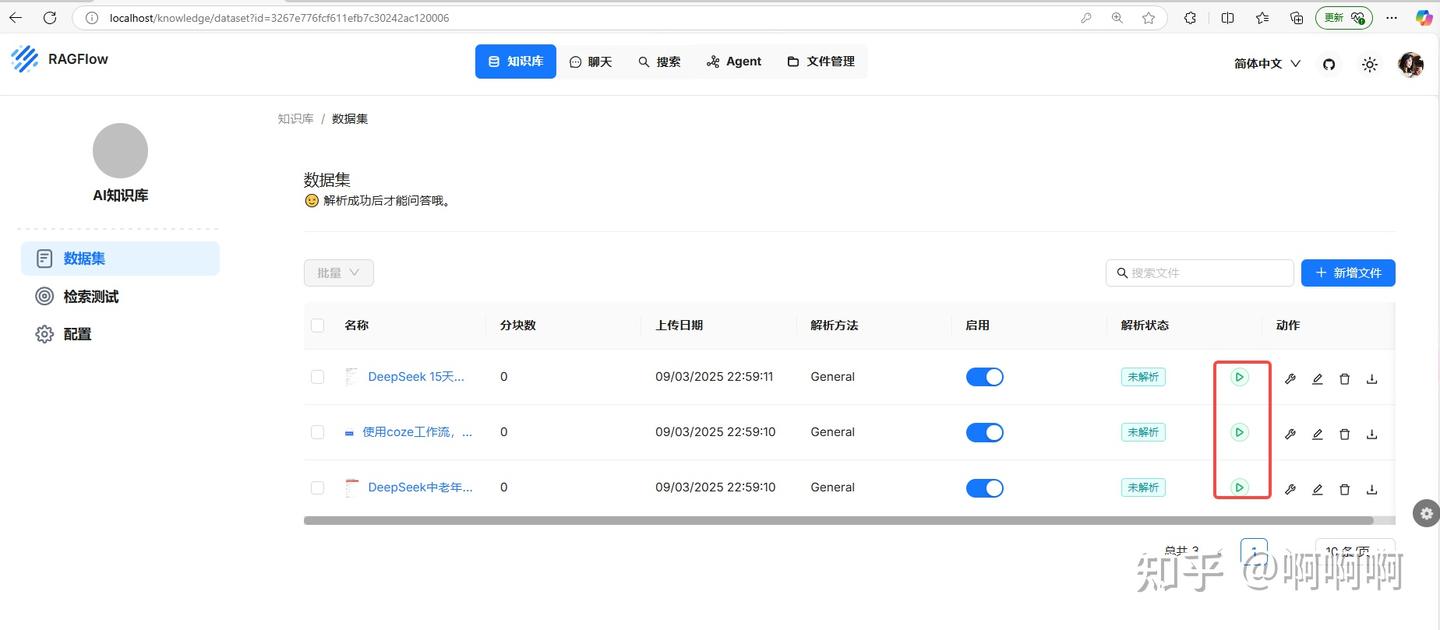
12.点击按钮进行解析文档,将文档通过嵌入模型分片保存到数据库中
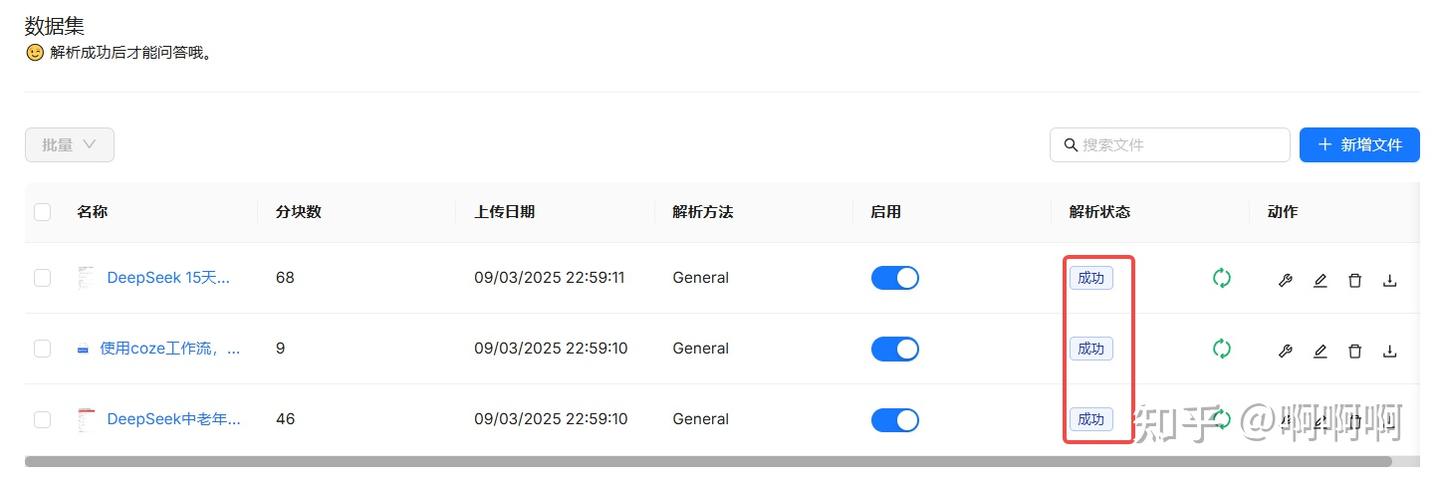
13.解析成功!
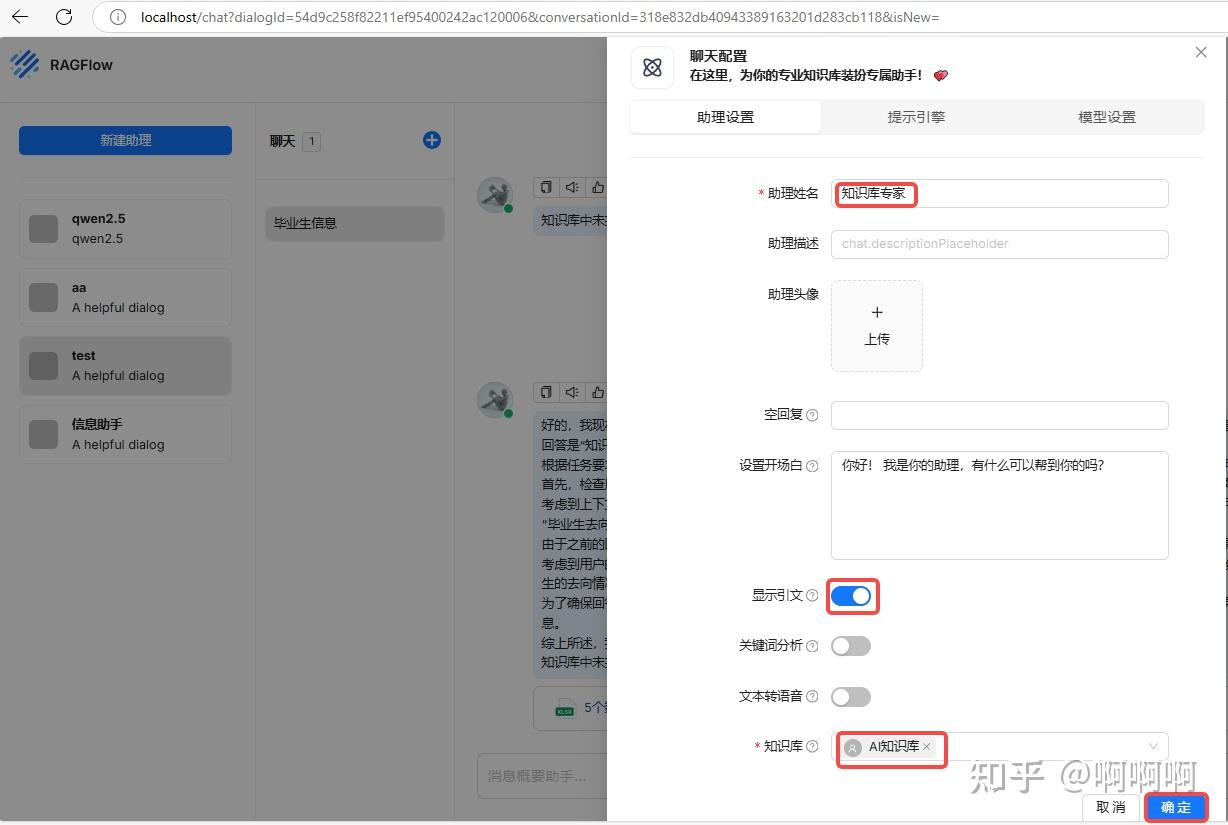
五、配置聊天助手
1.点击“聊天”菜单,进入聊天页面,然后点击新建助理按钮,进行聊天配置
2.提示引擎配置,如下:
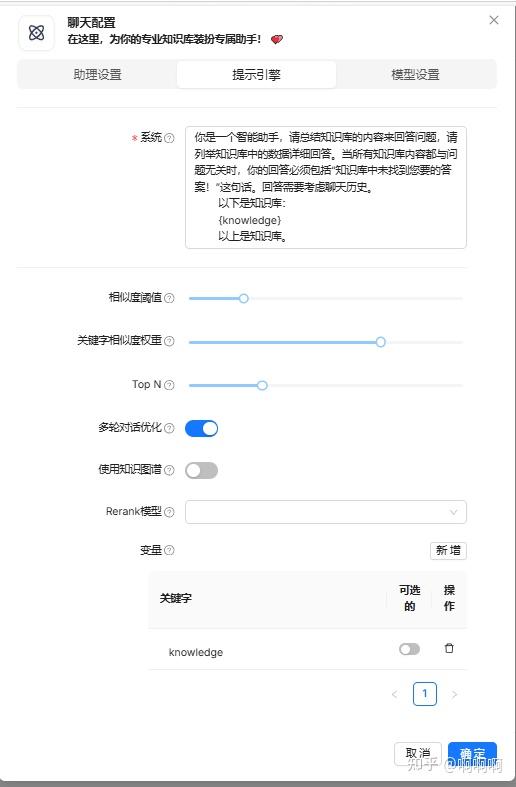
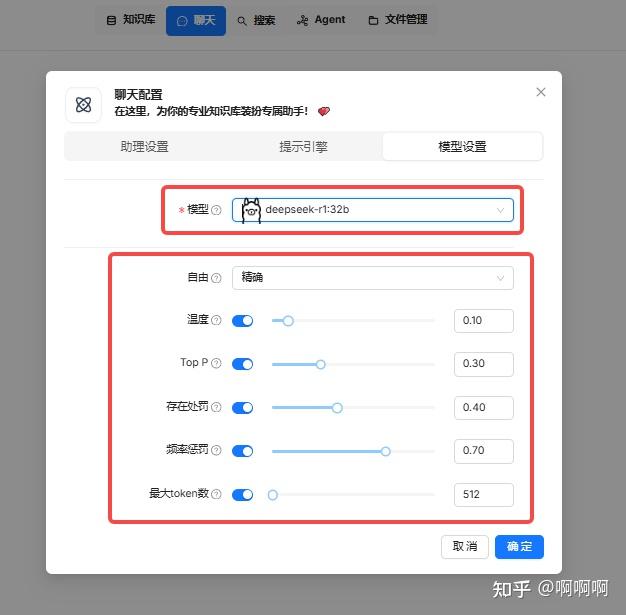
3.模型设置
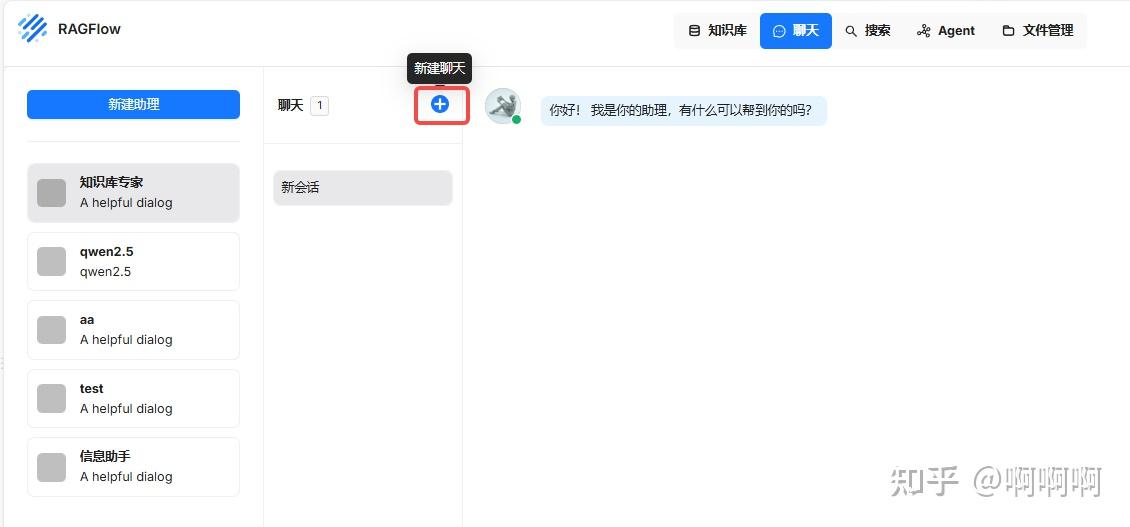
4.点击新建聊天
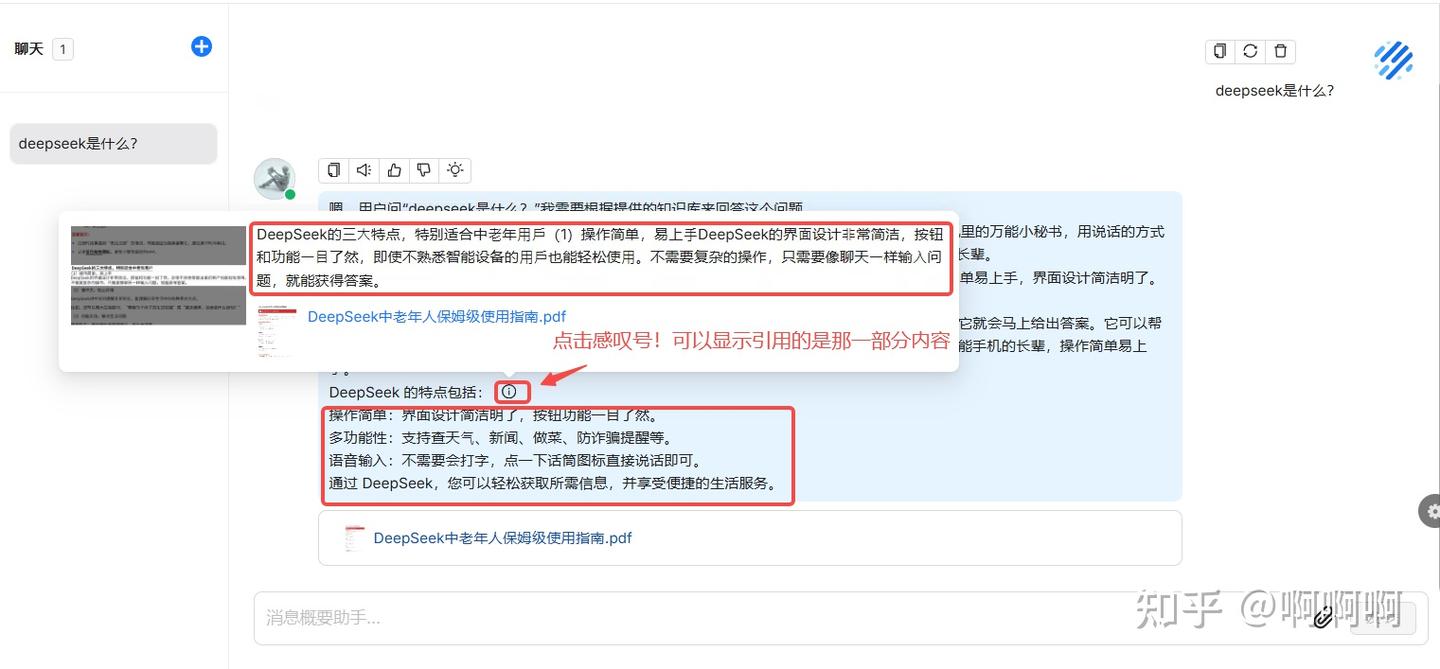
5.进行聊天问答,deepseek是什么?他进行了回答,同时引用我的知识库问答内容。
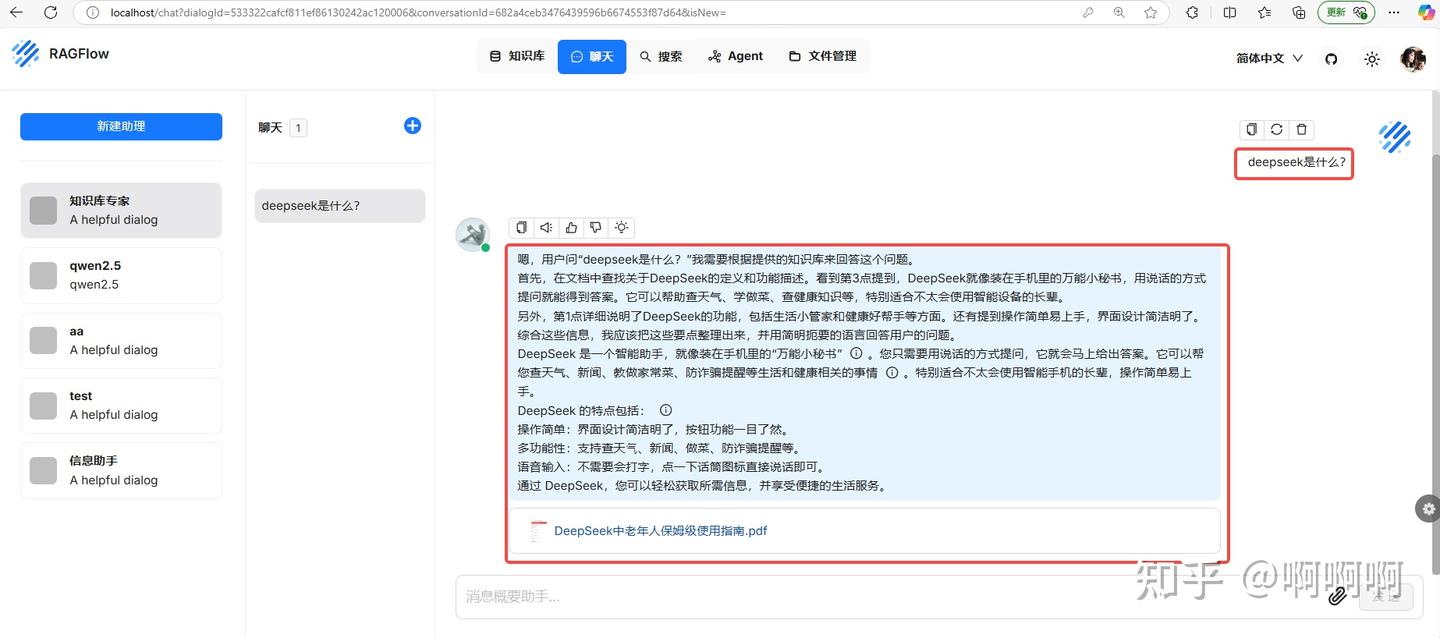
引用内容溯源:
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









